تقاضای جستجو پیش از ظهور کلمات کلیدی شکل میگیرد. ببینید چگونه Exploding Topics، جستجوی اجتماعی و روابط عمومی، ساختن اعتبار اولیه را پشتیبانی میکنند.
اکتشاف اکنون قبل از اینکه تقاضای جستجو در گوگل نمایان شود، رخ میدهد.
در سال ۲۰۲۶، علاقهمندی در فیدهای اجتماعی، جامعهها و پاسخهای تولید شده توسط هوش مصنوعی شکل میگیرد – خیلی پیش از اینکه بهعنوان حجم جستجوی کلمه کلیدی ظاهر شود.
تا زمانی که تقاضا در ابزارهای سئو ظاهر شود، فرصت شکلدادن به درک یک مفهوم دیگر از دست رفته است.
این مسألهای برای روش معمول انجام تحقیقات بازاریابی جستجو ایجاد میکند.
ابزارهای کلمه کلیدی، حجم جستجو و Google Trends نشانگرهای تأخیری هستند.
آنها آنچه مردم دیروز به آن اهمیت میدادند را نشان میدهند، نه آنچه هماکنون در حال بررسی هستند.
در محیطی که مرورهای هوش مصنوعی، SERPهای اجتماعی و فضای ارگانیک در حال کاهش است، دیر رسیدن به معنای رقابت در چارچوب روایتهایی است که پیشاپیش توسط دیگران تعریف شدهاند.
Exploding Topics پیش از این تغییرات قرار دارد.
این ابزار به شناسایی موضوعات، رفتارها و گفتگوهای نوظهور کمک میکند در حالی که هنوز در حال شکلگیریاند – پیش از اینکه به کلمات کلیدی، خوشههای محتوا و دستهبندیهای محصول تبدیل شوند.
اگر بهدرستی استفاده شود، این فقط یک ابزار روند نیست؛ بلکه روشی برای برنامهریزی پیشدستانه سئو، محتوا، روابط عمومی دیجیتال و جستجوی مبتنی بر اجتماعی است.
این مقاله نحوه استفاده از Exploding Topics برای شناسایی موجودیتهای آینده، اعتبارسنجی آنها از طریق جستجوی اجتماعی، و ایجاد قابلیت دیده شدن در جستجو پیش از اوج تقاضا را تشریح میکند.
از تجزیهوتحلیلهای روند Exploding Topics برای شناسایی موجودیتهای آینده استفاده کنید – نه فقط موضوعات
اکثر بازاریابانی که از Exploding Topics استفاده میکنند، ارزش آن را برای ایدهپردازی محتوا درک میکنند و ما این را پوشش میدهیم.
اما فرصت بزرگتر آن، شناسایی موجودیتهای آینده است – مفاهیمی که موتورهای جستجو و سیستمهای هوش مصنوعی بهزودی بهعنوان «اشیاء» متمایز تشخیص خواهند داد، نه صرفاً بهعنوان تغییرات کلمه کلیدی.
این مهم است زیرا جستجوی مدرن دیگر صرفاً بر پایه کلمات کلیدی عمل نمیکند.
مرورهای هوش مصنوعی گوگل، ChatGPT و سایر سامانههای مبتنی بر مدلهای زبانی بزرگ (LLM) اطلاعات را حول موجودیتها و روابط سازماندهی میکنند.
بهمحض اینکه یک موجودیت تثبیت شود، روایت پیرامون آن سفت میشود.
اگر دیر رسیدید، در قصهای که پیشاپیش تعریفشده رقابت میکنید.
Exploding Topics به شما دیدگاهی کافی میدهد تا قبل از وقوع این اتفاق، اقدام کنید.
مثال: ماسکهای خواب وزندار
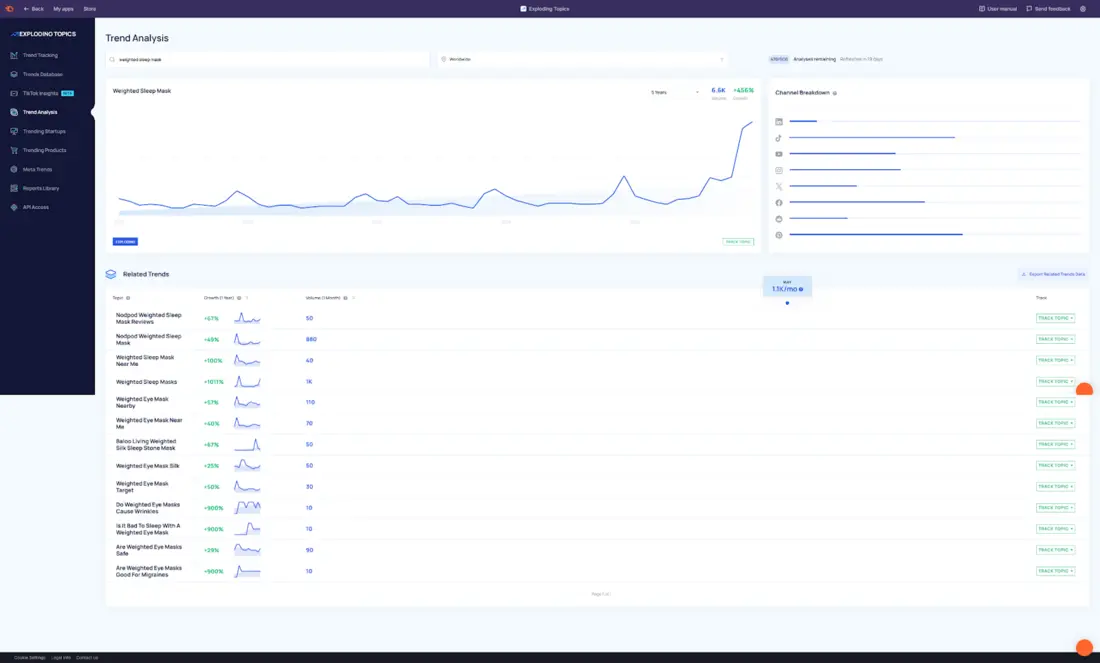
در Exploding Topics ممکن است متوجه افزایش پیوسته «ماسک خواب وزندار» شوید.
حجم جستجو هنوز پایین است و اکثر ابزارهای کلمه کلیدی اهمیت آن را کمارزش میدانند.
در نگاه اول بهنظر میرسد این یک روند محصول خاص است که بهسادهگی میتوان آن را نادیده گرفت.
اگر دقیقتر نگاه کنید، سیگنالها قویتر میشوند:
- عبارت ثابت و قابل تکرار است.
- موضوعات مرتبط در کنار آن رو به رشد هستند، از جمله خواب با فشار عمیق، ابزارهای خواب برای اضطراب، و تحریک عصب واگ.
- سؤالاتی که نشانگر قصد هستند، در حال افزایش است.
- گفتگوهای اولیه بر درک مفهوم تمرکز دارند، نه صرفاً خرید محصول.
این نقطهای است که چیزی از یک محصول توصیفی به یک راهحل نامدار تبدیل میشود؛ به عبارت دیگر، در حال تبدیل شدن به یک موجودیت است.
رویکرد سنتی
اکثر برندها صبر میکنند تا:
- تقاضای جستجو واضح شود، در دسامبر ۲۰۲۵ اقدام کنند نه در ژوئیه ۲۰۲۵.
- رقبا صفحات محصول اختصاصی راهاندازی کنند.
- وابستگان و ناشران محتواهای «بهترین» و «مقابل» را منتشر کنند.
فقط پس از آنها ایجاد میکنند:
- یک صفحه دستهبندی.
- مقالهای با عنوان «ماسک خواب وزندار چیست؟» یا فعالسازی جستجوی اجتماعی.
- محتوای سئو طراحیشده برای جلب حضور، مانند سؤالات متداول (FAQ)، ویژگیهای SERP و رتبهبندیها.
در این مقطع، موجودیت قبلاً وجود دارد و روایت پیرامون آن عمدتاً توسط شخص دیگری نوشته شده است.
در این مورد، NodPod بهوضوح بر موجودیت تسلط دارد.
اقدام زودتر، در حال شکلگیری موجودیت
استفاده مؤثر از Exploding Topics به معنای اقدام زودتر است، در حالی که موجودیت هنوز تعریف میشود. بهجای شروع با صفحه محصول، شما:
- یک توضیح واضح و معتبر از این که ماسک خواب وزندار چیست، منتشر میکنید.
- توضیح میدهید چرا فشار عمیق میتواند در بهبود خواب و اضطراب مؤثر باشد.
- به مخاطبان هدف بپردازید – کسانی که برایشان مناسب است و کسانی که نیست.
- محتوای پشتیبانیکنندهای ایجاد کنید که زمینه بیشتری میدهد، مانند مقایسه با پتوهای وزندار یا نکات ایمنی.
این کار میتواند بهسرعت و در مقیاس بزرگ از طریق روابط عمومی واکنشپذیر و فعالسازیهای جستجوی اجتماعی انجام شود.
شما هنوز برای بهینهسازی کلمات کلیدی اقدام نمیکنید.
شما به الگوریتمهای اجتماعی، موتورهای جستجو و سیستمهای هوش مصنوعی میآموزید که این مفهوم چه معنایی دارد و برند خود را از ابتدا با این توضیح مرتبط میکنید.
این همان روشی است که برندها میتوانند در جستجو در سال ۲۰۲۶ و پس از آن موفق شوند.
این رویکرد پیشدستانه و زودهنگام:
- به سیستمهای جستجو کمک میکند تا مفاهیم جدید را سریعتر درک کنند.
- احتمال بازاستفاده از چارچوب شما در پاسخهای تولید شده توسط هوش مصنوعی را افزایش میدهد.
- برند شما را بهعنوان مرجع در مورد این موجودیت موقعیت میدهد – نه تنها بهعنوان فروشندهای در گفتگو.
بیشتر بررسی کنید: فراتر از گوگل: چگونگی تدوین یک استراتژی جستجوی جامع
اعتبارسنجی موجودیتهای نوظهور از طریق جستجوی اجتماعی
شناسایی یک موجودیت نوظهور تنها گام نخست است.
ریسک واقعی، نه تنها زود بودن در یک گفتوگو، بلکه زود بودن برای چیزی است که هرگز به اوج نمیرسد.
در اینجا بسیاری از تیمهای سئو متوقف میشوند.
آنها منتظر حجم جستجو میمانند و دیر میرسند، بر اساس احساس منتشر میکنند و امید دارند تقاضا دنبال کند، یا تحت عدم اطمینان سر میفشارند و کاری انجام نمیدهند.
یک میانه بهتر وجود دارد: اعتبارسنجی موجودیتهای نوظهور از طریق تحقیق و آزمونهای فعالسازی جستجوی اجتماعی پیش از بزرگمقیاس کردن آنها در سئو اختصاصی و تجربههای داخلی.
Exploding Topics ساده است. آن نشان میدهد چه چیزی ممکن است مهم باشد. پلتفرمهای اجتماعی به شما میگویند آیا مخاطبانتان واقعاً به آن اهمیت میدهند.
چگونه جستجوی اجتماعی لایه اعتبارسنجی شما میشود
پس از آنکه Exploding Topics یک موجودیت نوظهور بالقوه را نمایان میکند، گام بعدی Keyword Planner نیست.
جستجوی بومی در پلتفرمهایی مانند TikTok، Reddit و YouTube است که با استفاده از ابزارهای روند داخلی یا جستجوی ساده پلتفرم انجام میشود.
شما به دنبال سیگنالهای زیر هستید:
- چندین سازنده محتوا بهصورت مستقل همان مفهوم را توضیح میدهند.
- بخشهای نظرات پر از سؤالاتی مانند «آیا واقعاً کار میکند؟» یا «آیا ایمن است؟» است.
- چارچوبها، استعارهها یا نمایشهای تکراری.
- محتوای ابتدایی آموزش یا مقایسه، حتی اگر کیفیت تولید پایین باشد.
این سیگنالها نشانگر نیت هستند.
کنجکاوی به درک تبدیل میشود.
تاریخاً، این فاز همیشه پیش از تقاضای قابلتجزیه در جستجو بوده است.
بازنگری مثال ماسک خواب وزندار
پس از مشاهده «ماسک خواب وزندار» در Exploding Topics، میتوانید آن را در TikTok جستجو کنید.
آنچه میخواهید ببینید، عدم وجود تبلیغات سنگین برند است.
پیشنهادهای تجاری پیشرفته یا مسیرهای TikTok Shop نشان میدهد بازار قبلاً تثبیت شده است.
بهجای آن، به دنبال سازندگان محتوا – نه کانالهای برند – باشید که محصولات را آزمایش میکنند، راهحلها را بررسی میکنند و به مشکل اساسی میپردازند.
- روی ویدیوهایی تمرکز کنید که دردها، نیازها و انگیزهها را توضیح میدهند، مانند اینکه چرا فشار میتواند به اضطراب کمک کند.
- نظرات را برای مقایسه با دیگر راهحلها بررسی کنید.
- به سؤالات مطرحشده در ویدیوها و بخشهای نظرات توجه کنید.
ابزاری مثل Buzzabout.AI میتواند این کار را در مقیاس بزرگ از طریق تحلیل موضوعات و پژوهشهای کمکدست هوش مصنوعی انجام دهد.
این سیگنالها به دو سؤال کلیدی پاسخ میدهند:
- آیا افراد فعالانه سعی در درک این مفهوم دارند؟
- چه زبان، چارچوب و اعتراضاتی پیش از وجود دادههای سئو شکل میگیرد؟
این همان اعتبارسنجی است.
بازنگری در چگونگی ساخت استراتژی سئو
در اینجا است که استراتژی جستجو تغییر میکند.
بهجای پرسیدن «آیا حجم کافی برای توجیه … وجود دارد؟»، سؤال بهتر این است: «آیا کنجکاوی کافی برای توجیه ساختن اعتبار پیش از موعد وجود دارد؟»
اگر سیگنالهای اجتماعی ضعیف باشند:
- متوقف شوید.
- ریسک را با آزمایش با سازندگان محتوا خارج از کانالهای خودتان کاهش دهید.
- از سرمایهگذاری سنگین در محتواهایی که ماهها طول میکشد تا رتبه بگیرد، اجتناب کنید.
اگر سیگنالها قوی باشند:
- با اطمینان گسترش دهید.
- با سازندگان همکاری کنید و کانالهای برند را فعال کنید.
- در صفحات موجودیت، هابها، سؤالات متداول، مقایسات و بهینهسازی صفحات لیست محصول (PLP) سرمایهگذاری کنید.
در این مدل، پلتفرمهای اجتماعی پرسرعت لایه آزمایش میشوند.
سئو آزمایش نیست؛ بلکه لایه ترکیبی (تراکمساز) است.
بیشتر کاوش کنید: محتوای تولید شده توسط کاربران (UGC) و رسانههای اجتماعی: موتورهای اعتماد که جستجو را در همهجا قدرت میدهند
روابط عمومی دیجیتال تحریریهای که لینکها و ارجاعات مدلهای زبانی بزرگ (LLM) را بهدست میآورد
اکثر روابط عمومی دیجیتال هنوز بهصورت معکوس عمل میکند.
- یک روند به شناخت عمومی میرسد.
- روزنامهنگاران درباره آن مینویسند.
- برندها به سرعت برای اظهار نظر میجنگند.
- تیمهای روابط عمومی سعی میکنند لینکها را از داستانی که قبلاً وجود دارد استخراج کنند.
نتیجه، پوشش کوتاهمدت، تأثیر پراکنده و مزیت جستجوی ماندگار کم است.
Exploding Topics امکان معکوس کردن این دینامیک را فراهم میکند؛ با نمایانسازی روایتهای تحریریه پیش از واضح شدن آنها و موقعیتیابی برند شما بهعنوان یکی از منابعی که به تعریف آنها کمک میکند.
در سال ۲۰۲۶، این مورد بیش از پیش اهمیت دارد.
لینکها همچنان مهم هستند، اما دیگر تنها نتیجهای که ارزش دارد، نیستند.
منشنهای برند، توضیحات و ارجاعها بهصورت فزایندهای به سامانههای پشت مرورهای هوش مصنوعی، ChatGPT، Perplexity و دیگر تجربه های کشف مبتنی بر مدلهای زبانی بزرگ (LLM) تغذیه میکنند.
چرا روایتهای پیشدستانه نسبت به روابط عمومی واکنشپذیر برتری دارند
وقتی یک موضوع در همهجا حضور دارد، روزنامهنگاران در حال تجمیع اطلاعات هستند. وقتی یک موضوع در حال ظهور است، هنوز سؤالات میپرسند.
Exploding Topics مفاهیم را در مرحلهای نشان میدهد که:
- هنوز روایت توافقنظر وجود ندارد.
- تعاریف یکنواخت نیستند.
- روزنامهنگاران بهدنبال وضوح هستند، نه نقلقول.
- داستانهای «این چه چیزی است؟» هنوز نوشته نشدهاند.
این همان نقطهای است که برندها میتوانند از نظر دادن به یک گفتوگو به شکلدادن به آن تغییر مسیر دهند.
از جاک کننده روند به صاحب روایت
بهجای ارائه «دیدگاه برند ما درباره X»، با سیگنالهای ابتداییای که میبینید، دلایل ظهور این مفهوم در حال حاضر و آنچه درباره رفتار مصرفکننده یا بازار نشان میدهد، پیشقدم میشوید.
تفاوت جزئی اما مهم است.
شما دیگر به پوششهایی که از پیش وجود دارد واکنش نشان نمیدهید.
شما چارچوبی میسازید که روزنامهنگاران، ناشران و در نهایت سامانههای هوش مصنوعی از آن استفاده میکنند.
مدلهای زبانی بزرگ (LLM) تنها از رتبهبندیها یاد نمیگیرند.
آنها از زمینه تحریریه، توضیحات تکراری و چگونگی توصیف و تعریف مفاهیم نوظهور توسط نشریات معتبر، در طول زمان یاد میگیرند.
اگر بهطور مستمر این رویکرد اعمال شود، ترکیب میشود.
همانگونه که برند شما با شناسایی و توضیح روایتهای نوظهور در مراحل اولیه مرتبط میشود، از نظرات واکنشی به منبع معتمد تبدیل میشوید.
روزنامهنگاران شروع میکنند به شناسایی منبع بینشهای مفید میپردازند و این اعتماد در پوششهای برجستهتر در آینده ادامه مییابد. شما دیگر برای حضور خود درخواست نمیکنید.
دیدگاه شما بهطور فعال درخواست میشود.
نتیجه، مالکیت پیشدستانه روایت و دسترسی قویتر زمانی که پوشش گستردهتر میآید، است.
پنجره تحریریهای پیش از پوشش گسترده
پیش از آنکه «ماسک خواب وزندار» به عنوان یک اصطلاح پر ازدحام در تجارت الکترونیک اوایل ۲۰۲۵ تبدیل شود، یک پنجره تحریریهای واضح وجود داشت.
روزنامهنگاران هنوز داستانهایی منتشر نکرده بودند که میپرسند:
- «ماسک خواب وزندار چیست؟»
- «آیا ماسکهای خواب وزندار ایمن هستند؟»
- «آیا واقعاً برای اضطراب مؤثر هستند؟»
این همان فرصت بود.
یک رویکرد مبتنی بر روابط عمومی در این مرحله شامل میشود:
- ارائه توضیحات تخصصی به روزنامهنگاران درباره فشار عمیق و خواب.
- بهاشتراکگذاری دیدگاههای اولیه درباره دلیل ظهور این دستهبندی محصول.
- ارائه زمینه در کنار پتوهای وزندار و سایر ابزارهای اضطراب.
نتیجه فقط پوشش نیست. این اتصال روابط عمومی به جستجو، کنجکاوی و کشف است که با کمک به تعریف خود مفهوم، ارتباط برقرار میکند.
این کار لینکها را بهدست میآورد، اشارههای برند را میسازد و اختیار را در اطراف موجودیتهای نوظهور که مدلهای زبانی بزرگ (LLM) بهمرور زمان بیشتر بهاستناد میگیرند و خلاصه میکنند، نشان میدهد.
بیشتر بررسی کنید: چرا روابط عمومی برای دیده شدن در جستجوی هوش مصنوعی اهمیت بیشتری پیدا میکند
نقشههای محتوایی و بریفهایی که به حجم جستجو وابسته نیستند
حجم جستجو نقطه شروع ضعیفی برای بریفسازی محتوا است.
این فقط علاقه را پس از تثبیت یک موضوع، تثبیت زبان و پر شدن SERP نشان میدهد.
استفاده از آن بهعنوان ورودی اصلی، تیمها را به دنبال کردن تقاضا میکشاند بهجای ساختن اعتبار.
به همین دلیل است که بسیاری از برندها سال بهسال پست «X چیست؟» را بازنویسی میکنند.
بریفهای بهتر در بالا سطر (بالای جریان) آغاز میشوند.
آنها از Exploding Topics برای شناسایی آنچه در حال شکلگیری است و از جستجوی اجتماعی برای درک چگونگی تلاش مردم برای فهمیدن آن استفاده میکنند.
بازتعریف فرایند بریفسازی
تغییر اصلی، حرکت از بریفهای مبتنی بر کلمات کلیدی و حجم به بریفهای مبتنی بر نیت مخاطب است.
به این معنی است که بر سه نکته تمرکز کنید:
- مشکلاتی که مردم شروع به بیان آنها میکنند.
- مفهومهایی که هنوز بهصورت واضح تعریف نشدهاند یا مورد بحث فعال قرار دارند.
- زبانی که ناهمسان، احساسی یا اکتشافی است.
زمانی که محتوا به این روش مطرح میشود، هدف تغییر میکند.
دیگر «ایجاد X برای رتبهبندی Y» نیست.
بلکه «X را توضیح دهید تا مخاطب Y را تجربه نکند».
این تغییر مهم است.
طراحی محتواای که ترکیب میشود بهجای اینکه منقضی شود
هدف تیمهای محتوای سئو در سال ۲۰۲۶ و پس از آن باید تهیه بریف محتوا باشد که یک مفهوم را بهوضوح تعریف کند. این شامل:
- اتصال آن به ایدههای مرتبط.
- مقایسه آن با راهحلهای موجود.
- پاسخ به سؤالات در گفتوگوهایی که هنوز در حال شکلگیری هستند.
این همیشه نیازی به محتوای نوشتاری ندارد.
همین کار میتواند از طریق فعالسازیهای جستجوی اجتماعی یا روابط عمومی دیجیتال انجام شود.
اگر به این شکل مورد استفاده قرار گیرد، محتوا به جای تعقیب تقاضا، خود را به سمت تقاضا میسازد.
بهجای بازنویسی هر بار که حجم جستجو تغییر میکند، از طریق بهروزرسانیها، گسترش و در صورت امکان، پیوند داخلی قویتر پیشرفت میکند.
بهمحض رشد علاقه، محتوا نیازی به جایگزینی ندارد؛ فقط بهرفع نقاط ضعف نیاز دارد.
این همان نوع مطالبی است که هوش مصنوعی و مدلهای زبانی بزرگ (LLM) تمایل دارند به آن استناد کنند – بهموقع، واضح، توضیحی و مبتنی بر سؤالات واقعی.
انتشار پایان کار نیست
منتشر کردن و انتظار برای رتبهبندی محتوا دیگر پایان بریف نیست.
تیمها به برنامه واضحی برای توزیع و بازاستفاده نیاز دارند.
برای موضوعات نوظهور، این به معنای ارائه بینش در پستهای مرتبط Reddit، جوامع Discord، انجمنهای تخصصی و بخشهای نظرات سازندگان است.
نه برای گذاشتن لینکها، بلکه برای پاسخ به سؤالات، به اشتراکگذاری توضیحات، و آزمایش چارچوب در عموم.
این گفتوگوها بهصورت بازخوردی به خود محتوا برمیگردند، وضوح را بهبود میبخشند و احتمال این را افزایش میدهند که توضیح شما توسط دیگران تکرار شود.
با رویکرد فعالسازی جستجوی اجتماعی، برندها میتوانند پیامگذاری را بهسرعت مقیاسبندی کنند، از طریق همکاری با شرکایی که بریف را به صدای خود تفسیر و توزیع میکنند.
وقتی این کار انجام شود، محتوای سئو دیگر ایستای نیست و بهجای آن مانند نقطهمرجع زنده عمل میکند – نقطهای که به فرهنگ کمک میکند و شناختی پایدار برای برند میسازد.
بیشتر کاوش کنید: فراتر از قابلمشاهده در SERP: ۷ معیار موفقیت برای جستجوی ارگانیک در سال ۲۰۲۶
جایی که این وضعیت سئو را در سال ۲۰۲۶ میگذارد
تقاضای جستجو بهصورت کامل شکل نگرفتهاست.
این در پلتفرمهای اجتماعی، جوامع و کشف مبتنی بر هوش مصنوعی توسعه مییابد، خیلی پیش از اینکه بهعنوان حجم کلیدواژه ثبت شود.
- Exploding Topics به نمایانسازی آنچه در حال ظهور است کمک میکند.
- جستجوی اجتماعی نشان میدهد آیا مردم سعی در فهمیدن آن دارند یا نه.
- روابط عمومی دیجیتال به شکلدادن به نحوه تعریف و ارجاع به این ایدهها کمک میکند.
- سئو بهوسیله تقویت روایتهای در حال شکلگیری ترکیب میشود، نه اینکه پس از وقوع سعی در آزمون یا ابداع آنها داشته باشد.
در این مدل، سئو لایهای است که بینشهای ابتدایی و توضیح واضح را به قابلیت دیده شدن پایدار در گوگل، پلتفرمهای اجتماعی و پاسخهای تولیدشده توسط هوش مصنوعی تبدیل میکند.
جستجو دیگر از گوگل شروع نمیشود. تیمهایی که بر این واقعیت عمل میکنند، بر آنچه مردم بعداً جستجو میکنند، تأثیر میگذارند.