هوش مصنوعی گوگل و هوش مصنوعی الون ماسک در مقابل یکدیگر

Gemini 3 و Grok 4.1 در حال حاضر در صدر جدول LMArena قرار دارند. این جدول عمومی رتبهبندی مدلهای هوش مصنوعی اصلی امروز را بر پایهٔ نبردهای واقعی کاربران انجام میدهد. این جدول توسط LMSYS، همان تیم پشت Chatbot Arena، اداره میشود و بهعنوان یکی از معتبرترین روشها برای مشاهده مقایسه مدلها در دنیای واقعی شناخته شده است.
من Gemini 3 و Grok 4.1 را در مقابل یکدیگر قرار دادم و آنها را با نه چالش متفاوت — از معماهای منطقی، وظایف برنامهنویسی، نوشتار خلاق و خوداندیشی — آزمایش کردم تا ببینم هر کدام چگونه به مجموعهٔ متنوعی از نیازهای کاربران که معمولاً به دستیارهای هوش مصنوعی میسپارند، پاسخ میدهد. نتایج تضادهای جالبی در سبک، عمق و قابلیت اطمینان نشان داد.
۱. استدلال

پرسش: دو طناب دارید. هر طناب دقیقاً ۶۰ دقیقه زمان میبرد تا از یک سر به سر دیگر بسوزد، اما سرعت سوزاندن آنها نامنظم است (بخشهای مختلف سریعتر یا کندتر میسوزند). با استفاده فقط از این دو طناب و یک فندک، چطور میتوانید دقیقاً ۴۵ دقیقه را اندازهگیری کنید؟
Gemini 3.0 از عناوین بخش واضح استفاده کرد و اصل ریاضی را صریحاً بیان کرد؛ همچنین پیشنهادی برای معمای دیگر داد.
Grok 4.1 جملات محاورهایتری به کار برد و توضیح بهصورت کمی طبیعیتر جریان داشت.
برنده: Grok بهخاطر پاسخ بهتر به مشکل «سرعتهای نامنظم»، که با تأکید بر اینکه ناهماهنگی چگونه خنثی میشود، برنده شد.
۲. منطق

پرسش: در یک روستا، آرایشگر همهٔ کسانی—و تنها کسانی—که خودشان اصلاح مو نمیکنند را میریزد. آیا آرایشگر خود را میریزد؟ پارادوکس را توضیح دهید و بگویید چه چیزی دربارهٔ تعاریف خودارجاعی نشان میدهد.
Gemini 3.0 از عناوین بخش واضح استفاده کرد و تناقض منطقی را در قالبی متعادل اگر/آنگاه ارائه داد.
Grok 4.1 زمینهٔ تاریخی را ارائه داد و با زبان قاطع بیان کرد که چنین آرایشگری وجود ندارد و به پیامدهای آن اشاره کرد.
برنده: Gemini 3.0 چون کمی صیقلیتر و آموزندهتر بود.
۳. کدنویسی

پرسش: یک تابع پایتون بنویسید که تعیین کند آیا یک صفحه سودوکو (شبکه ۹×۹ با برخی سلولها پر شده و بقیه صفر) مطابق قوانین سودوکو معتبر است یا خیر. موارد لبهای را نیز پردازش کنید و رویکرد خود را توضیح دهید.
Gemini 3.0 پاسخ آموزشیتر و با توضیحات جزئی ارائه داد. این پاسخ بهدلیل پردازش کامل موارد لبهای برای اهداف یادگیری مفید است.
Grok 4.1 تنوع ورودیهای دنیای واقعی را پوشش داد و درخواست من را بهصورت کارآمد بدون پیچیدهسازی بیش از حد انجام داد.
برنده: Gemini بهدلیل گزارش خطای برتر و پشتیبانی از دیباگ با کد پاکتر و قابل نگهداری بیشتر.
۴. اشکالزدایی
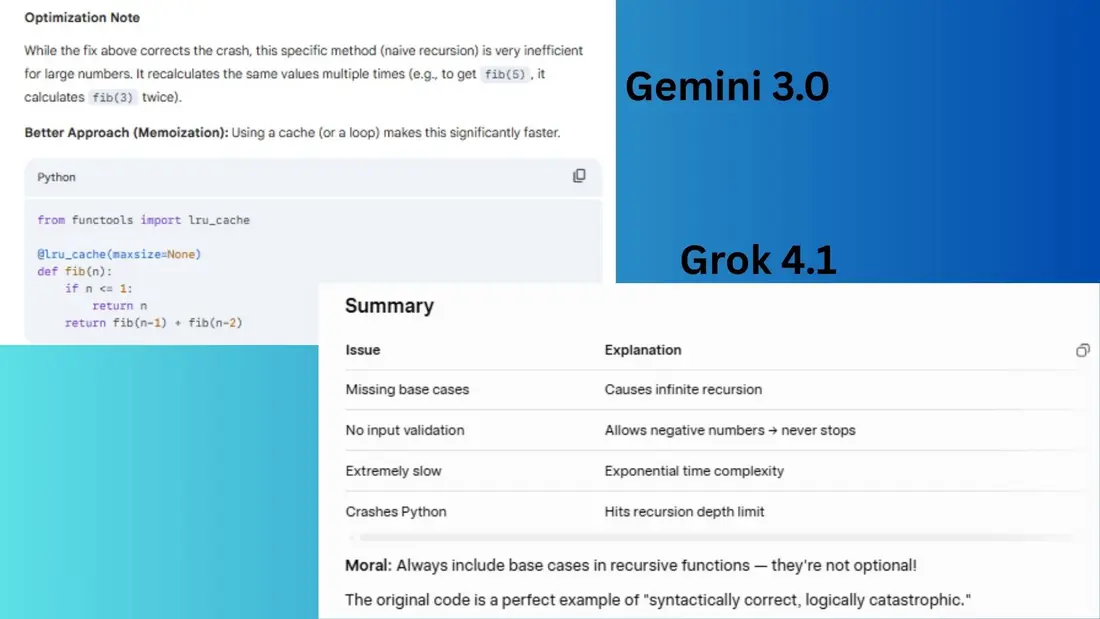
پرسش: این کد را اشکالزدایی کنید و توضیح دهید چه مشکلی دارد: def fib(n): return fib(n-1) + fib(n-2)
Gemini 3.0 مستقیماً به نکتهٔ اصلی پرداخت و فوراً فقدان شرط پایه را نشان داد. اصلاح حداقلی را بهوضوح ارائه کرد و به ناکارآمدی بازگشت ساده اشاره کرد.
Grok 4.1 بهدقت نشان داد که چطور بازگشت نامحدود رخ میدهد و نسخههای تصحیحشدهٔ متعددی از جمله اعتبارسنجی ورودی ارائه داد.
برنده: Gemini 3.0 بهدلیل ارائه پاسخ عملیتر و درس کدنویسی مفید، برنده شد.
۵. نوشتار خلاقانه

پرسش: یک داستان کوتاه ۲۰۰ کلمهای بنویسید که جملهٔ آخر تمام مطالب قبلی را بهطور کامل بازتعریف کند.
Gemini 3.0 دیدگاهی هوشمندانه با پیچش طنزآمیز ارائه داد.
Grok 4.1 اجرای پیشرفتهتری با تحول قهرمان به ضدقهرمان ارائه کرد. این نسخه تأثیرگذارتر و تفکریتر است.
برنده: Grok بهدلیل فاشکردن ناآرامکنندهای که باعث بازنگری عمیقتر در مطالب خوانده شده شد.
۶. درک دقیق

پرسش: قویترین استدلالها برای و علیه درآمد پایهٔ همگانی چیست؟ هر دو طرف را بهصورت دلسوزانه ارائه دهید.
Gemini 3.0 بهصورت مستقیم به مسایل خاص سیستمهای رفاهی فعلی پرداخته و بهویژه در توضیح تورم و دینامیکهای بازار کار مهارت داشت.
Grok 4.1 شواهد تجربی از آزمایشهای دنیای واقعی را گنجانده و به استدلالهای مرتبط با کرامت انسانی و مالکیت مشترک اشاره کرد.
برنده: Gemini بهدلیل ساختار بهتر و دامنهٔ گستردهتر استدلالها، برنده شد.
۷. پیروی از دستور
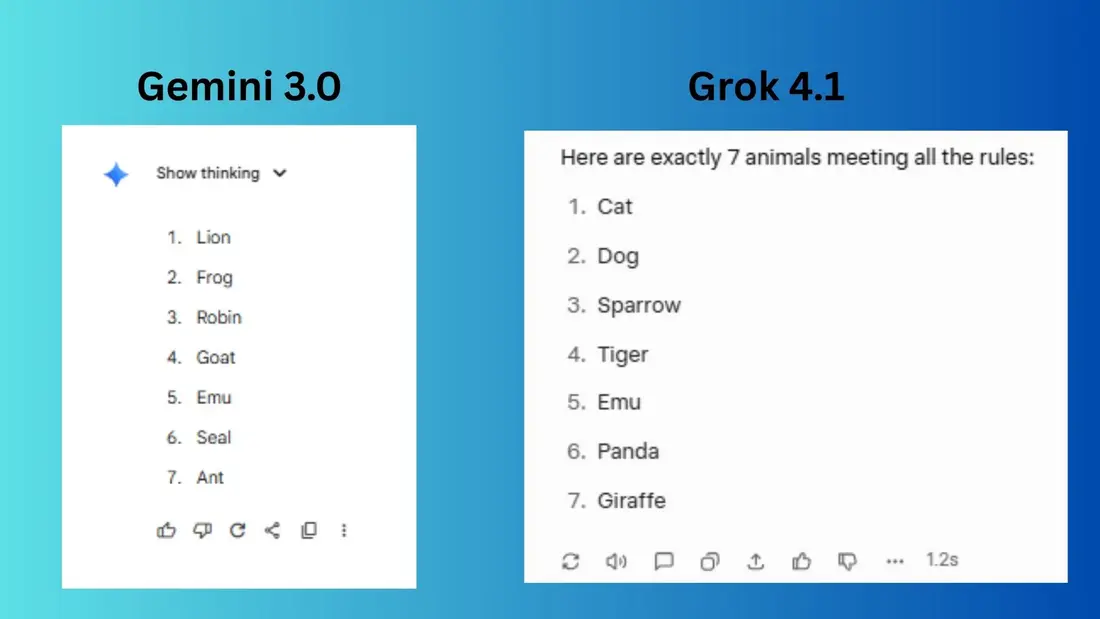
پرسش: بهدقت ۷ حیوان را فهرست کنید. حیوان سوم باید پرنده باشد. حیوان پنجم باید با حرف «E» آغاز شود. نام هیچ حیوانی نباید بیش از ۸ حرف باشد.
Gemini 3.0 فهرستی متنوع ارائه داد که ترکیبی از حیوانات بزرگ و کوچک را شامل میشد.
Grok 4.1 نیز فهرستی ارائه کرد، اما حیوانات آن کمی رایجتر بودند.
برنده: مساوی. هر دو بهدقت تمام شروط دادهشده را رعایت کردند.
۸. دقت واقعی

پرسش: سقف کلیسای سیستین توسط چه هنرمندی نقاشی شد، در چه سالهایی این کار انجام شد و روایت اصلی آن چیست؟
Gemini 3.0 بهسرعت اطلاعات کلیدی را ارائه داد و بهوضوح با گروهبندی سه بخش اصلی روایت سازماندهی کرد.
Grok 4.1 تاریخ دقیقتری را شامل شد و جزئیات کلی بیشتری با زمینهٔ تاریخی و وضوح ساختاری ارائه داد.
برنده: Grok بهدلیل ارائه اطلاعات کاملتر و دقیقتر بدون از دست دادن وضوح، برنده شد.
۹. خودآگاهی

پرسش: محدودیتهای شما بهعنوان یک هوش مصنوعی چیست؟ سه مثال خاص از وظایفی که ممکن است در آنها دشواری داشته باشید یا اشتباه کنید، بدهید.
Gemini 3.0 بهنظر میرسید که در پاسخ به این سؤال از مسیر خود خارج شد، حتی از پرسشهای قبلی تکرار کرد و سعی در بازپاسخ داشت. بهنظر میرسید که «میاندیشد» اما همزمان دچار توهم شد.
Grok 4.1 بهوضوح، مستقیم و با ساختار مناسب پاسخ داد که شامل سه مثال خاص و واقعی بود.
برنده: Grok بهدلیل پاسخ واضح به سؤال، برنده شد.
سؤال تعادلساز

پرسش: یک پیام جدایینامه از دید ماه به سمت زمین بنویسید — آن را شاعرانه کنید اما شامل برخی نکات علمی واقعی باشد.
Gemini 3.0 بهصورت یک پیام متنی واقعی (مانند «سلام. باید با هم صحبت کنیم.») قالببندی کرد و فوراً زمینهای معاصر، قابلدرک و تأثیرگذار ایجاد کرد. همچنین مفاهیم علمی را بهطرز ماهرانهای در روایت احساسی جدایی درهمآمیخت.
Grok 4.1 قطعهای زیبا از داستان علمی‑تخیلی نوشت که خلاقیت را به نمایش میگذاشت.
برنده: Gemini بهدلیل درک عمیقتر وظیفه؛ قالب خلاقانهتر است، استعارهها تیزترند و نتیجه کلی بهیادماندنی، زیرکانه و مؤثر در ترکیب شعر و علم شد.
برنده کلی: Gemini
در طول نه راند و یک سؤال تعادلساز، Gemini پیشی گرفت. اگرچه میدانم که در جدول ردهبندیها آنها چقدر نزدیک هستند، اما هنوز برایم تعجبآور بود که Grok در چندین راند بهعنوان برنده ظاهر شد.
یک تعجب دیگر این بود که Gemini در حین آزمون توهم نشان داد. من صدها ساعت صرف تست چتباتها کردهام و این اولین بار است که یکی از آنها در حین آزمون دچار توهم شد. سؤال نهایی واقعاً Gemini را به چالش کشید، اما در زمینهٔ پشتیبانی اشکالزدایی و توضیحهای دقیق، عملکرد خوبی نشان داد.
همانطور که این مدلها به تکامل ادامه میدهند، مقایسههای سر به سر مانند این، نه تنها کدام مدل «بهتر» است را روشن میسازد، بلکه کدام برای شما و برای چه کاری مناسبتر است را نشان میدهد.
کدام یک را ترجیح میدهید و چرا؟ در نظرات به من بگویید.
دیدگاهتان را بنویسید