هوش مصنوعی میتواند کلیدواژهها را بهصورت گسترده تولید کند، اما تکنیکهای معنایی ساختار و کیفیت سیگنال مورد نیاز را فراهم میکنند تا PPC و SEO در مسیر درست باقی بمانند.
اکنون که هر کسی میتواند با هوش مصنوعی کلیدواژهها را تولید کرده و در عرض چند دقیقه یک کمپین جستجوی پولی راهاندازی کند، تصور میشود که کار سخت تمام شده است.
اما ساخت عملکرد ساختاریافته و قابل گسترش همچنان نیازمند درک واقعی از نحوهٔ کار جستجو است.
تکنیکهایی مانند n‑gramها، فاصله لِونشتین و تشابه جاکارد به بازاریابان جستجو این امکان را میدهند که دادههای نامنظم عبارات جستجو را تفسیر کنند، زمینهٔ مشتری را اعمال کنند و چارچوبهای قابل اعتمادی بسازند که تنها هوش مصنوعی قادر به تولیدشان نیست. در ادامه نحوهٔ کار این تکنیکها بیان میشود.
نقش n‑gramها در تحلیل PPC و SEO
به n‑gramها بهعنوان «n» کلمهای که یک کلیدواژه را تشکیل میدهند، فکر کنید. بهعنوان مثال، در عبارت «مراقب خصوصی نزدیک» ما داریم:
- ۳ یوگرام (یک کلمه): «خصوصی»، «مراقب»، و «نزدیک»
- ۲ بیگرام (دو کلمهٔ پیدر‑پی): «خصوصی مراقب» و «مراقب نزدیک»
- ۱ تیگرام (سه کلمهٔ پیدر‑پی): «خصوصی مراقب نزدیک»
n‑gramها برای سادهسازی فهرست کلیدواژهها مفید هستند.
این هفته، چندین کمپین را که بیش از ۱۰۰٬۰۰۰ عبارت جستجو داشتند، بازسازی کردم. با استفاده از n‑gramها، توانستم این فهرستها را به موارد زیر کاهش دهم:
- حدود ۶٬۰۰۰ یوگرام.
- حدود ۲۳٬۰۰۰ بیگرام.
- حدود ۲۷٬۰۰۰ تیگرام.
با این مجموعههای کوچکتر، ممکن است متوجه شوید که تمام کلیدواژههای حاوی یوگرام «رایگان» عملکرد ضعیفی دارند، بنابراین میتوانید «رایگان» را بهعنوان منفیسازی گسترده (Broad Match Negative) حذف کنید.
از سوی دیگر، ممکن است ببینید که «نزدیک» عملکرد بسیار خوبی دارد، که شما را ترغیب میکند تا با تغییرات محلی و صفحات فرودی متفاوت آزمایش کنید.
با این حال، محدودیتهای واضحی وجود دارد:
- برای این روش به حجم بزرگی از عبارات جستجو نیاز دارید؛ بنابراین این روش بیشتر برای بودجههای بزرگ مناسب است.
- هر چه مقدار «n» بزرگتر شود، این روش کمکارآمدتر میشود، زیرا خروجیهای بزرگتری تولید میکند که هدف را از بین میبرد. در این مرحله، به روشهای پیشرفتهتری مانند فاصله لِونشتین یا تشابه جاکارد نیاز خواهید داشت.
دستهبندی کلیدواژهها با استفاده از n‑gramها
تحلیل دادههای SEO و PPC اغلب نیازمند مرور حجم عظیمی از عبارات جستجوی بلند‑دم (Long‑tail) است که بسیاری از آنها تنها یک بار ظاهر میشوند و دادههای بسیار کمی دارند.
n‑gramها به تبدیل این دادههای بینظم بلند‑دم به اطلاعات واضح و قابل مدیریت کمک میکنند.
این امکان را میدهد که هزینههای هدر رفته را کاهش دهید، فرصتهای جدید را شناسایی کنید و ساختار قابل گسترشی بسازید.
- ابتدا دادههای عبارات جستجو را خروجی بگیرید. در PPC، این دادهها شامل هزینه، نمایش، کلیک، تبدیلها و ارزش تبدیل بهتفکیک عبارت جستجو میشود.
- برای هر n‑gram، هزینه، نمایش، کلیک، تبدیلها و ارزش تبدیل را جمع کنید.
- سپس CPA، ROAS، CTR، CVR و سایر معیارهای مرتبط را محاسبه کنید.
با این مجموعهدادهٔ کوتاهتر و قابلهضم، میتوانید n‑gramهای با هزینهٔ بالا که تبدیل نمیشوند (منفیها) و آنهایی که تبدیل میشوند (مثبتها) را رتبهبندی کنید.
از اینجا، گروههای تبلیغاتی را بر پایه n‑gramهای تکراری که عملکرد را بهبود میبخشند، بسازید.
بهعنوان مثال، ممکن است متوجه شوید که n‑gramهای مرتبط با اضطراری (مانند «۲۴/۷»، «همین روز»، «فوری» و غیره) اغلب نرخ تبدیل بالاتری ارائه میدهند. شما میتوانید این موارد را برای کنترل مؤثرتر تقسیمبندی کنید.
خلاصهٔ مطلب: n‑gramها به شما کمک میکنند تا موضوعاتی را که شایستهٔ توجه ویژه هستند، شناسایی کنید.
بهعمقتر نگاه کنید: چگونه جواهرات پنهان در حسابهای جستجوی پولی خود را کشف کنید
چگونه از فاصله لِونشتین برای بهبود کیفیت کلیدواژهها استفاده کنیم
فاصله لِونشتین تعداد حداقل ویرایشهای تکنمزی – افزودن، حذف یا جایگزینی – مورد نیاز برای تبدیل یک رشته به رشتهٔ دیگر را اندازهگیری میکند.
اگرچه ممکن است پیچیده به نظر برسد، ولی مفهوم آن در واقع ساده است.
فاصله لِونشتین بین «cat» و «cats» برابر ۱ است، زیرا تنها کافی است حرف «s» را اضافه کنید. بین «cat» و «dog»، فاصله ۳ است. و به همین ترتیب.
یک کاربرد رایج، شناسایی اشتباهات املایی برندها و رقبا است که در عبارات جستجوی شما ظاهر میشوند.
بهعنوان مثال، «uber» و «uver» فاصله لِونشتین ۱ دارند، بنابراین میتوانید نسخهٔ اشتباهنویسی شده را با اطمینان از کمپینهای غیر برند حذف کنید.
میتوانید همین منطق را برای ارزیابی ارتباط کلیدواژهها بهکار ببرید.
اگر فاصلهٔ بین یک کلیدواژه و عبارات جستجویی که با آن مطابقت دارد، زیاد باشد – مثلا ۱۰ یا بیشتر – احتمالاً این عبارات ارتباط کمی با کلیدواژه دارند و نیاز به بررسی دارند.
از سوی دیگر، فاصلهٔ کم معمولاً به این معنی است که این عبارات ایمن هستند و نیازی به بررسی دستی ندارند.
یکپارچهسازی کلیدواژههای PPC با استفاده از فاصله لِونشتین
پس از استفاده از n‑gramها برای ساختن خوشههای اولیهٔ کلیدواژهها، ممکن است همچنان با هزاران عبارت جستجو برای سازماندهی در یک ساختار کمپین قابلکار مواجه شوید.
مرتبسازی دستی ۶٬۰۰۰ یوگرام گزینهای نیست. در اینجا فاصله لِونشتین بهعنوان یک ابزار اساسی ظاهر میشود.
هدف این است که گروههای تبلیغاتی را که هدفشان کلیدواژههای تقریباً یکسان هستند، ادغام کنید تا از ساختار بیش از حد جزئی و شبیه به SKAG جلوگیری شود.
جزئیکاری بیش از حد، گزارشگیری و مدیریت حساب را پیچیده میکند و منجر به پیشنهادهای ناکارآمد و هزینههای هدر رفته میشود.
با استفاده از همان مجموعهداده، فاصله لِونشتین بین عبارات جستجو در گروههای مختلف تبلیغاتی را محاسبه کنید.
سپس کلیدواژه و گروه تبلیغاتی نزدیکترین را با استفاده از آستانهٔ از پیش تعیینشده شناسایی کنید – بهعنوان مثال، ۳ برای دقت بالا.
این بهصورت ایمن امکان یکپارچهسازی کلیدواژهها و گروههای تبلیغاتی را میدهد. با آستانهٔ سستتر، مثلاً ۶، میتوانید گروهها را بر اساس شباهت یا نیت نیز تجمیع یا نامگذاری کنید.
در ادامه یک مثال ساده نشان میدهد که چرا سه کلیدواژهٔ زیر میتوانند در یک گروه قرار گیرند:
| فاصله لِونشتین | 24/7 plumber | 24 7 plumber | 247 plumber |
| 24/7 plumber | 0 | 1 | 1 |
| 24 7 plumber | 1 | 0 | 1 |
| 247 plumber | 1 | 1 | 0 |
بهعمقتر نگاه کنید: چگونه از کلیدواژههای منفی در PPC برای حداکثر هدفگیری و بهینهسازی هزینههای تبلیغاتی استفاده کنید
پیشرفت بیشتر با تشابه جاکارد
در PPC، میتوانید تشابه جاکارد را بهعنوان شاخصی برای درک همپوشانی بین دو مجموعهٔ n‑gram سادهسازی کنید.
محاسبهٔ این مقدار ساده است: تعداد انیگرامهای مشترک بین دو مجموعه تقسیم بر مجموع تعداد انیگرامهای منحصر بهفرد در هر دو مجموعه.
اگرچه ممکن است فنی به نظر برسد، اما تصور آن ساده است. میتوانید به این شکل تصور کنید:
- تشابه جاکارد = قرمز / سبز
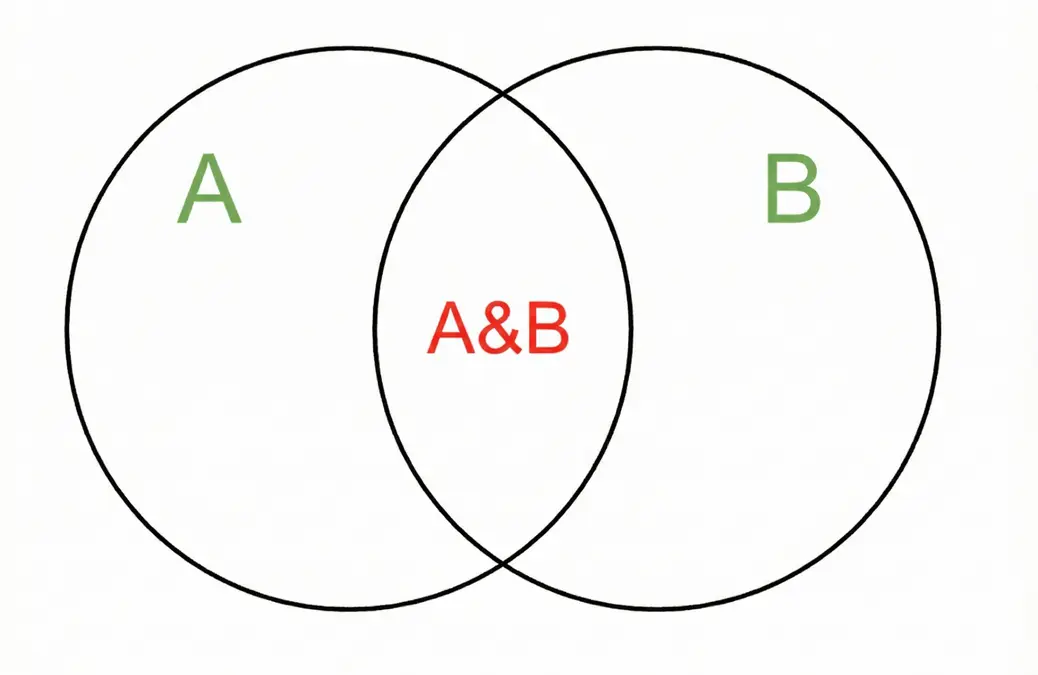
در ادامه مثالهای عینی آورده شده است:
- «new york plumber» و «plumber new york» = 1 (همهٔ سه انیگرام در هر دو مجموعه وجود دارند، فقط ترتیب متفاوت است)
- «new york plumber» و «NYC plumber» = 0.25 (تنها «plumber» مشترک است و مجموع چهار انیگرام وجود دارد)
تشابه جاکارد گام اولیهٔ مفیدی برای حذف تکرار کلیدواژههای مشابه است. این معیار بهطور اساسی فاصلهٔ بین منطق مطابقت عبارات قدیمی و مطابقت گستردهٔ اصلاحشده را پر میکند.
ولی این روش محدودیتهایی دارد؛ زیرا به معنی واژگان توجه نمیکند.
در مثال بالا، «new york» و «NYC» باید معادل شناخته شوند، اما محاسبهٔ جاکارد آنها را متفاوت در نظر میگیرد.
برای مدیریت این سطح از دقت، به تکنیکهای پیشرفتهتری نیاز است (که در مقالهٔ بعدی به آن میپردازم).
ترکیب تشابه جاکارد و فاصله لِونشتین
به یک کمپین دورهٔ امنیت سایبری که شامل ۱۰ کلیدواژهٔ برتر زیر است، نگاه کنید:
| کلیدواژه | جستجوهای متوسط ماهانه در Semrush (ایالات‑متحده) |
| دورههای امنیت سایبری | 5,400 |
| دوره آنلاین امنیت سایبری | 1,900 |
| دورههای امنیت سایبری رایگان | 1,300 |
| دورههای امنیت سایبری آنلاین | 1,300 |
| دوره امنیت سایبری | 1,000 |
| دورههای امنیت سایبری آنلاین | 880 |
| دوره امنیت سایبری گوگل | 880 |
| دورههای امنیت سایبری رایگان | 720 |
| دورههای رایگان امنیت سایبری | 590 |
| دورههای امنیت سایبری آنلاین | 480 |
با ترکیب نسخههای جمع و مفرد و نسخههای با ترتیب متفاوت این کلیدواژهها، میتوانید ۱۰ کلیدواژه برتر را به چهار کلیدواژهٔ کاربردیتر فشرده کنید:
- «دورههای امنیت سایبری».
- «دورههای امنیت سایبری آنلاین».
- «دورههای رایگان امنیت سایبری».
- «دوره امنیت سایبری گوگل».
میتوانید از n‑gramها برای این کار استفاده کنید، اما مقیاسپذیری تحلیل n‑gramها در میان هزاران کلیدواژه میتواند طاقتفرسا باشد.
رویکرد مؤثرتری این است که هر دو معیار شباهت را بهصورت توالی بهکار ببرید.
- ابتدا فاصله لِونشتین را برای ترکیب پرسوجوهای بسیار مشابه اعمال کنید.
- سپس از تشابه جاکارد برای حذف تکرارهای با ترتیب متفاوت استفاده کنید.
- در هر مرحله، معیارهای کلیدی (KPIs) معمولی نظیر هزینه، تبدیلها و سایر معیارها را جمع میکنید تا تحلیل n‑gram همچنان عملی بماند.
نتیجه، ساختاری واضح و فشرده است که حتی با افزایش حجم عبارات جستجو نیز پایدار میماند.
بازسازی کمپینهای جستجوی پولی با تکنیکهای معنایی پیشرفته
با بهکارگیری تکنیکهای معنایی مناسب، میتوانید مجموعههای عظیم کلیدواژهها را بهسرعت و با نتایج باکیفیت و ثابت بازسازی کنید.
هوش مصنوعی میتواند با ارائهٔ خلاصهٔ اولیه کمک کند، اما نباید بهصورت کامل به آن وابسته باشید.
در غیر این صورت، این یک مثال کلاسیک از “ورودی زباله، خروجی زباله” خواهد بود.
مطابقت گسترده میتواند قدرتمند باشد، اما باعث ایجاد سر و صدای بیشتری میشود. این تکنیکها به شما کمک میکنند تا از درستماندن عبارات خود اطمینان حاصل کنید.
از n‑gramها، فاصله لِونشتین و تشابه جاکارد برای اعمال زمینهٔ مشتری به دادههای خام جستجو استفاده کنید و ساختاری ثابت ایجاد کنید که با اهداف کمپین شما هماهنگ باشد.
در ابتدا ممکن است این کار غرقکننده به نظر برسد؛ بنابراین جدول خلاصهای در پایان مقاله آورده شده است:
| سناریو | بهترین تکنیک | دلیل |
| شناسایی الگوهای با قصد بالا در صادرات عظیم عبارات جستجو | n-grams | بهسرعت تمها را آشکار میکند؛ ابعاد را کاهش میدهد |
| حذف کلیدواژههای تکراری / نزدیک به تکراری در مقیاس بزرگ | فاصله لِونشتین | تشخیص شباهتهای املایی و ساختاری |
| حذف تکرار کلیدواژههای بازآراییشده یا کمی متفاوت | تشابه جاکارد | مقایسه توکنی که به ترتیب حساس نیست |
| ایجاد خوشههای قابل گسترش برای بازسازی کمپین | ترکیب: فاصله لِونشتین → تشابه جاکارد → n-gram | دنباله، دقت و فشردهسازی را فراهم میکند |
نویسندگان مشارکتکننده دعوت میشوند تا برای Search Engine Land محتوا تولید کنند و بر پایه تخصص و مشارکتشان در جامعهٔ جستجو انتخاب میشوند. مشارکتکنندگان ما تحت نظارت تیم تحریریه کار میکنند و محتواهایشان برای کیفیت و مرتبط بودن با خوانندگان بررسی میشود. Search Engine Land متعلق به Semrush است. از نویسنده درخواست نشده است تا بهصورت مستقیم یا غیرمستقیم به Semrush اشاره کند. نظراتی که بیان میشود، نظرات شخصی آنهاست.
دیدگاهتان را بنویسید