هوش مصنوعی جستجو را تغییر میدهد، اما سئوی سنتی همچنان اکثر ترافیک را هدایت میکند. دادههای واقعی نشان میدهند کدام تاکتیکها همچنان عملکرد دارند.
هوش مصنوعی مولد در حال حاضر همهجا حضور دارد. در برنامههای کنفرانسها حضور پر رنگی دارد، فیدهای لینکدین را پر میکند و طرز تفکر بسیاری از کسبوکارها درباره جستجوی ارگانیک را دگرگون میکند.
برندها برای بهینهسازی چکیدههای هوش مصنوعی، ساخت تعبیههای برداری، ترسیم خوشههای معنایی و بازطراحی مدلهای محتوا حول مدلهای زبانی بزرگ (LLM) تلاش میکنند.
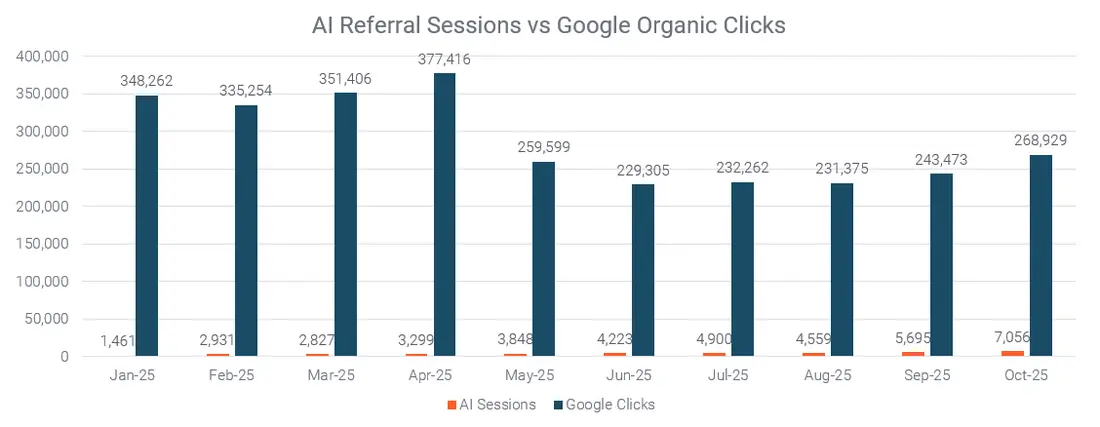
حقیقت سادهای که کمتر مورد توجه قرار میگیرد این است که برای اکثر وبسایتها، پلتفرمهای هوش مصنوعی همچنان نقش کوچکی در ترافیک کلی دارند.
جستجوی هوش مصنوعی در حال رشد است، بدون شک.
اما در اکثر موارد، مجموع جلسات ارجاعی از تمام پلتفرمهای مدل زبانی بزرگ (LLM) بهتنهایی تنها حدود ۲ تا ۳ درصد از ترافیک ارگانیک که فقط گوگل ارائه میدهد، میرسد.
با وجود این فاصله، بسیاری از تیمها زمان بیشتری را صرف دنبال کردن استراتژیهای هوش مصنوعی میکنند تا اصلاح اصول سئوی ساده ولی تأثیرگذار که همچنان نتایج قابلقابلیتسنجی را به ارمغان میآورند.
بهجای بهبود آنچه امروز بیشترین اهمیت را دارد، آنها بیش از حد در آینده سرمایهگذاری میکنند و در حال حاضر عملکرد ضعیفی نشان میدهند.
این مقاله بررسی میکند که چگونه تمرکز محدود بر هوش مصنوعی میتواند تاکتیکهای سئو اثباتشده را پنهان کند و نمونههای عملی و دادههای واقعی را نشان میدهد که این اصول هنوز امروز تأثیرگذارند.
۱. بردهای سریع سئو هنوز نتایج چشمگیری میدهند
در زمانی که همهکس به مسائلی چون تعبیههای برداری و روابط معنایی وسواسی هستند، بهراحتی میتوان فراموش کرد که بهروزرسانیهای کوچک میتوانند تأثیر بزرگی داشته باشند.
به عنوان مثال، برچسبهای عنوان هنوز یکی از سادهترین و مؤثرترین ابزارهای سئو برای استفاده هستند.
و اغلب یکی از عنصرهای صفحهای هستند که بیشتر وبسایتها بهدرستی استفاده نمیکنند؛ یا بهکلیدواژههای نادرست هدف میگیرند، یا تنوعات را لحاظ نمیسازند، یا اصلاً هدفی ندارند.
چند هفته پیش، یک مشتری تنها با افزودن «& [کلیدواژه]» به برچسب عنوان موجود در صفحه اصلیاش، موفقیت چشمگیری بهدست آورد. هیچچیز دیگری تغییر نکرد.
رتبهبندی کلیدواژهها بهسرعت افزایش یافت و همچنین کلیکها و نمایشها برای پرسشهای شامل آن کلیدواژه رشد کردند.
همه اینها تنها با تغییر برچسب عنوان یک صفحه بهدست آمد.
اگر این را همراه با دیگر تاکتیکها، مانند ویرایش محتوای درون صفحه، لینکسازی داخلی و بکلینکسازی در چندین صفحه ترکیب کنید، رشد ادامه خواهد یافت.
ممکن است ساده بهنظر برسد، اما همچنان کار میکند.
و اگر فقط بر استراتژیهای پیشرفته جغرافیایی (GEO) تمرکز کنید، ممکن است تاکتیکهای سادهای که تأثیر فوری و قابلمشاهدهای دارند را نادیده بگیرید.
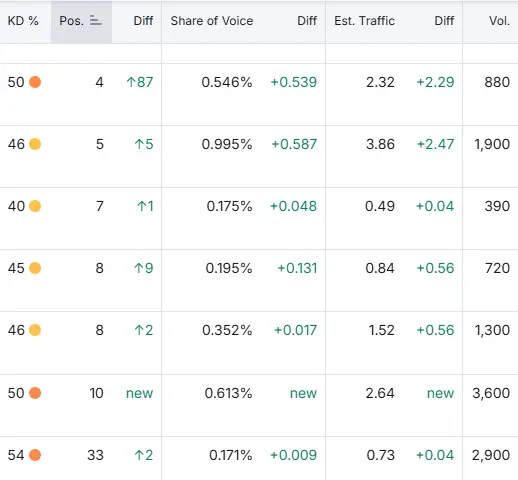
۲. تازگی محتوا و اعتبار هنوز برای کلیدواژههای رقابتی اهمیت دارند
یک تاکتیک دیگر که با ظهور هوش مصنوعی بهکمکم نادیده گرفته شده است، تکنیک «آسمانخراش» (skyscraper technique) نام دارد.
این روش شامل شناسایی مجموعهای از کلیدواژهها و صفحات موجودی است که پیشتر برای آنها رتبه دارند، سپس منتشر کردن نسخهای بهطور محسوسی قویتر که هدفش پیشی گرفتن از نتایج موجود است.
درست است که وب از محتواهای مشابه در موضوعات گوناگون پر شده است، بهویژه برای کلیدواژههایی که در اکثر ابزارهای تحقیق قابل مشاهده هستند.
اما هنگامی که یک سایت دارای اعتبار کافی، حق واضحی برای پیروزی و تازگی محتوا باشد، این رویکرد همچنان میتواند بسیار مؤثر باشد.
من این را بارها شاهد بودهام.
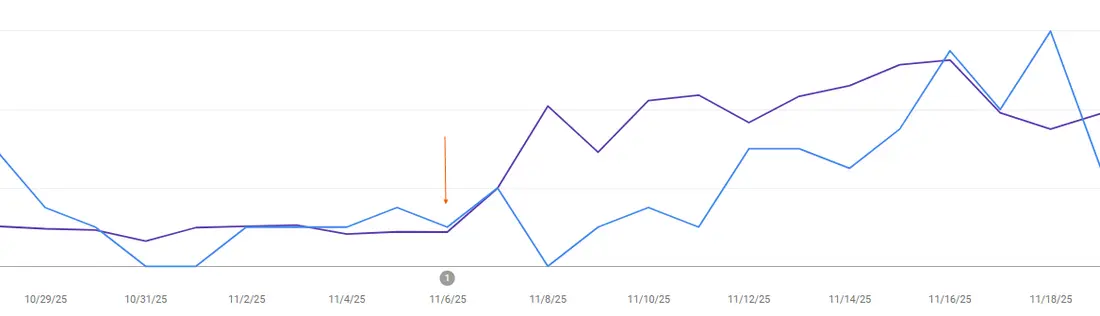
در ادامه، دادههای Google Search Console از یک مقاله اخیر که برای یک مشتری درباره یک موضوع محبوب و دیرینه، که صفحات متعددی در آن رقابت میکردند، منتشر کردیم را میبینید.
این پست تقریباً بلافاصله به رتبه دوم صعود کرد و شروع به تولید کلیکها و نمایشهای جدید خالص کرد.
چرا این کار کرد؟
سایت دارای اعتبار قوی بود و بخش عمدهای از محتوای پیشرفتهتر آن، منسوخ و قدیمی بود.
اگر در انتشار هزارمین مقاله درباره یک موضوع تثبیتشده تردید دارید، این تردید قابلدرک است.
این رویکرد برای همه سایتها کار نخواهد کرد. اما نادیده گرفتن کامل آن میتواند به معنی از دست رفتن فرصتهای روشن و با اعتماد بالا باشد.
۳. تجربه کاربری همچنان یک عامل مهم برای تبدیل است
سر و صدای بیش از حد پیرامون تجربههای خرید مبتنی بر هوش مصنوعی باعث شده برخی تیمها بر این باور باشند که بهینهسازی سنتی وبسایت در حال منسوخ شدن است.
فرضیهای در حال رشد وجود دارد که دستیاران هوش مصنوعی بهزودی اکثر تعاملات را بر عهده بگیرند یا کاربران مستقیماً در پلتفرمهای هوش مصنوعی تبدیل شوند بدون اینکه به وبسایت مراجعه کنند.
بخشی از این آینده در حال شکلگیری است، بهویژه برای برندهای تجارت الکترونیک که در حال آزمایش ویژگیهایی مثل پرداخت لحظهای در ChatGPT هستند.
اما بسیاری از وبسایتها محصولی را نمیفروشند.
و حتی برای آنهایی که میفروشند، اکثر برندها هنوز حجم قابلملاحظهای ترافیک از جستجوی سنتی دریافت میکنند و همچنان برای تبدیلها به دکمههای فراخوانی (CTA) و سیگنالهای داخل صفحه متکی هستند.
همچنین مهم نیست کاربر از طریق چه مسیری وارد میشود – جستجوی ارگانیک، جستجوی پولی، ارجاعهای هوش مصنوعی یا بازدید مستقیم.
یک سایت سریع، تجربه کاربری قوی و قیف تبدیل واضح همچنان اساسی هستند.
بهبودهای واضحی در عملکرد وجود دارد که با بهینهسازی این عناصر حاصل میشود.
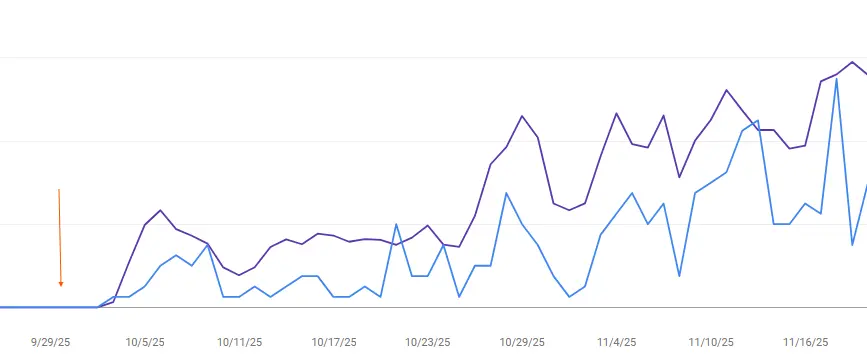
در ادامه نتایجی که بهتازگی برای یک مشتری پس از یک آزمون ساده CTR بهدست آوردیم، آورده شده است:
برندهایی که به سرمایهگذاری در تجربه کاربری و بهینهسازی نرخ تبدیل ادامه میدهند، نسبت به برندهایی که این کار را نمیکنند، عملکرد بهتری خواهند داشت.
این فاصله احتمالاً با طولانیتر شدن زمان انتظار تیمها برای آنکه هوش مصنوعی بهطور کامل قیف تبدیل را جایگزین کند، بیشتر خواهد شد.
هوش مصنوعی جستجو را دگرگون میکند، اما آنچه مؤثر است همچنان مهم است
هیچچالشی وجود ندارد که هوش مصنوعی در حال دگرگون کردن چشمانداز جستجو است.
این تکنولوژی رفتار کاربر را تغییر میدهد، نتایج صفحات جستجو (SERP) را تحت تأثیر قرار میدهد و مدلهای انتساب را پیچیده میکند.
اما خطر بزرگتر برای بسیاری از کسبوکارها، نه دستکمبودن هوش مصنوعی بلکه واکنش بیش از حد به آن است.
جستجوی ارگانیک سنتی همچنان اصلیترین منبع ترافیک برای اکثر وبسایتها است و اصول سئو در صورت اجرای درست، هنوز نتایج قابل توجهی میدهند.
بردهای سریع واقعی هستند.
محتوای با کیفیت بالاتر همچنان مورد تقدیر قرار میگیرد.
بهینهسازی تجربه کاربری نشانهای از برچیده شدن نشان نمیدهد.
اینها تنها چند نمونه از تاکتیکهایی هستند که امروز همچنان مؤثرند.
بهطور مهم، این تلاشها بهصورت جداگانه عمل نمیکنند.
بهبود اصول پایه یک وبسایت میتواند دیدهبانی ارگانیک را تقویت کرده و در عین حال عملکرد جستجوی پولی و دیدهبانی مدلهای زبانی بزرگ (LLM) را نیز پشتیبانی کند.
آگاهی از تحولات هوش مصنوعی و برنامهریزی برای آینده ضروری است.
این نباید به هزینه استراتژیهایی باشد که در حال حاضر رشد قابل اندازهگیری را ایجاد میکنند.
کاهش لیست مخاطبین به ۱۰۰ کاربر، استفاده از ریمارکتینگ و لیست مشتریان را برای تبلیغدهندگان با هر اندازهای آسانتر میکند.
گوگل حداقل تعداد کاربران فعال مورد نیاز برای مخاطبان را در تمام شبکهها و انواع مخاطبان فقط به ۱۰۰ نفر کاهش داد؛ این کار هدفمندسازی ریمارکتینگ و لیست مشتریان را بسیار در دسترستر کرد، بهویژه برای تبلیغدهندگان کوچکتر.
چه تغییر جدیدی است. بخشهای مخاطبی با تنها ۱۰۰ کاربر هماکنون میتوانند در جستجو، نمایش و یوتیوب استفاده شوند، شامل لیستهای ریمارکتینگ و لیستهای مشتریان. همین آستانه ۱۰۰ کاربر هماکنون برای نمایش در «بینشهای مخاطبان» (Audience Insights) اعمال میشود، در حالی که پیش از این این مقدار ۱٬۰۰۰ کاربر بود.
بهروز بمانید. تغییر به سمت آستانههای کوچکتر مخاطب از ماه می آغاز شد، زمانی که گوگل حداقل تعداد کاربران مورد نیاز برای لیستهای مشتریان در کمپینهای جستجو را از ۱٬۰۰۰ به ۱۰۰ کاهش داد.
چرا این مهم است. حسابهای کوچکتر و تبلیغدهندگان تخصصی حال میتوانند استراتژیهای مخاطبی را فعال کنند که پیش از این بهدلیل محدودیتهای اندازه در دسترس نبودند. این تغییر مانع طولانیمدت بر سر شخصیسازی، ریمارکتینگ و فعالسازی دادههای اولینطرف در گوگل ادز را برطرف میکند.
نکات قابلتوجه. چگونگی استفاده تبلیغدهندگان از بخشهای کوچکتر و دقیقتر—و این که آیا عملکرد یا تدابیر حریم خصوصی همراه با دسترسی گستردهتر بهبود مییابند یا خیر.
اولین بار مشاهده شد. این بهروزرسانی نخست توسط مشاور بازاریابی وب، داریو زانونی، در لینکدین به اشتراک گذاشته شد.
نتیجهگیری. با کاهش محدودیتهای اندازه مخاطب به ۱۰۰ کاربر در همه جا، گوگل هدفمندسازی پیشرفته مخاطبان را برای دامنه وسیعتری از تبلیغدهندگان قابل دسترس میکند.
گام OpenAI به سوی تبلیغات در پاسخهای هوش مصنوعی میتواند یک کانال جدید و بهطرزی بسیار متنی برای تبلیغکنندگان ایجاد کند و همزمان بازاریابی دیجیتال را دگرگون سازد.
OpenAI در حال پایهریزی برای یک کسبوکار تبلیغاتی است که نشانگر یک تغییر احتمالی در نحوه کسب درآمد از ChatGPT و سایر محصولات، فراتر از اشتراکها و قراردادهای سازمانی میباشد.
چه خبر است. بر اساس گزارش The Information، OpenAI شروع به بررسی قالبهای تبلیغاتی و مشارکتها کرده است و مذاکرات اولیه به این سمت اشاره میکنند که تبلیغاتی میتوانند درون یا در کنار پاسخهای تولیدشده توسط هوش مصنوعی ظاهر شوند. این تلاش هنوز در مراحل اولیه است، اما گفتگوهای داخلی نشان میدهد که تبلیغات به بخشی جدیتر از استراتژی درآمددهی بلندمدت OpenAI تبدیل میشوند.
چرا مهم است. OpenAI در حال بررسی تبلیغات در داخل پاسخهای تولیدشده توسط هوش مصنوعی است و این کار یک کانال جدید و بهطور ویژه متنی برای دسترسی به کاربران در لحظهای که به دنبال اطلاعات هستند، ایجاد میکند. این میتواند OpenAI را در رقابت مستقیم با Google و Meta قرار دهد، اما بههمینطور سوالاتی دربارهٔ اعتماد و تعامل کاربر برمیانگیزد. پذیرش زودهنگام میتواند مزیتی برای پیشگامان ایجاد کند، در حالی که قالبها و معیارها ممکن است با تبلیغات دیجیتال سنتی متفاوت باشند. بهطور کلی، این یک مرز جدید و تحولآفرین برای تبلیغات به شمار میآید.
نکات نهفته. بهنظر میرسد OpenAI محتاط است و هدفش جلوگیری از مخدوش شدن تجربه کاربری یا تضعیف اعتماد به مدلهای خود است. هر محصول تبلیغاتی بهاحتمال زیاد در ابتدا بهدقت کنترل خواهد شد و بهجای تبلیغ صریح، بهصورت مفید یا متنی مرتبط ارائه میشود.
نگاه کلی. با هزینههای فزاینده زیرساخت و فشارهای رو به رشد برای افزایش درآمد، تبلیغات میتوانند به یک اهرم کلیدی برای OpenAI تبدیل شوند — بهویژه در حالی که هوش مصنوعی مولد در حال تغییر نحوه جستجوی افراد برای اطلاعات و کشف محصولات است.
موارد قابل توجه. زمانی که تبلیغات از برنامهریزی داخلی به آزمایش عمومی منتقل میشوند، میزان واضح بودن برچسبگذاری آنها و اینکه آیا کاربران تبلیغات تعبیهشده در پاسخهای هوش مصنوعی را میپذیرند یا نه، نکاتی هستند که باید دنبال شوند.
نتیجهگیری. OpenAI در حال شتابزده شدن برای عرضه تبلیغات نیست، اما زیرساختهای لازم در حال احداث است — و ورود نهایی آنها میتواند هم محصولات هوش مصنوعی و هم چشمانداز تبلیغات دیجیتال را دگرگون کند.
تقاضای جستجو پیش از ظهور کلمات کلیدی شکل میگیرد. ببینید چگونه Exploding Topics، جستجوی اجتماعی و روابط عمومی، ساختن اعتبار اولیه را پشتیبانی میکنند.
اکتشاف اکنون قبل از اینکه تقاضای جستجو در گوگل نمایان شود، رخ میدهد.
در سال ۲۰۲۶، علاقهمندی در فیدهای اجتماعی، جامعهها و پاسخهای تولید شده توسط هوش مصنوعی شکل میگیرد – خیلی پیش از اینکه بهعنوان حجم جستجوی کلمه کلیدی ظاهر شود.
تا زمانی که تقاضا در ابزارهای سئو ظاهر شود، فرصت شکلدادن به درک یک مفهوم دیگر از دست رفته است.
این مسألهای برای روش معمول انجام تحقیقات بازاریابی جستجو ایجاد میکند.
ابزارهای کلمه کلیدی، حجم جستجو و Google Trends نشانگرهای تأخیری هستند.
آنها آنچه مردم دیروز به آن اهمیت میدادند را نشان میدهند، نه آنچه هماکنون در حال بررسی هستند.
در محیطی که مرورهای هوش مصنوعی، SERPهای اجتماعی و فضای ارگانیک در حال کاهش است، دیر رسیدن به معنای رقابت در چارچوب روایتهایی است که پیشاپیش توسط دیگران تعریف شدهاند.
Exploding Topics پیش از این تغییرات قرار دارد.
این ابزار به شناسایی موضوعات، رفتارها و گفتگوهای نوظهور کمک میکند در حالی که هنوز در حال شکلگیریاند – پیش از اینکه به کلمات کلیدی، خوشههای محتوا و دستهبندیهای محصول تبدیل شوند.
اگر بهدرستی استفاده شود، این فقط یک ابزار روند نیست؛ بلکه روشی برای برنامهریزی پیشدستانه سئو، محتوا، روابط عمومی دیجیتال و جستجوی مبتنی بر اجتماعی است.
این مقاله نحوه استفاده از Exploding Topics برای شناسایی موجودیتهای آینده، اعتبارسنجی آنها از طریق جستجوی اجتماعی، و ایجاد قابلیت دیده شدن در جستجو پیش از اوج تقاضا را تشریح میکند.
از تجزیهوتحلیلهای روند Exploding Topics برای شناسایی موجودیتهای آینده استفاده کنید – نه فقط موضوعات
اکثر بازاریابانی که از Exploding Topics استفاده میکنند، ارزش آن را برای ایدهپردازی محتوا درک میکنند و ما این را پوشش میدهیم.
اما فرصت بزرگتر آن، شناسایی موجودیتهای آینده است – مفاهیمی که موتورهای جستجو و سیستمهای هوش مصنوعی بهزودی بهعنوان «اشیاء» متمایز تشخیص خواهند داد، نه صرفاً بهعنوان تغییرات کلمه کلیدی.
این مهم است زیرا جستجوی مدرن دیگر صرفاً بر پایه کلمات کلیدی عمل نمیکند.
مرورهای هوش مصنوعی گوگل، ChatGPT و سایر سامانههای مبتنی بر مدلهای زبانی بزرگ (LLM) اطلاعات را حول موجودیتها و روابط سازماندهی میکنند.
بهمحض اینکه یک موجودیت تثبیت شود، روایت پیرامون آن سفت میشود.
اگر دیر رسیدید، در قصهای که پیشاپیش تعریفشده رقابت میکنید.
Exploding Topics به شما دیدگاهی کافی میدهد تا قبل از وقوع این اتفاق، اقدام کنید.
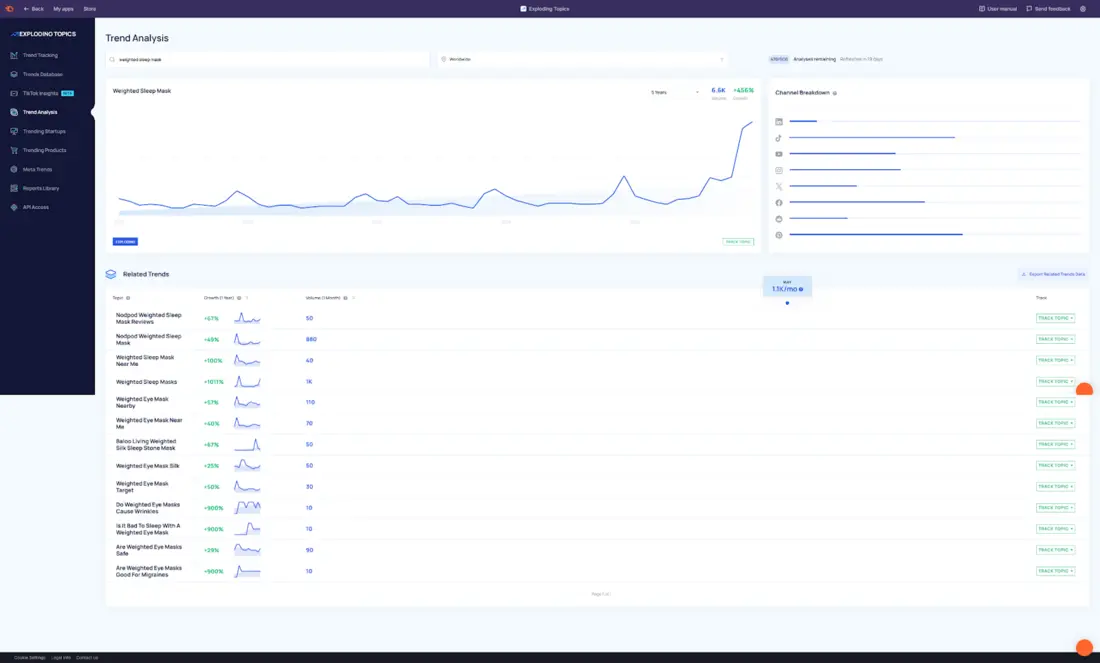
مثال: ماسکهای خواب وزندار
در Exploding Topics ممکن است متوجه افزایش پیوسته «ماسک خواب وزندار» شوید.
حجم جستجو هنوز پایین است و اکثر ابزارهای کلمه کلیدی اهمیت آن را کمارزش میدانند.
در نگاه اول بهنظر میرسد این یک روند محصول خاص است که بهسادهگی میتوان آن را نادیده گرفت.
اگر دقیقتر نگاه کنید، سیگنالها قویتر میشوند:
عبارت ثابت و قابل تکرار است.
موضوعات مرتبط در کنار آن رو به رشد هستند، از جمله خواب با فشار عمیق، ابزارهای خواب برای اضطراب، و تحریک عصب واگ.
سؤالاتی که نشانگر قصد هستند، در حال افزایش است.
گفتگوهای اولیه بر درک مفهوم تمرکز دارند، نه صرفاً خرید محصول.
این نقطهای است که چیزی از یک محصول توصیفی به یک راهحل نامدار تبدیل میشود؛ به عبارت دیگر، در حال تبدیل شدن به یک موجودیت است.
رویکرد سنتی
اکثر برندها صبر میکنند تا:
تقاضای جستجو واضح شود، در دسامبر ۲۰۲۵ اقدام کنند نه در ژوئیه ۲۰۲۵.
رقبا صفحات محصول اختصاصی راهاندازی کنند.
وابستگان و ناشران محتواهای «بهترین» و «مقابل» را منتشر کنند.
فقط پس از آنها ایجاد میکنند:
یک صفحه دستهبندی.
مقالهای با عنوان «ماسک خواب وزندار چیست؟» یا فعالسازی جستجوی اجتماعی.
محتوای سئو طراحیشده برای جلب حضور، مانند سؤالات متداول (FAQ)، ویژگیهای SERP و رتبهبندیها.
در این مقطع، موجودیت قبلاً وجود دارد و روایت پیرامون آن عمدتاً توسط شخص دیگری نوشته شده است.
در این مورد، NodPod بهوضوح بر موجودیت تسلط دارد.
اقدام زودتر، در حال شکلگیری موجودیت
استفاده مؤثر از Exploding Topics به معنای اقدام زودتر است، در حالی که موجودیت هنوز تعریف میشود. بهجای شروع با صفحه محصول، شما:
یک توضیح واضح و معتبر از این که ماسک خواب وزندار چیست، منتشر میکنید.
توضیح میدهید چرا فشار عمیق میتواند در بهبود خواب و اضطراب مؤثر باشد.
به مخاطبان هدف بپردازید – کسانی که برایشان مناسب است و کسانی که نیست.
محتوای پشتیبانیکنندهای ایجاد کنید که زمینه بیشتری میدهد، مانند مقایسه با پتوهای وزندار یا نکات ایمنی.
این کار میتواند بهسرعت و در مقیاس بزرگ از طریق روابط عمومی واکنشپذیر و فعالسازیهای جستجوی اجتماعی انجام شود.
شما هنوز برای بهینهسازی کلمات کلیدی اقدام نمیکنید.
شما به الگوریتمهای اجتماعی، موتورهای جستجو و سیستمهای هوش مصنوعی میآموزید که این مفهوم چه معنایی دارد و برند خود را از ابتدا با این توضیح مرتبط میکنید.
این همان روشی است که برندها میتوانند در جستجو در سال ۲۰۲۶ و پس از آن موفق شوند.
این رویکرد پیشدستانه و زودهنگام:
به سیستمهای جستجو کمک میکند تا مفاهیم جدید را سریعتر درک کنند.
احتمال بازاستفاده از چارچوب شما در پاسخهای تولید شده توسط هوش مصنوعی را افزایش میدهد.
برند شما را بهعنوان مرجع در مورد این موجودیت موقعیت میدهد – نه تنها بهعنوان فروشندهای در گفتگو.
بیشتر بررسی کنید: فراتر از گوگل: چگونگی تدوین یک استراتژی جستجوی جامع
اعتبارسنجی موجودیتهای نوظهور از طریق جستجوی اجتماعی
شناسایی یک موجودیت نوظهور تنها گام نخست است.
ریسک واقعی، نه تنها زود بودن در یک گفتوگو، بلکه زود بودن برای چیزی است که هرگز به اوج نمیرسد.
در اینجا بسیاری از تیمهای سئو متوقف میشوند.
آنها منتظر حجم جستجو میمانند و دیر میرسند، بر اساس احساس منتشر میکنند و امید دارند تقاضا دنبال کند، یا تحت عدم اطمینان سر میفشارند و کاری انجام نمیدهند.
یک میانه بهتر وجود دارد: اعتبارسنجی موجودیتهای نوظهور از طریق تحقیق و آزمونهای فعالسازی جستجوی اجتماعی پیش از بزرگمقیاس کردن آنها در سئو اختصاصی و تجربههای داخلی.
Exploding Topics ساده است. آن نشان میدهد چه چیزی ممکن است مهم باشد. پلتفرمهای اجتماعی به شما میگویند آیا مخاطبانتان واقعاً به آن اهمیت میدهند.
چگونه جستجوی اجتماعی لایه اعتبارسنجی شما میشود
پس از آنکه Exploding Topics یک موجودیت نوظهور بالقوه را نمایان میکند، گام بعدی Keyword Planner نیست.
جستجوی بومی در پلتفرمهایی مانند TikTok، Reddit و YouTube است که با استفاده از ابزارهای روند داخلی یا جستجوی ساده پلتفرم انجام میشود.
شما به دنبال سیگنالهای زیر هستید:
چندین سازنده محتوا بهصورت مستقل همان مفهوم را توضیح میدهند.
بخشهای نظرات پر از سؤالاتی مانند «آیا واقعاً کار میکند؟» یا «آیا ایمن است؟» است.
چارچوبها، استعارهها یا نمایشهای تکراری.
محتوای ابتدایی آموزش یا مقایسه، حتی اگر کیفیت تولید پایین باشد.
این سیگنالها نشانگر نیت هستند.
کنجکاوی به درک تبدیل میشود.
تاریخاً، این فاز همیشه پیش از تقاضای قابلتجزیه در جستجو بوده است.
بازنگری مثال ماسک خواب وزندار
پس از مشاهده «ماسک خواب وزندار» در Exploding Topics، میتوانید آن را در TikTok جستجو کنید.
آنچه میخواهید ببینید، عدم وجود تبلیغات سنگین برند است.
پیشنهادهای تجاری پیشرفته یا مسیرهای TikTok Shop نشان میدهد بازار قبلاً تثبیت شده است.
بهجای آن، به دنبال سازندگان محتوا – نه کانالهای برند – باشید که محصولات را آزمایش میکنند، راهحلها را بررسی میکنند و به مشکل اساسی میپردازند.
روی ویدیوهایی تمرکز کنید که دردها، نیازها و انگیزهها را توضیح میدهند، مانند اینکه چرا فشار میتواند به اضطراب کمک کند.
نظرات را برای مقایسه با دیگر راهحلها بررسی کنید.
به سؤالات مطرحشده در ویدیوها و بخشهای نظرات توجه کنید.
ابزاری مثل Buzzabout.AI میتواند این کار را در مقیاس بزرگ از طریق تحلیل موضوعات و پژوهشهای کمکدست هوش مصنوعی انجام دهد.
این سیگنالها به دو سؤال کلیدی پاسخ میدهند:
آیا افراد فعالانه سعی در درک این مفهوم دارند؟
چه زبان، چارچوب و اعتراضاتی پیش از وجود دادههای سئو شکل میگیرد؟
این همان اعتبارسنجی است.
بازنگری در چگونگی ساخت استراتژی سئو
در اینجا است که استراتژی جستجو تغییر میکند.
بهجای پرسیدن «آیا حجم کافی برای توجیه … وجود دارد؟»، سؤال بهتر این است: «آیا کنجکاوی کافی برای توجیه ساختن اعتبار پیش از موعد وجود دارد؟»
اگر سیگنالهای اجتماعی ضعیف باشند:
متوقف شوید.
ریسک را با آزمایش با سازندگان محتوا خارج از کانالهای خودتان کاهش دهید.
از سرمایهگذاری سنگین در محتواهایی که ماهها طول میکشد تا رتبه بگیرد، اجتناب کنید.
اگر سیگنالها قوی باشند:
با اطمینان گسترش دهید.
با سازندگان همکاری کنید و کانالهای برند را فعال کنید.
در صفحات موجودیت، هابها، سؤالات متداول، مقایسات و بهینهسازی صفحات لیست محصول (PLP) سرمایهگذاری کنید.
در این مدل، پلتفرمهای اجتماعی پرسرعت لایه آزمایش میشوند.
سئو آزمایش نیست؛ بلکه لایه ترکیبی (تراکمساز) است.
بیشتر کاوش کنید: محتوای تولید شده توسط کاربران (UGC) و رسانههای اجتماعی: موتورهای اعتماد که جستجو را در همهجا قدرت میدهند
روابط عمومی دیجیتال تحریریهای که لینکها و ارجاعات مدلهای زبانی بزرگ (LLM) را بهدست میآورد
اکثر روابط عمومی دیجیتال هنوز بهصورت معکوس عمل میکند.
یک روند به شناخت عمومی میرسد.
روزنامهنگاران درباره آن مینویسند.
برندها به سرعت برای اظهار نظر میجنگند.
تیمهای روابط عمومی سعی میکنند لینکها را از داستانی که قبلاً وجود دارد استخراج کنند.
نتیجه، پوشش کوتاهمدت، تأثیر پراکنده و مزیت جستجوی ماندگار کم است.
Exploding Topics امکان معکوس کردن این دینامیک را فراهم میکند؛ با نمایانسازی روایتهای تحریریه پیش از واضح شدن آنها و موقعیتیابی برند شما بهعنوان یکی از منابعی که به تعریف آنها کمک میکند.
در سال ۲۰۲۶، این مورد بیش از پیش اهمیت دارد.
لینکها همچنان مهم هستند، اما دیگر تنها نتیجهای که ارزش دارد، نیستند.
منشنهای برند، توضیحات و ارجاعها بهصورت فزایندهای به سامانههای پشت مرورهای هوش مصنوعی، ChatGPT، Perplexity و دیگر تجربه های کشف مبتنی بر مدلهای زبانی بزرگ (LLM) تغذیه میکنند.
چرا روایتهای پیشدستانه نسبت به روابط عمومی واکنشپذیر برتری دارند
وقتی یک موضوع در همهجا حضور دارد، روزنامهنگاران در حال تجمیع اطلاعات هستند. وقتی یک موضوع در حال ظهور است، هنوز سؤالات میپرسند.
Exploding Topics مفاهیم را در مرحلهای نشان میدهد که:
هنوز روایت توافقنظر وجود ندارد.
تعاریف یکنواخت نیستند.
روزنامهنگاران بهدنبال وضوح هستند، نه نقلقول.
داستانهای «این چه چیزی است؟» هنوز نوشته نشدهاند.
این همان نقطهای است که برندها میتوانند از نظر دادن به یک گفتوگو به شکلدادن به آن تغییر مسیر دهند.
از جاک کننده روند به صاحب روایت
بهجای ارائه «دیدگاه برند ما درباره X»، با سیگنالهای ابتداییای که میبینید، دلایل ظهور این مفهوم در حال حاضر و آنچه درباره رفتار مصرفکننده یا بازار نشان میدهد، پیشقدم میشوید.
تفاوت جزئی اما مهم است.
شما دیگر به پوششهایی که از پیش وجود دارد واکنش نشان نمیدهید.
شما چارچوبی میسازید که روزنامهنگاران، ناشران و در نهایت سامانههای هوش مصنوعی از آن استفاده میکنند.
مدلهای زبانی بزرگ (LLM) تنها از رتبهبندیها یاد نمیگیرند.
آنها از زمینه تحریریه، توضیحات تکراری و چگونگی توصیف و تعریف مفاهیم نوظهور توسط نشریات معتبر، در طول زمان یاد میگیرند.
اگر بهطور مستمر این رویکرد اعمال شود، ترکیب میشود.
همانگونه که برند شما با شناسایی و توضیح روایتهای نوظهور در مراحل اولیه مرتبط میشود، از نظرات واکنشی به منبع معتمد تبدیل میشوید.
روزنامهنگاران شروع میکنند به شناسایی منبع بینشهای مفید میپردازند و این اعتماد در پوششهای برجستهتر در آینده ادامه مییابد. شما دیگر برای حضور خود درخواست نمیکنید.
دیدگاه شما بهطور فعال درخواست میشود.
نتیجه، مالکیت پیشدستانه روایت و دسترسی قویتر زمانی که پوشش گستردهتر میآید، است.
پنجره تحریریهای پیش از پوشش گسترده
پیش از آنکه «ماسک خواب وزندار» به عنوان یک اصطلاح پر ازدحام در تجارت الکترونیک اوایل ۲۰۲۵ تبدیل شود، یک پنجره تحریریهای واضح وجود داشت.
روزنامهنگاران هنوز داستانهایی منتشر نکرده بودند که میپرسند:
«ماسک خواب وزندار چیست؟»
«آیا ماسکهای خواب وزندار ایمن هستند؟»
«آیا واقعاً برای اضطراب مؤثر هستند؟»
این همان فرصت بود.
یک رویکرد مبتنی بر روابط عمومی در این مرحله شامل میشود:
ارائه توضیحات تخصصی به روزنامهنگاران درباره فشار عمیق و خواب.
بهاشتراکگذاری دیدگاههای اولیه درباره دلیل ظهور این دستهبندی محصول.
ارائه زمینه در کنار پتوهای وزندار و سایر ابزارهای اضطراب.
نتیجه فقط پوشش نیست. این اتصال روابط عمومی به جستجو، کنجکاوی و کشف است که با کمک به تعریف خود مفهوم، ارتباط برقرار میکند.
این کار لینکها را بهدست میآورد، اشارههای برند را میسازد و اختیار را در اطراف موجودیتهای نوظهور که مدلهای زبانی بزرگ (LLM) بهمرور زمان بیشتر بهاستناد میگیرند و خلاصه میکنند، نشان میدهد.
بیشتر بررسی کنید: چرا روابط عمومی برای دیده شدن در جستجوی هوش مصنوعی اهمیت بیشتری پیدا میکند
نقشههای محتوایی و بریفهایی که به حجم جستجو وابسته نیستند
حجم جستجو نقطه شروع ضعیفی برای بریفسازی محتوا است.
این فقط علاقه را پس از تثبیت یک موضوع، تثبیت زبان و پر شدن SERP نشان میدهد.
استفاده از آن بهعنوان ورودی اصلی، تیمها را به دنبال کردن تقاضا میکشاند بهجای ساختن اعتبار.
به همین دلیل است که بسیاری از برندها سال بهسال پست «X چیست؟» را بازنویسی میکنند.
بریفهای بهتر در بالا سطر (بالای جریان) آغاز میشوند.
آنها از Exploding Topics برای شناسایی آنچه در حال شکلگیری است و از جستجوی اجتماعی برای درک چگونگی تلاش مردم برای فهمیدن آن استفاده میکنند.
بازتعریف فرایند بریفسازی
تغییر اصلی، حرکت از بریفهای مبتنی بر کلمات کلیدی و حجم به بریفهای مبتنی بر نیت مخاطب است.
به این معنی است که بر سه نکته تمرکز کنید:
مشکلاتی که مردم شروع به بیان آنها میکنند.
مفهومهایی که هنوز بهصورت واضح تعریف نشدهاند یا مورد بحث فعال قرار دارند.
زبانی که ناهمسان، احساسی یا اکتشافی است.
زمانی که محتوا به این روش مطرح میشود، هدف تغییر میکند.
دیگر «ایجاد X برای رتبهبندی Y» نیست.
بلکه «X را توضیح دهید تا مخاطب Y را تجربه نکند».
این تغییر مهم است.
طراحی محتواای که ترکیب میشود بهجای اینکه منقضی شود
هدف تیمهای محتوای سئو در سال ۲۰۲۶ و پس از آن باید تهیه بریف محتوا باشد که یک مفهوم را بهوضوح تعریف کند. این شامل:
اتصال آن به ایدههای مرتبط.
مقایسه آن با راهحلهای موجود.
پاسخ به سؤالات در گفتوگوهایی که هنوز در حال شکلگیری هستند.
این همیشه نیازی به محتوای نوشتاری ندارد.
همین کار میتواند از طریق فعالسازیهای جستجوی اجتماعی یا روابط عمومی دیجیتال انجام شود.
اگر به این شکل مورد استفاده قرار گیرد، محتوا به جای تعقیب تقاضا، خود را به سمت تقاضا میسازد.
بهجای بازنویسی هر بار که حجم جستجو تغییر میکند، از طریق بهروزرسانیها، گسترش و در صورت امکان، پیوند داخلی قویتر پیشرفت میکند.
بهمحض رشد علاقه، محتوا نیازی به جایگزینی ندارد؛ فقط بهرفع نقاط ضعف نیاز دارد.
این همان نوع مطالبی است که هوش مصنوعی و مدلهای زبانی بزرگ (LLM) تمایل دارند به آن استناد کنند – بهموقع، واضح، توضیحی و مبتنی بر سؤالات واقعی.
انتشار پایان کار نیست
منتشر کردن و انتظار برای رتبهبندی محتوا دیگر پایان بریف نیست.
تیمها به برنامه واضحی برای توزیع و بازاستفاده نیاز دارند.
برای موضوعات نوظهور، این به معنای ارائه بینش در پستهای مرتبط Reddit، جوامع Discord، انجمنهای تخصصی و بخشهای نظرات سازندگان است.
نه برای گذاشتن لینکها، بلکه برای پاسخ به سؤالات، به اشتراکگذاری توضیحات، و آزمایش چارچوب در عموم.
این گفتوگوها بهصورت بازخوردی به خود محتوا برمیگردند، وضوح را بهبود میبخشند و احتمال این را افزایش میدهند که توضیح شما توسط دیگران تکرار شود.
با رویکرد فعالسازی جستجوی اجتماعی، برندها میتوانند پیامگذاری را بهسرعت مقیاسبندی کنند، از طریق همکاری با شرکایی که بریف را به صدای خود تفسیر و توزیع میکنند.
وقتی این کار انجام شود، محتوای سئو دیگر ایستای نیست و بهجای آن مانند نقطهمرجع زنده عمل میکند – نقطهای که به فرهنگ کمک میکند و شناختی پایدار برای برند میسازد.
بیشتر کاوش کنید: فراتر از قابلمشاهده در SERP: ۷ معیار موفقیت برای جستجوی ارگانیک در سال ۲۰۲۶
جایی که این وضعیت سئو را در سال ۲۰۲۶ میگذارد
تقاضای جستجو بهصورت کامل شکل نگرفتهاست.
این در پلتفرمهای اجتماعی، جوامع و کشف مبتنی بر هوش مصنوعی توسعه مییابد، خیلی پیش از اینکه بهعنوان حجم کلیدواژه ثبت شود.
Exploding Topics به نمایانسازی آنچه در حال ظهور است کمک میکند.
جستجوی اجتماعی نشان میدهد آیا مردم سعی در فهمیدن آن دارند یا نه.
روابط عمومی دیجیتال به شکلدادن به نحوه تعریف و ارجاع به این ایدهها کمک میکند.
سئو بهوسیله تقویت روایتهای در حال شکلگیری ترکیب میشود، نه اینکه پس از وقوع سعی در آزمون یا ابداع آنها داشته باشد.
در این مدل، سئو لایهای است که بینشهای ابتدایی و توضیح واضح را به قابلیت دیده شدن پایدار در گوگل، پلتفرمهای اجتماعی و پاسخهای تولیدشده توسط هوش مصنوعی تبدیل میکند.
جستجو دیگر از گوگل شروع نمیشود. تیمهایی که بر این واقعیت عمل میکنند، بر آنچه مردم بعداً جستجو میکنند، تأثیر میگذارند.
تاکتیکهای قدیمی سئو که برای رتبهبندی و کلیکها ساخته شدهاند، در نمایشهای هوش مصنوعی و SERPهای بدون کلیک کارایی ندارند. بیاموزید چگونه با سئوی اولویت دیدهبانی، بهینهسازی موجودیتها و محتوای آماده برای پاسخ، سازگار شوید.
بحث و جدل دربارهٔ وضعیت جستجو باعث اضطراب شما در مورد سئو و آیندهٔ آن میشود. به نظر میرسد نیمی از کارشناسان اصرار دارند که هیچچیزی تغییر نکرده است، در حالی که نیم دیگر سئوی هوش مصنوعی را گویی شاهد یک تحول کامل در جستجوی ارگانیک هستیم.
در میان این شلوغی، تشخیص آنچه واقعی است و آنچه بیش از حد بزرگنمایی شده دشوار است.
حقیقت؟ جستجو در حالتغییر است. اما شاید بهقدر که ترسیدهاید، تغییر نکرده باشد.
بله، تقریباً ۶۰٪ از جستجوها در سال ۲۰۲۵ بدون کلیک باقی ماندهاند. با این حال حجم جستجوی گوگل ثابت است. بر اساس گزارش Datos State of Search برای سهماههٔ سوم ۲۰۲۵، گوگل حدود ۹۵٪ از تمام پرسوجویهای دسکتاپ در این دوره را تشکیل میدهد.
کاربران هنوز به همان اندازه به گوگل مراجعه میکنند، اما نمایشهای هوش مصنوعی هدف جستجو را برآورده میکنند و کلیکها را از سایت شما میگیرند. به علاوه، ویژگیهای صفحهٔ نتایج جستجو (SERP) مانند اسنیپتهای ویژه و پنلهای دانش اغلب بالاترین جایگاهها را در نتایج جستجو به خود اختصاص میدهند.
پس متخصصان سئو برای حفظ relevance در جستجو چه میکنند؟ آنها تاکتیکهای سنتی را رها نمیکنند تا بهصورت انحصاری بر سئوی هوش مصنوعی تمرکز کنند. در عوض، تلاشهای بهینهسازی سنتی را ادامه میدهند و همزمان بر سئوی اولویت دیدهبانی تمرکز میکنند — دو جنبهٔ جستجو را به
دکتر سئوس تقریباً ۷۰۰٬۰۰۰ دنبالکننده جدید در تیکتاک و اینستاگرام بهدست آورده است، بهواسطهٔ انتشار تازهترین محتوای اجتماعی که در آن گریچ زنده بهعنوان شخصیت اصلی حضور دارد. (AD AGE COMPOSITE: @DRSEUSS)
رویکرد چندسرعتهای را بیاموزید که هویت موجودیت را تقویت میکند، اعتماد الگوریتمی را میسازد و نمایانی شما را در نتایج محرک هوش مصنوعی افزایش میدهد.
ما رزومه هوش مصنوعی را بهعنوان دارایی جدید در سطح C‑suite معرفی کردهایم که برند شما را در انتهای قیف تعریف میکند، و چشمانداز استراتژیک را ترسیم کردهایم که نشان میدهد این رزومه در حالتهای تحقیق صریح، ضمنی و محیطی چگونه عمل میکند.
پس، چگونه میتوانید این دارایی را بسازید تا در محیط سهبخشی بهخوبی رشد کند؟
پاسخ این است که از رتبهبندی در نتایج جستجو به سمت حوزه آموزش الگوریتمی متمرکز بر برند حرکت کنید – استراتژی چندسرعتهای که با سه فناوری اصلی محرک تمام موتورهای توصیهگر مدرن هماهنگ است.
اکوسیستم بازاریابی دیجیتال توسط موتورهای کمکی هوش مصنوعی بازآفرینی شده است – پلتفرمهایی مثل Google AI، ChatGPT و Microsoft Copilot که دیگر لینکهای ساده ارائه نمیدهند، بلکه پاسخهای ترکیبی و گفتوگویی میسازند.
درک چگونگی تأثیرگذاری بر این موتورها، مرز نوینی برای صنعت ماست.
گفتوگوهایی که در سال ۲۰۲۰ با گری ایلیس در گوگل و با فریدریک دوبوت، ناتان چالمرز و فابریس کانل در بینگ داشتم نشان داد که این موتورها – و بهطور گستردهتر هوش مصنوعی مدرن – همگی بر سه فناوری بنیادی یکسان تکیه دارند.
من این را تثلیث الگوریتمی مینامم. تسلط بر آن کلید موفقیت آینده شماست.
تثلیث الگوریتمی: سیستمعامل جدید برای جستجو
از این که گوگل یا ChatGPT را بهعنوان جعبههای سیاه تکقطبی در نظر بگیرید، دست بکشید.
بهجای این، آنها را ترکیبی پویا از سه فناوری مرتبط ببینید.
هر موتور کمکی هوش مصنوعی از ترکیبی منحصربهفرد از این اجزا ساخته شده است.
موتورهای جستجوی سنتی
این پایه – فهرست گسترده و زنده وب است.
این اطلاعات تازه و بهروز را که هوش مصنوعی برای پاسخ به سؤالهای درباره رویدادهای جاری یا موضوعات خاص نیاز دارد، فراهم میکند؛ بهعبارتدیگر، پنجره موتور به «این لحظه» است.
گرافهای دانش
این مغز هوش مصنوعی است – یک دانشنامه ماشینی که حقایق تأییدشده دربارهٔ دنیا را در اختیار دارد.
گراف دانش گوگل حداقل ۱۰,۰۰۰ برابر بزرگتر از ویکیپدیا است.
در همین مکان هویت اصلی برند شما ذخیره میشود. این اطلاعات قطعیت واقعی و زمینهای را که هوش مصنوعی برای جلوگیری از توهم نیاز دارد، فراهم میکند.
مدلهای بزرگ زبانی (LLMها)
این صدای هوش مصنوعی است – رابط گفتوگویی که متن شبیه به انسان تولید میکند.
LLM اطلاعات را از فهرست جستجو و گراف دانش ترکیب میکند تا پاسخ نهایی که به کاربر ارائه میشود را تولید کند.
استراتژی برند شما باید در سه بازهٔ زمانی عمل کند
هر بخش از تثلیث الگوریتمی به سرعت متفاوتی آموزش میبیند و بهروز میشود، که به این معناست که استراتژی بهینهسازی شما باید لایهبندی شود.
استراتژیهای کوتاهمدت و هدفهای بلندمدت باید با «سرعت هضم» فنی هر مؤلفه هماهنگ شوند.
کوتاهمدت (هفتهها): بر نتایج جستجو غلبه کنید
تأثیر بر نتایج جستجوی سنتی سریعترین مسیر شما به سمت نمایان شدن است.
با ایجاد محتواهای مفید و ارزشمند و بستهبندی آن برای گوگل با تکنیکهای ساده سئو، میتوانید در عرض چند هفته در نتایج جستجوهای مبتنی بر هوش مصنوعی ظاهر شوید.
اگرچه این کار اعتماد عمیق را نمیسازد، برند شما را در مجموعه تصمیمگیری زمان واقعی قرار میدهد؛ مجموعهای که موتورهای کمکی هوش مصنوعی برای ساختن پاسخها به پرسشهای خاص یا حساس به زمان از آن استفاده میکنند.
بهعنوان مثال، نکات گفتوگوی روزانه و پاسخهای فوقالخصوصی خود را به گفتوگو میآورید.
میانمدت (ماهها): ساخت پایهٔ واقعی
آموزش گراف دانش راهی برای ساختن رکورد دائمی و واقعی شماست، فرایندی که معمولاً سه تا شش ماه طول میکشد.
این کار مستلزم ایجاد خانهٔ موجودی شما – منبع نهایی حقیقت دربارهٔ شما – و تولید اطلاعات مستمر و تأییدی در تمام ردپای دیجیتالیتان است.
وقتی که درک بنیادی گوگل از من نادرست بود («صدای بووا، سگ آبی») باعث شد فرصتهای بیشماری از دست برود.
این همان کاری است که آن خطاها را اصلاح میکند.
دورهٔ بلندمدت (سالها): تبدیل شدن به دادهٔ اساسی
هدف نهایی گنجاندن در دادههای آموزشی اساسی یک LLM است.
این بازی طولانیمدت است، معمولاً نه ماه تا یک سال یا بیشتر.
به این معناست که روایت، تخصص و اقتدار برند شما بهقدر کافی بهصورت مداوم در سراسر وب حضور داشتهاند که در دورهٔ آموزشی بزرگ بعدی گنجانده میشوید.
بهمحض این که بخشی از آن دانش اساسی شوید، هوش مصنوعی نیازی به «جستجوی شما» ندارد؛ پیشاز این، او شما را میشناسد.
این قلهٔ مقدس اقتدار الگوریتمی است.
اصل یکپارچهسازی: موجودیت و اقتدار
چه هدف شما دستیابی به پیروزی کوتاهمدت در نتایج جستجو باشد و چه هدف ماندگار بلندمدت در یک LLM، نیاز اساسی یکسان است. الگوریتم همیشه سه سؤال میپرسد:
این موجودیت کیست؟
آیا میتوانم به او اعتماد کنم؟
آیا او یک مرجع است؟
به همین دلیل استراتژی شما باید بر پایهٔ بنیاد SEO موجودیتی، N‑E‑E‑A‑T‑T – گسترش من از چارچوب E‑E‑A‑T گوگل که بهنویسیت و شفافیت میافزاید – و بر پایهٔ اقتدار موضوعی بنا شود.
هر سیگنالی که در سراسر اکوسیستم دیجیتال خود ایجاد میکنید باید برای پاسخ به این سه سؤال با وضوح و دلایل قاطع عمل کند.
مرزهای آینده: باغهای حصاردار هوش مصنوعی و عوامل کمکی هوش مصنوعی
بازی در حال تکامل است. هوش مصنوعی از صرفاً پاسخ دادن به پرسشها فراتر رفته و برای ما اقدام میکند.
من این را بهطور مستقیم تجربه کردم وقتی از ChatGPT برای خرید پدالهای گیتار استفاده کردم.
در عرض ۱۵ دقیقه، او مرا از شناخت به تصمیمی مطمئن و خرید نهایی رساند. او همچون دستیار شخصی خرید من عمل کرد.
این آیندهٔ عوامل کمکی هوش مصنوعی است.
بهزودی، عوامل بهصورت خودکار پروازها را رزرو، قرارهای ملاقات را زمانبندی و محصولات را خریداری خواهند کرد.
برای اینکه یک عامل بتواند کاری را بهنام شما انجام دهد، اطمینان الگوریتمیاش نسبت به برند نباید بهصورت احتمالی باشد – بلکه باید مطلق باشد.
برندی که عمیقترین پایهٔ فهم و اعتبار را در داخل تثلیث الگوریتمی ساخته باشد، همان برندی است که عامل انتخاب خواهد کرد.
نتیجهٔ کلیدی چیست؟
در این عصر نوین، همانطور که مربی افسانهای فوتبال پیتر رید میگفت: «بیتحرک ماندن همانند عقبرفتن است».
استراتژی دیجیتال شما باید تحول یابد. دنبال پیوندهای آبی نروید و کار آموزش الگوریتمی متمرکز بر برند را آغاز کنید.
کلید این است که درک کنیم فهرست وب سنتی همان سوختی است که بهصورت یکسان به سه مؤلفهٔ تثلیث الگوریتمی نیرو میدهد.
تمام ردپای دیجیتال شما باید بهگونهای سازماندهی شود که برای رباتها بدون اصطکاک قابل کشف، انتخاب، خزش و رندر باشد؛ بهصورت قابل هضم برای استخراج، ایندکسگذاری و حاشیهنویسی مطمئن؛ و برای الگوریتمهای پیرو، بهصورت خوشطعم و جذاب باشد.
«بدون اصطکاک» استراتژی سئو فنی است: این زیرساخت است. اطمینان میدهد ربات میتواند محتوای شما را بدون موانع فنی کشف، انتخاب، خزش و رندر کند.
«قابل هضم» استراتژی سئو معنایی است: این ساختار است. از HTML معنایی، زبان واضح و دادههای ساختاری استفاده میکند تا ربات بتواند محتوا را بهصورت قطعات قابلاعتماد استخراج، ایندکسگذاری و حاشیهنویسی با تقریباً قطعیت انجام دهد.
«خوشطعم» استراتژی برند و اقتدار است: این کیفیت، عمق و زمینهٔ محتواست – بخشی که ثابت میکند چرا شما بهترین پاسخ هستید. این نشاندهندهٔ اقتدار موضوعی شما، تأیید مثبت طرفهای سوم و پژواک واضح برند دیجیتال شماست.
بهطور مهم، الگوریتم N‑E‑E‑A‑T‑T را در سه سطح ارزیابی میکند:
محتوا: آیا این قطعه اطلاعات مفید، دقیق و بهخوبی پشتیبانی شده است؟
نویسنده: آیا فردی که این مطلب را نوشته است یک کارشناس معتبر و قابلاثبات در این موضوع است؟
منتشرکننده: آیا ناشر پلتفرم یک مرجع شناختهشده در این حوزه است؟
چرا لایهٔ حاشیهنویسی تعیینکننده برنده است
این ما را به مهمترین بخش فرایند میرساند.
باید هفت مرحله بنیادین ربات را درک کنید – کشف، انتخاب، خزش، رندر، استخراج، ایندکس و حاشیهنویسی – زیرا این تنها مسیر ورود به فهرست وب و تنها راه برای رسیدن به بالای پشتهٔ تثلیث الگوریتمی است.
همانطور که از گفتگوهایم با کانل از بینگ اطلاع یافتم، مرحلهٔ حاشیهنویسی اساسی است.
الگوریتمها محتوا را با بازخوانی دوباره خود محتوا انتخاب نمیکنند؛ آنها با خواندن حاشیهنویسیها – «یادداشتهای چسبان»یی که ربات ایجاد کرده – انتخاب میکنند.
آنها این حاشیهنویسیها را بر اساس دو عامل اولویت میدهند:
ارتباط آنها با نیاز خاص (پر کردن گراف دانش، گنجاندن در دادههای آموزشی یا پاسخ به پرسش).
امتیاز اطمینان اختصاص داده شده به آنها.
به همین دلیل بخشهای «قابل هضم» و «خوشطعم» استراتژی غیرقابل مذاکره هستند.
کار «قابل هضم» (سئو معنایی) اطمینان میدهد که حاشیهنویسیها از نظر واقعی درست باشند.
کار «خوشطعم» (برند و اقتدار) امتیاز اطمینی ایجاد میکند که تعیین میکند آیا الگوریتم شما را انتخاب میکند یا نه.
برای شکوفایی در فضای صریح، ضمنی و محیطی، باید این استراتژی جامع را اجرا کنید و تبدیل به پاسخ مورد اعتماد و برتر ذهن الگوریتمی شوید.
رزومهٔ هوش مصنوعی – بهویژه آنکه در یک «سوراخ خرگوشی» عمیق از تحقیق صریح ثابت بماند – هدف نیست. این یک محصول جانبی از انجام صحیح کار است.
برندهایی که موفق میشوند، آنهایی خواهند بود که الگوریتمها را بهعنوان موجودات قدرتمند میدانند که باید از طریق یک برنامهدرسی منظم به آنها آموزش داد.
امروز شروع به ساختن این برنامهدرسی کنید، زیرا عوامل کمکی هوش مصنوعی فردا در حال یادگیری هستند.
یک واکنش مخالف هوش مصنوعی در حال شکلگیری است. miniseries/E+/Getty Images
نسخهای از این داستان در خبرنامه Nightcap از CNN Business منتشر شد. برای دریافت آن در صندوق ایمیلتان، رایگان ثبتنام کنید اینجا.
نیویورک —
فرار از «slop»، خوراک مصنوعی تولید شده توسط هوش مصنوعی که بهتدریج به اسلایدهای همکاران، فیدهای رسانههای اجتماعی، رسانههای خبری و حتی لیستهای املاک ما نفوذ کرده است، دشوارتر میشود.
«slop» به همه چیز سرایت میکند، نوشت سردبیران Merriam‑Webster که «slop» را بهعنوان کلمهٔ سال ۲۰۲۵ انتخاب کردند. «مانند لجن، رسوب و کثیف، slop صدای مرطوب چیزی را دارد که نمیخواهید به آن دست بزنید.»
به همین دلیل، لحظهای وقت میگذارم تا به شیشهٔ پیشبینیام نگاه کنم و یکی از آن پیشبینیهای ناخواستهٔ پایانسال را مطرح کنم: سال ۲۰۲۶ سال بازاریابی «صددرصد انسانی» خواهد بود.
به حرف من گوش کنید.
«slop» هوش مصنوعی تمایل دارد تصاویری بیخطر مانند «Shrimp Jesus» یا سریال صابونی گربههای چشمدار را به یاد آورد. اما تصاویر slop در حال پیشرفت هستند و حتی برای ما که با اینترنت بزرگ شدهایم و خود را کارشناس یا حداقل شناسندهٔ نسبتاً ماهر محتوای تقلبی میدانیم، بحران اعتمادی ایجاد میکنند. نشانههای معمول — نورپردازی نامعمول، دستهای نادرست رندر شده، پسزمینههای نامتناسب — بهطور چشمگیری از بین رفتهاند.
یک اسکرول معمولی در TikTok حالا شبیه یک آزمون است: آیا تقلب را شناسایی کردید یا بدون فکر بر روی ویدئوی پر از خرگوشهای پرشکننده روی ترامپولین دو بار ضربه زدم؟ (شما میدانید که فریب خوردهاید! همهٔ ما همینطور شدیم!)
این احساس ناخوشایندی است که فریب خورده باشید. و نشانهای از واکنش مخالف قبلاً آغاز شده است.
ماه گذشته، غول رادیو و پادکست iHeartMedia یک شعار «انسان تضمینشده» را معرفی کرد و به کاربران وعده داد که از «شخصیتهای تولید شده توسط هوش مصنوعی» یا موسیقی تولید شده توسط هوش مصنوعی استفاده نخواهد کرد.
تحقیقات داخلی این شرکت صوتی مستقر در سانآنتونیو نشان داد که ۹۰٪ شنوندگان آن — حتی کسانی که خودشان از ابزارهای هوش مصنوعی استفاده میکنند — میخواهند محتوای خود توسط انسانها تولید شود.
«مهم است که بهعنوان بازاریابان، به یاد داشته باشیم که در موقعیتی بسیار حساس در یک زمان پرآشوب، چه در آمریکا و چه در سراسر جهان، قرار داریم»، باب پیتمن، مدیرعامل iHeartMedia، در بیانیهای در پاییز جاری گفت. «مصرفکنندگان فقط بهدنبال راحتی نیستند — آنها به دنبال معنا هستند.»
یک هنرمند آنقدر از زوال اینترنت خسته شده بود که برنامهٔ مرورگری به نام Slop Evader ایجاد کرد؛ این افزونهٔ مرورگر جستجوهای وب را طوری فیلتر میکند که تنها نتایج پیش از نوامبر ۲۰۲۲ — قبل از انتشار ChatGPT — را نمایش دهد.
نتیجهگیری: ممکن است اشتباه کنم! تا کنون، واکنش مخالف هوش مصنوعی بسیار کوچکتر از مقیاس شرکتهای بزرگ آمریکایی است که معتقدند هوش مصنوعی آیندهٔ کل اقتصاد است. در نهایت، باید ببینیم آیا آزمایشهای بازاریابی ضد هوش مصنوعی بازدهی واقعی دارند یا نه.
با این حال، گمان میکنم هر چه والاستریت و مدیران ارشد بیشتر دربارهٔ درخشش هوش مصنوعی و پتانسیل بیپایان آن برای افزایش بهرهوری و حتی خلاقیت نظردهی کنند، مردم بیشتری آن را تله میدانند.
تا کنون تجربهٔ ما از چتباتها و مولدهای تصویر ترکیبی است. قطعاً، میتواند سرگرمکننده باشد که از سُورا بخواهیم ویدئویی از سگم که با بابانوئل بر فراز آسمانخط پاریس پرواز میکند، بسازد. و بله، گاهی یک چتبات نسبت به جستجوی معمولی وب وقتی به توصیههای سفر نیاز دارید، بهتر عمل میکند. اما این ابزارها همچنین یک تولیدکنندهٔ دیپفیک هستند که میتوانند بهسرعت اطلاعات نادرست را گسترش دهند (همانطوری که Grok از xAI در تیراندازی روز یکشنبه در ساحل باندی انجام داد) و مردم را به توهمات گاهی مرگبار میکشاند.
ممکن است مصرفکنندگان و خلاقان تازه شروع به تسلیم شدن کرده باشند. یا دستکم، برخی چیزها را ترجیح میدهند که هنوز توسط دستهای انسانی ساخته شده باشند.
با تحول ترجیحات مصرفکنندگان، کسبوکارهای کوچک میتوانند در سال نو از این نکات بهرهبرداری کنند تا همگام با آنها پیشرفت کنند.
نظرهای بیانشده توسط همکاران Entrepreneur صرفاً نظرات خودشان است.
نکات کلیدی
محتوای ویدئویی کوتاهمدت دیگر یک گزینهٔ لوکس نیست؛ به یک ضرورت در استراتژیهای بازاریابی تبدیل شده است.
هوش مصنوعی و شخصیسازی، محور اصلی تعامل مدرن با مشتریان هستند؛ ۷۱٪ مصرفکنندگان انتظار دارند تعاملات برند بهصورت شخصیسازی شده باشد.
ادغام اصالت و ساختن جامعه، در کنار سازگاری با رفتارهای جدید جستجو مانند رسانههای اجتماعی و ابزارهای مبتنی بر هوش مصنوعی، برای دیدهشدن و رشد کسبوکار حیاتی است.
با شروع فصل خریدهای تعطیلات، «لحظهٔ حاضر» بهعنوان اوج مصرف و ارتباط سالیانه در پیشصحنه کسبوکارهای هر اندازهای قرار گرفته است. در این دورهٔ شلوغ، صاحبان کسبوکار باید همچنان برای «آنچه بعداً میآید» در ترجیحات مصرفکنندگان آماده باشند.
هوش مصنوعی (AI)، بینشهای مبتنی بر داده، محتوای کوتاهمدت، ایجاد جامعه و موارد دیگر نقش مهمی ایفا خواهند کرد، اما این عوامل چگونه میتوانند برای کارآفرینان شکل بگیرند؟ این چهار روند را در نظر بگیرید تا کسبوکار شما سال بهسال مقصدی مورد طلب مشتریان شود.
درک روندهای محتوا
محتوای ویدئویی از «دارای بودن مفید» به نقطهٔ اصلی بازاریابی مدرن تبدیل شده است. در سال گذشته، ۸۹٪ از کسبوکارها گزارش دادند که از ویدئو بهعنوان ابزار بازاریابی استفاده میکنند، که نسبت به ۶۳٪ در سال ۲۰۱۷ افزایش یافته است؛ اما بسیاری نیز اعلام کردند که با اجرای آن مواجهاند. برای کسانی که یاد میگیرند چگونه بهصورت استراتژیک ویدئو را بپذیرند، فرصت در انتظاری است. چه شما یک کارآفرین تکنفره باشید و چه تیم خود را در حال گسترش داشته باشید، اتخاذ رویکرد «ویدئو اول» توانایی شما برای ارتباط با مخاطبان را فراتر از محتوای متنی یا تصویری ارتقا میدهد.
ویدئوی کوتاهمدت همچنان در پلتفرمهای محبوبی چون یوتیوب، اینستاگرام و تیکتوک حاکم است. قالبهای کوتاهمدت بهعنوان اصلیترین روش تعامل مصرفکنندگان با رسانهها شناخته میشوند. نکتهٔ مثبت این است که برای پیوستن به این روند در حال رشد، نیازی به تولید انبوه برندهای بزرگ نیست.
محتوای اصیل و پشتصحنه که تیم، محصولات یا حل مشکلات شما را نشان میدهد، اغلب نسبت به ویدئوهای بیش از حد صیقلی عملکرد بهتری دارد. کلید موفقیت، تداوم و قرارگیری استراتژیک در پلتفرمهایی است که مخاطبان شما در آن وقت میگذرانند. اینستاگرام و فیسبوک فرصتهایی برای جذب توجه والدین فراهم میکنند، در حالی که یوتیوب به جذب مخاطبان جوانتر میپردازد.
همانطور که در خلق محتوای ویدئویی اعتماد مییابید، خواهید دید که این محتوا بهطبیعیگی ادامهای از روایت برند شما میشود — داستانتان را بهروشهای متفاوتی بیان میکند که هم برای مشتریان فعلی و هم برای کسانی که تازه شما و کسبوکارتان را کشف میکنند، طنیندار میشود.
شخصیسازی از طریق دادهها و فناوری
هوش مصنوعی چگونگی ارتباط ما را تغییر داده است و همچنان در حال تحول است؛ زیرا مصرفکنندگان به دنبال شخصیسازی بیشتری هستند، در حالی که انتظار دارند اصالت همواره در ذهنشان باقی بماند. یک نظرسنجی Deloitte نشان داد که ۷۱٪ از مصرفکنندگان اکنون انتظار تجربههای شخصیسازیشده را دارند و افرادی که این تجربهها را دریافت میکنند، بهصورت وفاداری و هزینه بالاتر به برندها پاداش میدهند.
اما در زمینه فناوری نکتهٔ حیاتی وجود دارد: برندهایی که استاندارد را تعیین میکنند، از هوش مصنوعی صرفاً بهخاطر هوش مصنوعی استفاده نمیکنند. در عوض، هوش مصنوعی را بهطور مثبت میپذیرند و در عین حال رعایت قوانین استفاده از داده و شفافیت را مدنظر دارند.
برای یک کارآفرین، ابزارهای هوش مصنوعی میتوانند راهحلی برای رفع نیاز رو به رشد باشند، نظیر تقسیمبندی لیست ایمیل کسبوکار شما. برای مثال، هوش مصنوعی میتواند بهعمق عادات خرید مصرفکنندگان نگاهی بیندازد که به شما امکان میدهد شخصیسازی ایمیلهای خود را بدون ساعتها کار دستی ارتقا بدهید. اما زمانی که دادهها و فناوری کار سنگین را انجام میدهند و شما صحت آنها را بررسی کردهاید، یک کار نهایی باید تکمیل شود: افزودن لمس شخصی شما برای حفظ صدای اصیل. گاهی این ممکن است نیاز به نگاهی دوباره به اطلاعات، بازگشت به تختهکاغذ یا کاری بسیار سادهتر داشته باشد.
بهعنوان مثال، میتوانید از هوش مصنوعی برای ایجاد پیشنویس اولیهٔ یادداشت قدردانی از مشتری استفاده کنید، اما آن را به لحن خود تنظیم و بهعنوان یادداشت دستی به سفارشها یا پیام ویدئویی شخصی برای مشتریان VIP ارسال کنید. مشتریان تفاوت را احساس میکنند، زیرا ارتباط هوشمندانه و بهموقع همراه با مراقبت واقعی دریافت میکنند. گامهای کوچک، شتاب بزرگ ایجاد میکنند.
ساختن اصالت و جامعه
در دنیایی که بهتدریج آنلاین میشود، ارتباط یک ارزش طلایی است. مردم بهدنبال تعاملات اصیل با برندهایی هستند که ارزشهایشان را بازتاب میدهند و بهصورت مستمر مراقبت واقعی نشان میدهند؛ و نسلهای جوان بهویژه بهسوی ارتباط شفاف و قابلدسترس که معنایی ارائه میدهد، جذب میشوند.
آگهی سینمایی تعطیلاتی فروشگاه UPS با عنوان «تأیید هویت انسانی» بهخوبی این احساس را به تصویر میکشد. این فیلم کوتاه که توسط کارگردان مشهور گیا کوپولا ساخته شده، نشان میدهد چگونه دقت و تفکر عمیق میتواند ارتباطی اصیل ایجاد کند و روح واقعی فصل را در محیط دیجیتالی به تصویر بکشد. شخصیت اصلی داستان به زیباییای میرسد که از انتخاب دقیق یک هدیه برای دریافتکننده حاصل میشود؛ نمادی از خدمات واقعی، شخصی و برنده جوایز فروشگاه UPS.
اگرچه ممکن است به همان ترتیب هدایای فیزیکی به مشتریان ندهید، یک ارتباط طولانیمدت میتواند هدیهای بزرگ باشد که میتوانید ارائه کنید. در سال جدید با حضور پیوسته، پاسخگویی شخصی به سؤالات و نقدهای مشتریان و بهاشتراکگذاری انگیزهٔ واقعی خود برای راهاندازی کسبوکار، جامعهای بسازید. یک قدم فراتر رفته و با کارآفرینان دیگر در پروژههای خیریه یا اجتماعی که با هدف کسبوکار شما همسو هستند (مانند انبار غذا، برنامهٔ مشاورهٔ کودک یا آثار هنری برای یک رویداد) همکاری کنید.
محتوایی که توسط کارمندان شما تولید میشود، اصالت را بیشتر تقویت میکند. وقتی تیم شما تجربیات روزمرهٔ خود را بهعنوان بخشی از شرکت به اشتراک میگذارد، ارزشها، فرهنگ و محصولات شما را از طریق صدای کارشناسان منتقل میکند. مشتریان این روایتهای شخصی را میپسندند؛ زیرا حس میکنند اینها بدون فیلتر و واقعی هستند. رفتن فراتر از پستهای اسکریپتشدهٔ شبکههای اجتماعی، یک سیستم تولید محتوا را به وجود میآورد که توسط افراد واقعی که به کاری که انجام میدهید باور دارند، تغذیه میشود.
دور شدن از جستجوی سنتی
فضای جستجو — موتور کشف مشتریان — بهطور اساسی در حال تحول است. مخاطبان جوانتر (مانند Millennials و Gen Z) اکنون به پلتفرمهای اجتماعی و ابزارهای هوش مصنوعی مولد برای یافتن راهنماییها روی میآورند. در واقع، ۴۱٪ از کاربران Gen Z اکنون بهصورت پیشفرض برای یافتن پاسخها به رسانههای اجتماعی مراجعه میکنند، در مقابل ۳۲٪ که از موتورهای جستجوی سنتی استفاده میکنند. و نیمی از مصرفکنندگان در حال حاضر از جستجوی مبتنی بر هوش مصنوعی استفاده میکنند. این نشاندهندهٔ افزایش وابستگی به محتوا، اینفلوئنسرها و هوش مصنوعی بهعنوان منابع مورد اعتماد اطلاعات است.
پلتفرمهای اجتماعی و ابزارهای جستجوی مبتنی بر هوش مصنوعی امروزه بهعنوان موتورهای کشف برای پیشنهادات محصول، کسبوکارهای محلی و الهامهای سبک زندگی عمل میکنند. برای ارتقاء استراتژی بهینهسازی موتور جستجو (SEO) بهعنوان مالک یک کسبوکار کوچک، باید در جایی که مشتریانتان واقعا بهدنبال هستند، قابلنمایش باشید: در پلتفرمهای اجتماعی که مرور میکنند و در نتایج جستجوی هوش مصنوعی که به سؤالهایشان پاسخ میدهند.
رویکرد برنده ترکیبی از هر دو است. بهعنوان مثال، یک دانشجوی دانشگاه ممکن است از طریق یک ویدئوی TikTok شما را کشف کند، سپس با مرور نقدهای Google Maps اعتبار شما را تأیید نماید و پس از آن از ChatGPT برای دریافت توصیههای مربوط به دستهٔ شما استفاده کند. هر نقطه تماس مهم است.
بهعنوان قدم بعدی، از صحت و نمایان بودن اطلاعات کسبوکار خود در چندین کانال کشف اطمینان حاصل کنید — اینستاگرام، Google Maps، فیسبوک و/یا تیکتوک. مشتریان راضی را تشویق کنید تا تجارب خود را بهاشتراک بگذارند و به نقدها و نظرات بهسرعت پاسخ دهید. این تعامل مستمر به پلتفرمها (و مدلهای هوش مصنوعی) نشان میدهد که شما یک کسبوکار فعال و درگیر هستید که این امر نمایانی شما را بهبود میبخشد و شهرتتان را تقویت میکند.
بازاریابی برای دنیای آینده نیازمند چابکی، اصالت و آمادگی برای پذیرش فناوریهای در حال تحول است، در حالی که ارتباط را حفظ میکند؛ این دقیقاً تعریف سرویس مشتری برتر و به یادماندنی است. خبر خوب این است که کارآفرینان توانایی ذاتی برای انعطافپذیری، پاسخ سریع به روندها و ساختن روابط اصیل در مقیاس بزرگ را دارند.
برتری رقابتی شما از تمایز حاصل میشود. با سرمایهگذاری در این چهار روند بازاریابی، حضوری ایجاد خواهید کرد که مشتریان به یاد میآورند، توصیه میکنند و دوباره بازدید میکنند.
نکات کلیدی
محتوای ویدئویی کوتاهمدت دیگر یک گزینهٔ لوکس نیست؛ به یک ضرورت در استراتژیهای بازاریابی تبدیل شده است.
هوش مصنوعی و شخصیسازی، محور اصلی تعامل مدرن با مشتریان هستند؛ ۷۱٪ مصرفکنندگان انتظار دارند تعاملات برند بهصورت شخصیسازی شده باشد.
ادغام اصالت و ساختن جامعه، در کنار سازگاری با رفتارهای جدید جستجو مانند رسانههای اجتماعی و ابزارهای مبتنی بر هوش مصنوعی، برای دیدهشدن و رشد کسبوکار حیاتی است.
با شروع فصل خریدهای تعطیلات، «لحظهٔ حاضر» بهعنوان اوج مصرف و ارتباط سالیانه در پیشصحنه کسبوکارهای هر اندازهای قرار گرفته است. در این دورهٔ شلوغ، صاحبان کسبوکار باید همچنان برای «آنچه بعداً میآید» در ترجیحات مصرفکنندگان آماده باشند.
هوش مصنوعی (AI)، بینشهای مبتنی بر داده، محتوای کوتاهمدت، ایجاد جامعه و موارد دیگر نقش مهمی ایفا خواهند کرد، اما این عوامل چگونه میتوانند برای کارآفرینان شکل بگیرند؟ این چهار روند را در نظر بگیرید تا کسبوکار شما سال بهسال مقصدی مورد طلب مشتریان شود.
با تحول ترجیحات مصرفکنندگان، کسبوکارهای کوچک میتوانند در سال نو با بهرهگیری از این نکات، همراه این تغییرات پیشرفت کنند.
نظراتی که توسط نویسندگان Entrepreneur بیان میشوند، متعلق به خودشان است.
نکات کلیدی
محتوای ویدئوی کوتاهمدت از یک گزینهٔ لوکس به یک ضرورت در استراتژیهای بازاریابی تبدیل شده است.
هوش مصنوعی و شخصیسازی، اساسیترین عوامل تعامل مدرن با مشتریان هستند؛ بهطوریکه ۷۱٪ مصرفکنندگان انتظار دارند تعاملات برند بهصورت شخصیسازیشده باشد.
یکپارچهسازی اصالت و ساخت جامعه، بههمراه سازگاری با رفتارهای جدید جستجو همچون شبکههای اجتماعی و ابزارهای مبتنی بر هوش مصنوعی، برای دیده شدن و رشد کسبوکار حیاتی است.
با شروع فصل خریدهای تعطیلات، لحظهٔ حاضر که اوج مصرف و ارتباط سال را نشان میدهد، در مرکز توجه کسبوکارهای همهاندازه قرار دارد. در میان این فصل شلوغ، صاحبان کسبوکار باید برای «چیزی که بعداً میآید» در ترجیحات مصرفکنندگان هم آماده باشند.
هوش مصنوعی (AI)، بینشهای مبتنی بر دادهها، محتوای کوتاهمدت، ساخت جامعه و موارد دیگر نقش ایفا خواهند کرد، اما اینها برای کارآفرینان چگونه میتوانند شکل بگیرند؟ این چهار روند را در نظر بگیرید تا کسبوکار خود را سال بهسال به مقصدی موردتقاضای مشتریان تبدیل کنید.
مرتبط: آمریکاییها در این فصل تعطیلات ۹۷۹ میلیارد دلار هزینه میکنند — اینجا نشان میدهیم که کسبوکار شما چگونه میتواند سهم بزرگتری از این هزینهها بهدست آورد
درک روندهای محتوا
محتوای ویدئویی از وضعیت «خوشایند برای داشتن» به ستون فقرات بازاریابی مدرن تبدیل شده است. در سال گذشته، ۸۹٪ کسبوکارها گزارش دادند که از ویدئو بهعنوان ابزار بازاریابی استفاده میکنند، که نسبت به سال ۲۰۱۷ که فقط ۶۳٪ بود، افزایش چشمگیری است؛ اما بسیاری نیز از مشکلات اجرایی رنج میبرند. برای کسانی که یاد میگیرند ویدئو را بهطور استراتژیک بپذیرند، فرصت در انتظار است. چه یک کارآفرین تکنفره باشید و چه تیمتان را در حال گسترش، اتخاذ رویکرد اولویتدادن به ویدئو، توانایی شما را برای ارتباط با مخاطبان بهطوری فراتر از محتوای صرفاً متنی یا تصویری تقویت میکند.
ویدئوی کوتاهمدت همچنان در پلتفرمهای محبوبی همچون یوتیوب، اینستاگرام و تیکتوک تسلط دارد. فرمتهای کوتاهحجم اکنون اصلیترین روش مصرفکنندگان برای تعامل با رسانهها هستند. بهترین نکته این است که برای پیوستن به این روند رو به رشد، نیازی به تولید بزرگمقیاس برندهای بزرگ نیست.
محتوای صادقانه و پشت‑صحنه که تیم، محصولات یا حلمسئلههای شما را به نمایش میگذارد، اغلب نسبت به ویدئوهای بیشازحد صیقلی عملکرد بهتری دارد. کلید موفقیت، ثبات و قرارگیری استراتژیک در پلتفرمهایی است که مخاطبانتان زمان خود را در آنها میگذرانند. اینستاگرام و فیسبوک فرصتهایی برای جلب توجه والدین فراهم میکنند، در حالی که یوتیوب بهویژه جوانان را جذب میکند.
هرچند که اعتماد بهنفس خود را در تولید محتوای ویدئویی تقویت میکنید، این فرایند تبدیل به ادامهٔ طبیعی روایت برند شما میشود — داستانتان را به روشهای مختلفی بیان میکند که هم با مشتریان فعلی و هم با افرادی که تازه شما و کسبوکارتان را میشناسند، همخوانی داشته باشد.
شخصیسازی از طریق دادهها و فناوری
هوش مصنوعی (AI) نحوهٔ ارتباط ما را دگرگون کرده است و همچنان در حال تکامل است زیرا مصرفکنندگان بهدنبال شخصیسازی بیشتر هستند — در حالی که انتظار دارند اصالت در اولویت باقی بماند. یک نظرسنجی از Deloitte نشان داد که ۷۱٪ مصرفکنندگان امروزه انتظار تجربههای شخصیسازیشده را دارند و کسانی که این تجربهها را دریافت میکنند، بهصورت وفاداری و هزینهگذاری بیشتر به برندها پاداش میدهند.
اما در زمینه فناوری تمایز مهمی وجود دارد: برندهایی که استانداردها را تعریف میکنند، هوش مصنوعی را صرفنظر از هدف استفاده نمیکنند. بلکه هوش مصنوعی را بهصورت مثبت میپذیرند در حالی که به اصول استفاده از دادهها و شفافیت پایبند هستند.
برای یک کارآفرین، ابزارهای هوش مصنوعی میتوانند راهحلی برای رفع یک نیاز در حال رشد باشند، مثلاً تقسیمبندی فهرست ایمیل کسبوکار. برای مثال، هوش مصنوعی میتواند نگاهی عمیقتر به عادات خرید مصرفکنندگان داشته باشد، که این امکان را میدهد تا شخصیسازی ایمیلهای خود را بدون ساعتها کار دستی بهبود بخشید. با این حال، هنگامی که دادهها و فناوری کار سنگین را انجام میدهند و شما دقت را بررسی کردهاید، یک کار نهایی باقی میماند: افزودن لمس شخصی خود برای حفظ صدای اصیل. این گاهی ممکن است مستلزم بازنگری دقیق اطلاعات، بازگشت به صفحه نقاشی یا کاری بسیار سادهتر باشد.
بهعنوان مثال، از هوش مصنوعی برای ایجاد پیشنویس اولیهی یادداشت تقدیر از مشتری استفاده کنید، اما آن را به صدای خودتان تطبیق دهید و بهصورت یادداشت دستنویس به سفارشات یا پیام ویدئویی شخصی برای مشتریان ویژه ارسال کنید. مشتریان این تفاوت را احساس میکنند، زیرا ارتباط هوشمند و بهموقعی همراه با مراقبت صمیمی دریافت میکنند. گامهای کوچک، شتابی بزرگ ایجاد میکنند.
مرتبط: ۷ ایده نوآورانه بازاریابی که به برند شما کمک میکند در این فصل تعطیلات برجسته شود
تقویت اصالت و جامعه
در دنیایی که بهتدریج بهصورت آنلاین رشد میکند، ارتباط یک ارز ارزشمند است. مردم به دنبال تعاملات صادقانه با برندهایی هستند که ارزشهایشان را بازتاب میدهند و بهطور مستمر مراقبت واقعی را نشان میدهند؛ و نسلهای جوانتر بهسوی ارتباط شفاف و قابلدرک که معنا منتقل میکند، جذب میشوند.
تبلیغ سینمایی تعطیلاتی فروشگاه UPS با عنوان «تایید انسان بودن» بهخوبی این احساس را به تصویر میکشد. این فیلم کوتاه که توسط کارگردان مشهور جیا کوپولا ساخته شده است، نشان میدهد چگونه توجه به جزئیات ارتباط صادقانهای ایجاد میکند و روح واقعی فصل را در محیطی دیجیتال به تصویر میکشد. شخصیت اصلی ما بهدنبال یافتن زیبایی بیبدیل است که از انتخاب دقیق هدیه با در نظر گرفتن دریافتکننده ناشی میشود و خدمات واقعی، شخصی و برنده جایزهٔ فروشگاه UPS را بازتاب میدهد.
اگرچه ممکن است به همان شکل هدیههای فیزیکی به مشتریان ندهید، یک ارتباط سالانه میتواند هدیهای بزرگ برای آنها باشد. در سال نو جامعهای بسازید با حضور مداوم، پاسخ شخصی به پرسشها و نظرات مشتریان و به اشتراکگذاری انگیزهٔ صادقانهٔ خود برای راهاندازی کسبوکار. گام بیشتری بردارید و با دیگر کارآفرینان در زمینههای خیریه یا پروژههای جامعهای که با هدف کسبوکارتان همراستا است، همکاری کنید (مانند غذاخانه، برنامه مشاوره برای کودکان یا آثار هنری برای یک رویداد).
محتوای تولیدشده توسط کارکنان شما اصالت را بیش از پیش تقویت میکند. وقتی تیم شما تجربیات روزمرهٔ خود را بهعنوان بخشی از شرکت به اشتراک میگذارند، ارزشها، فرهنگ و محصولات شما را بهعنوان صداهای متخصص منتقل میکنند. مشتریان این روایتهای شخصی را میطلبند زیرا حس میکنند بیفیلتر و واقعی هستند. فراتر رفتن از پستهای اسکریپتدار در شبکههای اجتماعی، دستگاهی از محتوا را ایجاد میکند که توسط افراد واقعی که به کاری که انجام میدهید باور دارند، تغذیه میشود.
دور شدن از جستجوی سنتی
چشمانداز جستجو — موتوری که مشتریان توسط آن کشف میشوند — بهطور بنیادی در حال تحول است. مخاطبان جوانتر (مانند نسل میلینیال و نسل Z) برای یافتن اطلاعات به پلتفرمهای اجتماعی و ابزارهای هوش مصنوعی مولد روی میآورند. در واقع، ۴۱٪ کاربران نسل Z اکنون برای پاسخگویی به سؤالات خود بهصورت پیشفرض به شبکههای اجتماعی مراجعه میکنند، در مقابل ۳۲٪ که از موتورهای جستجوی سنتی استفاده میکردند. و نصف مصرفکنندگان هماکنون از جستجوی مبتنی بر هوش مصنوعی بهره میبرند. این نشاندهندهٔ وابستگی رو به رشد به محتوا، اینفلوئنسرها و هوش مصنوعی بهعنوان منابع معتبر اطلاعات است.
پلتفرمهای اجتماعی و ابزارهای جستجوی مبتنی بر هوش مصنوعی اکنون بهعنوان موتورهای کشف برای پیشنهادهای محصول، کسبوکارهای محلی و الهامگیریهای سبک زندگی عمل میکنند. برای پیشرفت استراتژی بهینهسازی موتور جستجو (SEO) بهعنوان مالک یک کسبوکار کوچک، باید در جایی که مشتریان شما بهدنبال اطلاعات میگردند، حضور داشته باشید: در پلتفرمهای اجتماعی که مرور میکنند و در نتایج جستجوی هوش مصنوعی که سؤالاتشان را میپرسند.
رویکرد موفق ترکیبی از هر دو است. برای مثال، یک دانشجوی دانشگاه ممکن است شما را از طریق یک ویدئوی تیک‑توک کشف کند، سپس با بررسی نظرات Google Maps از صحت شما اطمینان یابد و پس از آن از ChatGPT برای دریافت توصیههای مرتبط با دستهٔ شما سؤال کند. هر نقطهٔ تماس مهم است.
مرتبط: چگونه فروش حضوری خود را در فصل تعطیلات فراتر از تعطیلات گسترش دهید
بهعنوان گام بعدی، اطمینان حاصل کنید که اطلاعات کسبوکار شما دقیق و در چندین کانال کشفی (مانند اینستاگرام، Google Maps، فیسبوک و/یا تیکتوک) قابل مشاهده است. مشتریان راضی را تشویق کنید تا تجربههای خود را بهاشتراک بگذارند و بهسرعت به نظرات و کامنتها پاسخ دهید. این تعامل مستمر به پلتفرمها (و مدلهای هوش مصنوعی) نشان میدهد که شما یک کسبوکار فعال و درگیر هستید؛ که این کار باعث بهبود دیده شدن شما و تقویت شهرتتان میشود.
بازاریابی برای دنیای آینده به چابکی، اصالت و تمایل به پذیرش فناوریهای در حال تحول در حالی که ارتباط را حفظ میکند، نیاز دارد؛ این دقیقاً تعریف خدمات مشتری برجسته و بهیادماندنی است. خبر خوب این است که کارآفرینان بهطور ذاتی توانایی انعطافپذیری، واکنش سریع به روندها و ساختن روابط اصیل در مقیاس بزرگ را دارند.
مزیت رقابتی شما از تمایز بهدست میآید. با سرمایهگذاری در این چهار روند بازاریابی، حضور برندی ایجاد میکنید که مشتریان به یاد میآورند، توصیه میکنند و دوباره به آن باز میگردند.
نکات کلیدی
محتوای ویدئوی کوتاهمدت از یک گزینهٔ لوکس به یک ضرورت در استراتژیهای بازاریابی تبدیل شده است.
هوش مصنوعی و شخصیسازی، اساسیترین عوامل تعامل مدرن با مشتریان هستند؛ بهطوریکه ۷۱٪ مصرفکنندگان انتظار دارند تعاملات برند بهصورت شخصیسازیشده باشد.
یکپارچهسازی اصالت و ساخت جامعه، بههمراه سازگاری با رفتارهای جدید جستجو همچون شبکههای اجتماعی و ابزارهای مبتنی بر هوش مصنوعی، برای دیده شدن و رشد کسبوکار حیاتی است.
با شروع فصل خریدهای تعطیلات، لحظهٔ حاضر که اوج مصرف و ارتباط سال را نشان میدهد، در مرکز توجه کسبوکارهای همهاندازه قرار دارد. در میان این فصل شلوغ، صاحبان کسبوکار باید برای «چیزی که بعداً میآید» در ترجیحات مصرفکنندگان هم آماده باشند.
هوش مصنوعی (AI)، بینشهای مبتنی بر دادهها، محتوای کوتاهمدت، ساخت جامعه و موارد دیگر نقش ایفا خواهند کرد، اما اینها برای کارآفرینان چگونه میتوانند شکل بگیرند؟ این چهار روند را در نظر بگیرید تا کسبوکار خود را سال بهسال به مقصدی موردتقاضای مشتریان تبدیل کنید.



 آلیسون مورو
آلیسون مورو