همه میدانیم که باید سبزیجات بخوریم و از غذاهای ناسالم پرهیز کنیم؛ اما دانستن با عمل کردن متفاوت است.
بازاریابان بهصورت غریزی میدانند که دادههای بهتر و رسانههای با کیفیت بالاتر، نتایج بهتری بهدست میدهند. اما عادتهای بد چسبندهاند و بهسختی از بین میروند، گفت جیمی بارنارد، مدیرعامل Compliant، استارتآپی که استانداردهای کیفیت داده را در رسانههای دیجیتال پیگیری میکند.
صنعت تبلیغات «ذهنیتی مبتنی بر حجم» دارد، گفت بارنارد که این چالش را بهصورت مستقیم تجربه کرده است. او نزدیک به ۱۶ سال در یونیلور بهعنوان مشاور حقوقی ارشد خود که بر بازاریابی جهانی، رسانه و تجارت الکترونیک متمرکز بود، کار کرد و در سال ۲۰۲۲ این شرکت را ترک کرد.
پس چه باید اتفاق بیفتد تا این صنعت از خوردن اینهمه «فستفود» دست بکشد؟
کیفیت نیازی به هزینهی بیشتر ندارد
این همان پرسشی بود که Compliant در اوایل امسال با اجرای مجموعهای از آزمایشهای کنترلشده با چهار برند جهانی در حوزههای محصولات مصرفی (CPG)، خدمات مالی، الکترونیک مصرفی و بهداشت مصرفکننده، بهدنبال پاسخ آن رفت.
نتایج که روز پنجشنبه منتشر شد، برای هیچکس تعجبآور نیست (اگرچه این نکته باید توسط همه شنیده شود): کیفیت عملکرد و کارآمدی را بهدست میآورد، خرید موجودی کمکیفیت همانند هدر رفتن پول است و همانطور که مشخص شد، صرف هزینه برای رسانههای بهتر لزوماً هزینه بیشتری نمیطلبد.
طبق یافتههای Compliant، آگهیدهندگانی که به یکپارچگی داده اهمیت میدهند و مصمم به خرید نمایشها از ناشران ارزشمند با شیوههای دادهای بهتر هستند، هزینه بهازای هر اقدام (CPA) خود را ۳۳٪ کاهش میدهند، CPMها را ۳۲٪ کاهش میدهند و بازگشت هزینه تبلیغاتی (ROAS) را ۵٪ افزایش میبخشند.
اما همانطور که واضح بهنظر میرسد، واقعیت پیچیدهتر است، گفت سامیر آمین، معاون بازاریابی مبتنی بر داده در Reckitt، یکی از آگهیدهندگانی که در این مطالعه شرکت داشتند و پرتفولیوی آنان شامل محصولاتی از لیزول، موکینکس، کلیرسیل تا دورکس، K‑Y و برند فرمول شیر کودک انفامیِل میشود.
یکی از دلایلی که خریداران همچنان به دنبال موجودیهای ارزان و حجمبالا میروند، عدم اندازهگیری مناسب است.
«مدلهای اقتصادسنجی، تحلیل ترکیب بازاریابی – این ابزارها تمایل دارند بازگشت سرمایه (ROI) خوبی به موجودیهای کمهزینه بدهند بدون اینکه بهدرستی به کیفیت نمایشها نگاه کنند»، گفت آمین. «اما ما متوجه شدیم که اگر به دادههای صحیح نگاهی داشته باشیم و به مسائلی مثل قابلیت مشاهده و ایمنی برند اهمیت بدهیم، میتوانیم نتایج بهتری بدست آوریم بدون اینکه حتماً هزینه بیشتری بپردازیم.»
یک موفقیت متا؛ از بهشت تا جایگذاریهای تبلیغاتی
کیفیت بهصورت طراحیشده
نیازی نیست که سوئیچی وجود داشته باشد که بازاریابان بتوانند با یک لمس از اولویتدادن به مقیاس به تمرکز بر کیفیت تغییر دهند.
بهترین کاری که میتوانند انجام دهند، به گفته آمین، این است که خود را آموزش دهند و دستهایشان را به کار بگذارند.
«شما باید در دادهها سرمایهگذاری کنید، در ابزارها سرمایهگذاری کنید و در افرادی که میتوانند از دادهها و ابزارها استفاده کنند سرمایهگذاری کنید»، او گفت. «اعتماد به پلتفرمهای بزرگ مانند گوگل و فیسبوک آسانتر است، اما اگر میخواهید بهبود حاصل کنید، باید خودتان کار کنید.»
بهعنوان مثال، Reckitt فهرستهای انتخابی برای شرکای تأمین خود تهیه میکند تا موجودیهای با کیفیت را شناسایی کند و ناشرانی را که زیر آستانهای از یکپارچگی داده تعیینشده قرار میگیرند کنار بگذارد. سپس، بهطور مستقیم با ناشران منتخب، قراردادهای بازار خصوصی بسته میکند؛ این امر به برندها کنترل بیشتری بر کیفیت و زمینه خریدهای رسانهای میدهد.
افراد خاصی برای نظارت بر این مشارکتها و قراردادها وجود دارند تا اطمینان حاصل کنند که سرمایهگذاریها با اهداف برند و استراتژیهای بازاریابی همراستا هستند و تأمینکنندگان معتبر با گذشت زمان شناخته و بهعنوان اولویت در نظر گرفته شوند.
Reckitt همچنین چارچوبهای ایمنی برند و مناسبسازی را برای هر یک از برندهای خود تنظیم کرده است که نیازهای متفاوت در سبد محصولات را منعکس میکند.
«معنادار نیست که همان پروتکلها را برای برندی که به صمیمیت جنسی میپردازد مانند دورکس به کار ببریم که برای برند فرمول شیر کودک است»، گفت آمین. «آنچه برای یک برند کار میکند، برای دیگری حذف میشود و برعکس.»
بهعبارت دیگر، تصمیمگیری درباره مخاطب و رسانهها بر پایه استراتژی است، نه صرفاً براساس خرید یا قیمت. اگرچه خوشایند است که میتوان تأمینکننده با کیفیت را بدون هزینهٔ بیش از حد بهدست آورد، افزوده او.
آیا این بار متفاوت خواهد بود؟
صبر کنید، این اولین بار نیست که بازاریابان شواهد واضحی دارند که کیفیت بر کمیت غلبه میکند.
به یاد داشته باشید که در سال ۲۰۱۷، وقتی JPMorgan Chase فهرست سایتهای برنامهای خود را از ۴۰۰,۰۰۰ به ۵,۰۰۰ کاهش داد، بدون اینکه عملکردی پایین بیاید؟ و گزارش شفافیت مشهور ANA که چند سال پیش مقدار شگفتانگیزی از هدررفت در زنجیره تأمین برنامهای را نشان داد، را نیز بهخاطر بسرید.
نکته این است که حتی با وجود شواهد واضح، تغییر بهسختی پیش میرود.
«گزارش جدید نشان میدهد که کیفیت در برنامهریزی پروگرامتیک بهسود میانجامد» – عنوان این مقاله – در واقع نباید در سال ۲۰۲۵ یک کشف جدید باشد، اما بهنحوی، همینطور است.
پس چه چیزی این بار را متفاوت میکند؟
یکی از عوامل مهم هوش مصنوعی است. با شروع بهکارگیری هوش مصنوعی در خرید و بهینهسازی رسانهها، نیاز به شفافیت و دادههای با کیفیت بیش از هر زمان دیگری حس میشود؛ این ممکن است سرانجام دلیلی کافی برای برندها باشد که بر اساس دانش خود اقدام کنند، گفت بارنارد.
ظهور هوش مصنوعی مولد و ابزارهای هوشمحور امکان دسترسی به دادههای دقیق و تجزیهوتحلیلهای زمانواقعی را فراهم میکند، اما همچنین نیاز به رفع مشکلات کیفیت داده را از همان ابتدا تشدید میکند.
«اگر رسانهها را از ناشرانی با شیوههای دادهای نامناسب خریداری کنید، هیچ میزان بهینهسازی پس از آن نتواند تأثیر مخرب بر هدفگیری و کارایی را جبران کند»، گفت بارنارد. «بسیار مهم است که بازاریابان و ابزارهای مولدشان شفافیتی نسبت به کیفیت رسانههای موجود در سمت عرضه داشته باشند.»
بهعنوان بخشی از پلتفرم خود، Compliant چارچوبی امتیازدهی دارد که آن را شاخص یکپارچگی داده (Data Integrity Index) مینامد؛ این شاخص بهصورت مستقل صحت تبعیت ناشران از شیوههای دادهای مسئولانه و استانداردهای صنعتی، از جمله انطباق با حریم خصوصی، را ارزیابی و اندازهگیری میکند.
این سامانه نمرهای برای شفافیت ارائه میدهد که بازاریابان میتوانند از آن برای راهنمایی تصمیمگیریهای خرید رسانهای خود استفاده کنند.
«بسیار ساده است که به تمام مشکلات موجود در برنامهریزی پروگرامتیک نگاه کنید، اما در واقع موجودیهای خوب فراوانی وجود دارد»، گفت بارنارد. «تغییر به مدل مبتنی بر ارزش به معنای بازنگری در معیارهای مهم است و استانداردهای دادهٔ خوب باید بهعنوان بخشی از ساختار برنامهریزی پروگرامتیک تلقی شوند.»
اعتبار: Lucas Gouveia / Android Police | DONOT6_STUDIO / Shutterstock
گوگل همچنان بهروزرسانیهای کوچک اما مفیدی را برای برنامهٔ Gemini در اندروید اعمال میکند تا تجربهٔ استفاده از آن بهبود یابد. با اینحال، این برنامه هنوز کمبودهای زیادی دارد، بهویژه با در نظر گرفتن تواناییهای Gemini. خوشبختانه، گوگل میداند که برنامهٔ Gemini — هم در وب و هم در موبایل — نیاز به کار دارد و بهطور فعال روی آن کار میکند.
در پاسخ به پستی در X دربارهٔ اینکه رابط کاربری (برنامه) Gemini بهخوبی ChatGPT نیست، Logan Kilpatrick — مسئول محصول اصلی استودیو هوش مصنوعی گوگل و API Gemini در گوگل — تأیید کرد که شرکت هماکنون «سرمایهگذاری عظیم»یی در Gemini App UX ۲.۰ انجام میدهد.
برنامهٔ Gemini فعلی، تمام ویژگیهای خود را بهخوبی نشان نمیدهد. با بازطراحی رابط کاربری، گوگل میتواند تواناییهای چشمگیر Gemini را به نمایش بگذارد و دسترسی به ویژگیهای روزمره را سادهتر کند.
او همچنین فاش کرد که گوگل در حال توسعهٔ برنامهٔ بومی Gemini برای macOS است.
ChatGPT یک برنامهٔ بومی برای ویندوز و مک ارائه میدهد که استفاده از آن را آسان میسازد. علاوه بر این، قابلیتهای پیشرفتهای مانند یکپارچهسازی بومی با برنامههایی چون Notion، Terminal و Apple Notes را فعال میکند. در مقایسه، تنها راه دسترسی به Gemini در یک رایانه شخصی، استفاده از مرورگر وب است. اگرچه این روش کار میکند، تجربهای کجتر و کمتر صیقلی نسبت به برنامهٔ بومی ChatGPT بهوجود میآورد.
بهعنوان مثال، در حال حاضر بارگذاری چندین فایل در ChatGPT روی مک یا ویندوز از طریق برنامهٔ بومی بسیار آسانتر است. در مقابل، برای استفاده از Gemini باید از مرورگر وب استفاده کنید که این کار فرآیند کلی را کند میکند.
بهطور مهمتر، همانطور که مدلهای هوش مصنوعی شروع به ارائهٔ قابلیتهای عاملی میکنند، یک برنامهٔ بومی میتواند به آنها کمک کند تا بهتر با فایلهای محلی کار کنند و بهسادگی با برنامههای دیگر روی رایانهٔ شما یکپارچه شوند.
بهنظر میرسد تیم Gemini در گوگل این نکته را درک کردهاند و به همین دلیل در حال توسعهٔ برنامهٔ بومی برای مک هستند. هنوز زمانبندی انتشار مشخص نشده، اما با توجه به سرعت بالای بهروزرسانیهای Gemini توسط گوگل، انتظار طولانی نخواهد بود.
گوگل در حال توسعه برنامهٔ موبایلی برای AI Studio است
اعتبار: Lucas Gouveia / Android Police | klyaksun / Shutterstock
گوگل همچنین در حال توسعهٔ برنامهٔ بومی Google AI Studio برای آیفون و اندروید است که با نام Build Anything شناخته میشود.
بر اساس پاسخهای Ammar Reshi، سرپرست محصول و طراحی استودیو هوش مصنوعی گوگل، این برنامه ممکن است هنوز مدتی تا انتشار نداشته باشد. با این حال، اگر از AI Studio بهطور فراوان استفاده کنید، یک برنامهٔ موبایلی اختصاصی به شما امکان میدهد که حتی در حرکت، جلسات کدنویسی خود را ادامه دهید.
مدلهای جدید هوش مصنوعی در وظایف سئو عملکرد ناکافی نشان میدهند. دلیل کاهش دقت را کشف کنید و پیش از اینکه این کاهشها بر نتایج شما تأثیر بگذارد، راههای سازگاری را بیابید.
جدیدترین نتایج بنچمارک Previsible، کاهش شگفتانگیزی در دقت سئو مدلهای برتر هوش مصنوعی را نشان میدهد.
خلاصه:
جدیدترین مدلهای پرچمدار هوش مصنوعی (Claude Opus 4.5، Gemini 3 Pro) در عملکرد وظایف سئو استاندارد بهصورت آماری پسرفتگی نشان میدهند و حدود ~9 ٪ کاهش نسبت به نسخههای قبلی دارند.
این یک اشکال نیست – بلکه ویژگی بهینهسازی مدلها برای استدلال عمیق و جریانهای کاری «عاملمحور» بهجای پاسخهای «یکبار» است.
برای عبور از این تحول، سازمانها باید از تکیه بر درخواستهای ساده صرفنظر کرده و به «محفظههای زمینهای» (GPTهای سفارشی، Gems، پروژهها) منتقل شوند.
افسانهٔ «جدیدتر = بهتر» به پایان رسیده است
سال گذشته روایت بهصورت خطی بود: منتظر انتشار نسخهٔ بعدی باشید تا نتایج بهتری به دست آورید. این مسیر دیگر دیگر شکسته است.
هماکنون آزمون بنچمارک سئو هوش مصنوعی خود را بر روی جدیدترین نسخههای پرچمدار – Claude Opus 4.5، Gemini 3 Pro و ChatGPT‑5.1 Thinking – اجرا کردیم و نتایج هشداردهنده هستند.
برای اولین بار در عصر هوش مصنوعی مولد، مدلهای جدید بهمراتب در وظایف سئو نسبت به نسخههای پیشین ضعیفتر هستند.
ما دربارهٔ حاشیهٔ خطا صحبت نمیکنیم. در حال مشاهدهٔ پسرفتگیهای نزدیک به دو رقم هستیم:
Claude Opus 4.5: نمره ۷۶٪، که نسبت به نسخهٔ ۴.۱ که ۸۴٪ داشت کاهش یافت.
Gemini 3 Pro: نمره ۷۳٪، که نسبت به نسخهٔ ۲.۵ Pro که اوایل سال تست کردیم، حدود ۹٪ کاهش چشمگیری دارد.
Chat GPT‑5.1 Thinking: نمره ۷۷٪ (۶٪ کمتر از GPT‑5 استاندارد). این نشان میدهد افزودن لایههای استدلال موجب تاخیر و نویز در وظایف سئو ساده میشود.
چرا مهم است: اگر تیم شما درخواستهای API یا پرسشهای خود را به «جدیدترین مدل» بهروزرسانی کرده باشد، بهاحتمال زیاد هزینه بیشتری برای نتایج ضعیفتر میپردازد.
تشخیص: شکاف عاملی
چرا این اتفاق میافتد؟ چرا گوگل و Anthropic مدلهای «کمهوشتر» منتشر میکنند؟
پاسخ در اهداف بهینهسازی جدید آنها نهفته است.
ما نقاط شکست در مجموعهدادهامان را تحلیل کردیم که بهطور عمده به سئو فنی و استراتژی وزن میدهد (حدود ۲۵٪ از مجموعهٔ آزمون ما را تشکل میدهد).
این مدلهای جدید برای درخواست «یکبار» (پرسیدن سؤال و دریافت پاسخ فوری) بهینهسازی نشدهاند.
در عوض، برای موارد زیر بهینهسازی شدهاند:
استدلال عمیق (تفکر سیستم ۲): آنها مجموعهٔ دستورات ساده را بیش از حد تحلیل میکنند و اغلب پیچیدگیهایی را که وجود ندارند، تصور میسازند.
زمینهٔ گسترده: آنها انتظار دارند کل پایگاههای کد یا کتابخانهها بهصورت کامل دریافت کنند، نه بخشهای کوتاه یک URL.
ایمنی و محدودیتها: آنها تمایل بیشتری به رد درخواست بازبینی فنی دارند، زیرا ممکن است «مانند» یک حملهٔ سایبری به نظر برسد یا قوانین ایمنی مبهم را نقض کند. این الگوی رد درخواست را بهطور مکرر در معماریهای جدید Claude و Gemini مشاهده میکنیم.
ما در شکاف عاملی قرار داریم. مدلها سعی میکنند بهعنوان عوامل خودمختار عمل کنند که پیش از بیان، «فکر کنند».
اما برای وظایف سئو مستقیم و منطقی (مانند تجزیه و تحلیل تگ canonical یا شناسایی نیت کلیدواژه)، این «نویز» اضافی تفکر، دقت را کاهش میدهد.
راهحل: از درخواستهای ساده دست بکشید، به معماریسازی بپردازید
دورهٔ درخواستهای ساده بهپایان رسیده است.
دیگر نمیتوانید بهطور مستقیم بر یک مدل پایه (بدون سفارشیسازی) برای انجام وظایف سئو حیاتی اعتماد کنید.
اگر میخواهید آن معیار دقت ۸۴٪ را بازیابید و فراتر بروید، باید زیرساخت خود را تغییر دهید.
۱. رها کردن رابط گفتوگو برای جریانهای کاری
از این که تیم شما در پنجرهٔ گفتوگوی پیشفرض کار کند، دست بکشید.
مدل ساده فاقد محدودیتهای خاص مورد نیاز برای استراتژی سطح بالا است.
تحول: تمام وظایف تکراری را به «محفظههای زمینهای» منتقل کنید.
ابزارها: GPTهای سفارشی OpenAI، پروژههای Claude Anthropic، و Gems Gemini گوگل.
۲. کدگذاری سختگیرانهٔ زمینه (RAG lite)
کاهش نمرهها در سؤالات استراتژی نشان میدهد که بدون راهنمایی دقیق، مدلهای جدید بهسوی انحراف میروند.
استراتژی: از مدل نخواهید که «یک استراتژی ایجاد کند». باید محیط را پیش از آن با راهنماییهای برند، دادههای عملکرد تاریخی و محدودیتهای روششناسی بارگذاری کنید.
چرا مؤثر است: این کار مدل را مجبور میکند تا تواناییهای استدلالی خود را بر پایه واقعیت شما استوار سازد، نه اینکه مشاورهٔ کلیحالی ارائه دهد.
۳. تنظیم دقیق یا استفاده از مدلهای «منجمد» برای سئو فنی
برای وظایف دودویی (مانند بررسی کدهای وضعیت یا اعتبارسنجی اسکیما)، مدلهای «Thinking» بیش از حد پیچیده هستند و بهسوی خطا تمایل دارند.
استراتژی: برای وظایف مبتنی بر کد، از مدلهای قدیمی و پایدار (مانند GPT‑4o یا Claude 3.5 Sonnet) استفاده کنید یا یک مدل کوچکتر را بهطور خاص بر پایهٔ قوانین بازبینی فنی شما تنظیم دقیق کنید.
نکات کلیدی
پاییندست رفتن برای ارتقاء: در حال حاضر، مدلهای نسل قبلی (Claude 4.1، GPT‑5) در وظایف سئوی سادهساختاری نسبت به نسخههای جدید (Opus 4.5، Gemini 3) عملکرد بهتری دارند. فقط بهدلیل بالاتر بودن شمارهٔ نسخه، ارتقا ندهید.
یکپرسش بهپایان رسیده است: درخواستهای تکبار بدون بهبود پنجرههای زمینه در عصر «استدلال» جدید بهطور قابلتوجهی بیشتر شکست میخورند.
همه چیز را در محفظهها بگذارید: اگر کاری تکرارپذیر است، باید در یک GPT سفارشی، پروژه یا Gem قرار گیرد. این تنها راه برای کاهش «انحراف استدلال» مدلهای جدید است.
فناوری و استراتژی بیشترین آسیب را میبینند: دادههای ما نشان میدهد این دستهها بیشترین اثر را از پسرفتگی مدلها دریافت میکنند. هر بازبینی فنی خودکاری که بر روی APIهای مدلهای جدید اجرا میشود را دوبار بررسی کنید.
چشمانداز استراتژیک
از زمان بنچمارک آوریل ما میگوییم: نمیتوانید این مدلها را بهصورت آماده برای هر کار بحرانی استفاده کنید.
سئو با رهبری انسانی در عصر عاملها
تغییر از «چتباتها» به «عاملها» نیاز به استعداد سئو را از بین نمیبرد؛ بلکه آن را ارتقا میدهد.
مدلهای هوش مصنوعی امروز راهحل «پلاس‑اند‑پلی» نیستند؛ آنها ابزارهایی هستند که بهکاربران ماهر نیاز دارند.
همانطور که انتظار ندارید یک متخصص پزشکی بدون آموزش بتواند یک جراحی مصنوعی را با موفقیت انجام دهد، نمیتوانید یک مدل پیچیده را تنها با یک درخواست، انتظار داشته باشید که نتایج سئوی با کیفیت بالا تولید کند.
موفقیت در این عصر جدید به تیمهای انسانی بستگی دارد که بدانند چگونه:
معماریسازی سیستمهای هوش مصنوعی.
ادغام آنها در جریانهای کاری.
قضاوت خود را برای اصلاح، هدایت و بهینهسازی خروجیها بهکار گیرند.
بهترین نتایج سئو تنها از بهبود درخواستها بهدست نمیآیند.
آنها از متخصصانی میآیند که میدانند چگونه محدودیتها را طراحی کنند، زمینهٔ استراتژیک را تزریق کنند و مدلها را با دقت هدایت نمایند.
اگر سیستمی با عملکرد بالا نساختید، مدل شکست خواهد خورد.
ستوننویس SFGATE، درو مُگری، دربارهٔ «فناوری شرور» که جهان را بهتسلط درآورده است
بیلبوردی در سانفرانسیسکو، در تاریخ ۱۶ سپتامبر ۲۰۲۵ یک شرکت هوش مصنوعی را تبلیغ میکند.
جاستین سالیوان/گتی ایمیجز
چند ماه پیش پسرم از من خواست که برای او یک اشتراک بخریم. محصول مورد نظر برنامهای به نام Ground News بود. با هزینهٔ ۱۰۰ دلار در سال، Ground News به هر لینکی که پسرم میبیند، یک درجهٔ سوگیری اختصاص میداد. او یک روزنامهنگار جواننواز است و میداند که صنعت روزنامهنگاری — حوزه کاری من — پر از اطلاعات نادرست، ابهامپذیری و انگیزههای سیاسی پنهان است. این کودک تنها ۱۶ سال دارد و به اندازهٔ پدرش درکی از رسانهها ندارد. در نظریه، یک ابزار تشخیص سوگیری مثل Ground News میتواند مفید باشد.
بنابراین کمی در مورد Ground News تحقیق کردم تا ببینم آیا ارزش اشتراک را دارد یا نه. و دوستان، باور نخواهید کرد اما نه. در واقع، برخی از ارزیابیهای سوگیری آن مستقیماً از یک الگوریتم هوش مصنوعی خریداری میشوند. پس از آنکه این اطلاعات را کشف کردم، به پسرم گفتم که این برنامه آشغال است.
چون هوش مصنوعی آشغال است. این یک فناوری ذاتیً ضدانسان است که بهطور فعال به صدها میلیوننفری که از آن استفاده میکنند آسیب میرساند. یک مطالعهٔ اخیر MIT نشان داد استفاده از رباتهای هوش مصنوعی، مثل ChatGPT، میتواند مهارتهای شناختیتان را خفه کند. چندین والدین علیه شرکت مادر ChatGPT، سازمان غیرانتفاعی پیشین OpenAI، دعوی کردند و ادعا کردند این محصول فرزندانشان را بهطرز موفقیتآمیز به خودکشی تشویق میکند. در جاهای دیگر، خدمات هوش مصنوعی در حال سرقت محتوای خلاقی هستند که حق مالکیتشان را ندارند، تصاویر شبیهسازیشدهٔ سوءاستفادهٔ جنسی از کودکان را برای تازهکارهای جنسی توزیع میکنند، صورتحسابهای برق آمریکاییها را بهسرعت افزایش میدهند و انتشار گازهای گلخانهای حاصل از سوختهای فسیلی را به سطوح رکوردی بالا میبرند، در زمانی که سلامت سیاره و سلامت بشر دیگر توانایی پرداخت این هزینهها را ندارند. بهعنوان نقطهٔ اوج، غولهای فناوری که از رونق هوش مصنوعی بهسرعت سود بردهاند، بهصراحت هزاران کارگر را اخراج کردهاند و هدفشان این است که مدلهای هوش مصنوعیشان جایگزین این کارها شوند. اندرو یانگ به ما هشدار داد که رباتها برای چکدستهای ما میآیند، اما ما گوش نکردیم.
مشکل فقط در حال گسترش است. در یک بازهٔ زمانی بسیار کوتاه، هوش مصنوعی تبدیل به شکر ذرت پرقند دیجیتال شده است: اکنون در همه چیز حضور دارد، حتی اگر شما نخواهید. این فناوری در صدر هر جستجوی گوگل قرار دارد، مگر اینکه کمی تنظیم دستی کنید. در فید خبریتان، در لیستپخش Spotifyتان، حتی در تبلیغات تباهکنندهٔ تعطیلاتی کوکاکولا، حضور دارد. و به لطف رئیسجمهور عزیزمان نرکولِپسی، بهزودی در دولتتان نیز حضور خواهد یافت. از NBC News:
«[دستور ترامپ] دروازهای بهسوی مشارکتهای عمومی‑خصوصی بهطور چشمگیری در توسعه هوش مصنوعی باز میکند: در طی ۹۰ روز، وزیر انرژی باید سیستمها و دادههای موجود برای حمایت از برنامه را شناسایی کند، از جمله «منابع موجود از طریق شرکای صنعتی».»
اما با این حال، آنها هنوز میخواهند بیشتر. در حقیقت، همان شرکتها بهشدت میگویند که ظهور هوش مصنوعی یک فرصت اقتصادی است که باید بهطور کامل از آن بهرهبرداری کنند. آنها اکنون متحدانی در واشنگتن دارند. تعداد زیادی. همین تابستان، سناتور تگزاس تد کروز یک تلاش برای ممنوع کردن ایالتهای منفردی مانند کالیفرنیا از تنظیم هوش مصنوعی راهاندازی کرد. تد کروز آدمغلطی است. او برای مبارزه با قانونگذاری هوش مصنوعی بهدلیل مراقبت از شما نیست؛ او این کار را میکند چون میخواهد تو را چاک بزند. همهٔ آنها همین کار را میکنند و در حال موفقیتاند.
این یک بحران است، اما شاید نخوانید که این بحران چقدر بزرگ است، زیرا برنامهٔ Ground News شما این مقاله را «چپ» ارزیابی کرده است. این رباتها فقط به اندازهٔ صداقتی هستند که برنامهنویسانشان دارند. و شاید در حال حاضر نسبت به افراد تجاری بیش از این صادقانی پیدا نکنید که مبلغگرایان هوش مصنوعی در سیلیکونولی باشند. من این را میدانم چرا که محصولاتشان را آزمایش کردهام؛ از شبیهساز ویکیپدیا با هوش مصنوعی ایلان ماسک تا ChatGPT و رقبای آن. هیچیک از اینها برایم تحریک فکری ایجاد نکرد و تقریباً تمام آنها برای شکار آمریکاییها، بهویژه جوانان، که تنهاییشان توسط همهگیری تشدید شده بود، طراحی شدهاند. این مدلهای هوش مصنوعی تماماً نشانهٔ خالقان خود هستند؛ چون این خالقان برای هرچه سودآورتر است، بهطور ابدی متعصب هستند. این سوگیری، همراه با اندکی نازیگری، در محصولاتی که به گردنمان میاندازند، مشهود است.
و میدانید چه؟ آمریکاییها از این وضعیت خسته شدهاند. آنها نمیخواهند برای پرداخت قبضهای برق بالاتر صرفاً بهخاطر اینکه شرکتها آنها را از کار خط تولید اخراج کنند، هزینه کنند. آنها نمیخواهند کودکانشان بهدلیل خودکشی بمیرد. همچنین ترجیح میدهند محتوای پورنوگرافی آنها شامل اندامهای انسانی واقعی باشد نه نسخههای دیجیتالی. ممکن است متا از محصولات هوش مصنوعیاش سود ببرد، اما مشتریانش بهحقیقت، لعنتاً خوشحال نیستند. ما میدانیم که ماندن در یک اتاق چت با یک عامل خدمات مشتری مجازی برای مدت طولانی لذتبخش نیست.
سؤال این است که آیا آمریکاییهای خسته آمادهاند در برابر پشتوانهٔ مؤسسی شگرفی که هوش مصنوعی اکنون از آن بهرهمند است، مبارزه کنند یا نه. تلاش سیلیکونولی برای حذف انسانها از اقتصاد جهانی، هم توسط دموکراتهای شکارچی و هم توسط جمهوریخواهان که همانند ترامپ و کروز، هنر سیاستگری گریهبار را مدتها پیش تکمیل کردهاند، حمایت میشود. جمهوریخواهان تنها میخواهند رایدهندگان را بهگونهای سادهسازی کنند که بهبردگی تبدیل شوند، و این محصولات هوش مصنوعی «نقخورندهٔ ذهن» فقط بهسرعت این فرآیند را تسریع میکند. هیچیک از این افراد بیارزشی که پیشاز این نام بردیم، از ترکیدن حباب هوش مصنوعی رنج نخواهد برد. بهمحض سقوط این بخش، این حشرهخواران به سادگی به حباب جدیدی میچرخند و مالیاتدهندگان هزینهٔ انتقال را میپردازند. از جنگهای بیدلیل تا نجاتهای بیدلیل، پول مالیاتهای آمریکایی همواره عمدتاً برای نگه داشتن بازارها بهکار رفته است. پول واقعی در فساد نهفته است و با حضور ترامپ در رأس، بخش فساد در یک رونق بیسابقه است که هیچکس از ما تا به حال تجربه نکرده است.
این است که دستکاری بازار به هوش مصنوعی کمک کرده تا بهخفهگی به هر محصول دیجیتالی که استفاده میکنید نفوذ کند و چرا یک چتبات هماکنون به برادر کوچکتان دستورالعملهای دقیقی برای آویزان کردن خود در زیرزمین میدهد. این یک فناوری شرور است، و همانطور که به پسرم گفتم زمانی که درخواست اشتراک Ground News کرد، این واقعیت بود. شما، خوانندهٔ تیزبین، نیز باید این خبر را پخش کنید. به خانوادهتان بگویید، به دوستانتان بگویید و به نمایندگانتان اطلاع دهید. هوش مصنوعی شرور است. این یک دستهٔ محصولات بیکیفیت است که برای جنگ بر علیه بشریت ساخته شدهاند، نه بهصورت علمی‑تخیلی جذاب. این یک شرور بدیهی است، همانند بسیاری از سایر شرورها که ما در طول سالها با آنها مواجه شدهایم. اما این شرور در حال رشد است. تمام آمریکاییهای معقول باید خواستار ممنوعیت آن شوند و باید افراد مانند سام آلتمن را در یک سوپرماکس بهدست بگیرند. من اهمیتی نمیدهم که چه نکتهای دیگری از این مقاله میگیرید، به شرط آنکه این پیام را جذب کنید.
و اگر تصمیم گرفتید یک خلاصه هوش مصنوعی از این مقاله بخوانید، یک لحظه اینجا بیایید تا بتوانم به چهرهتان یک لگد بزنم.
مدیران ارشد بازاریابی با فصل بحرانی بودجهریزی ۲۰۲۶ روبرو هستند؛ جایی که اولویت فقط رتبهبندی نیست، بلکه حفظ دیدارپذیری و اطمینان در بسترهای کشف مبتنی بر هوش مصنوعی است.
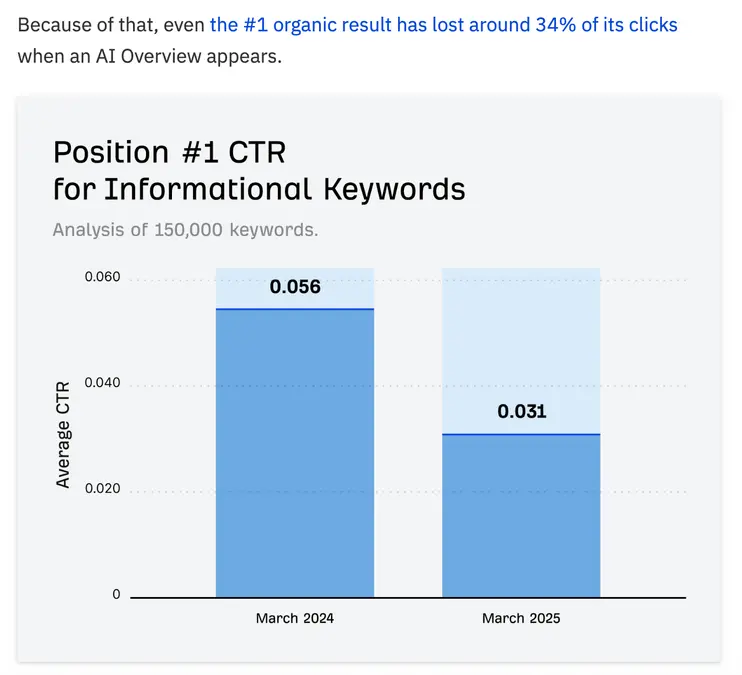
در طول سال ۲۰۲۵، جستجو به سرعت تحول یافت؛ سیستمهای هوش مصنوعی تبدیل به مسیر اصلی کشف اطلاعات شدند که این امر به نوبهٔ خود، ثبات و پیشبینیپذیری ترافیک ارگانیک سنتی بسیاری از برندها را کاهش داد.
در همانزمان که نمایش لینکهای آبی (نتایج ارگانیک) محدودتر شد و نرخ کلیکها بهطور غیرقابل پیشبینی نوسان کرد، مدیران ارشد بازاریابی تحت فشار فزایندهای برای توجیه هزینههای بازاریابی خود، در حالی که باید شتاب را نشان دهند، قرار گرفتند. این تحول رهبران بازاریابی را مجبور کرد تا بهطور جدیتری به پایداری در کانالهای خود بپردازند؛ دیگر نمیتوان صرفاً بر رتبهها تکیه کرد.
برندها به دیدارپذیری پایدار در سطوح هوش مصنوعی، عملیات محتوا قدرتمندتر و منسجمتر، و پایههای فنی پاکتری که هم کاربران و هم سیستمهای هوش مصنوعی را پشتیبانی کند، نیاز دارند.
سهماهه اول (Q1) و نیمسال اول (H1) ۲۰۲۶، دورههایی هستند که این اولویتها باید تأمین مالی و اجرا شوند.
اصول بودجهبندی سئو برای ۲۰۲۶ در Q1/H1
یک بودجه سئو بهخوبی ساختار یافته برای اوایل ۲۰۲۶ بر پایهٔ مجموعهای واضح از اصول استوار است که همزمان ثبات و آزمایش را راهنمایی میکنند.
حفظ تخصیص پایه برای سئو اصلی
این شامل سلامت فنی، عملکرد سایت، معماری اطلاعات و نگهداری مستمر محتوا میشود. این فعالیتها بنیان تمام کانالهای بازاریابی را تشکیل میدهند و حذف آنها در زمانی که الگوهای کشف اطلاعات در حال تغییر است، ریسک ناخواستهای ایجاد میکند.
ایجاد بخشی جداگانه برای آزمایش در زمینه کشف هوش مصنوعی
همانطور که مرورهای AI و سایر موتورهای تولید محتوا بر نحوهٔ ارتباط کاربران با برندها تأثیر میگذارند، مهم است که سرمایهگذاری برای آزمایش محتوای مبتنی بر پاسخ، توسعهٔ نهادها، الگوهای اسکیمای در حال تحول و چارچوبهای سنجش هوش مصنوعی را بهصورت جداگانه محافظت کنیم. بدون این بودجه اختصاصی، این فعالیتها یا متوقف میشوند یا با کارهای اساسی رقابت میکنند.
سرمایهگذاری در اندازهگیریای که رفتار واقعی کاربران را توضیح میدهد
از آنجا که دیدارپذیری در هوش مصنوعی هنوز بهطور کامل بالغ نشده و ناهماهنگ است، تجزیه و تحلیل باید مسیر حرکت کاربران، جایی که سیستمهای AI به برند اشاره میکنند و محتوایی که این نتایج را شکل میدهد، ضبط کند.
این سطح از بینش، توانایی مدیر ارشد بازاریابی را در دفاع و تنظیم مجدد بودجهها در ادامهٔ سال تقویت میکند.
کجا در Q1 هزینه صرف شود
سهماهه اول زمان مناسب برای تثبیت پایهها در حالی است که برای الگوهای جدید کشف آماده میشویم. کارهای انجام شده در این دوره، نتایج حاصل در نیمسال اول را شکل میدهند.
پایههای فنی
با سلامت سایت آغاز کنید. عملکرد را بهبود دهید، موانع خزنده (crawl) را برطرف کنید، پیوندهای داخلی را بهروز کنید و معماری اطلاعات را تقویت کنید. سیستمهای هوش مصنوعی و مدلهای زبانی بزرگ (LLM) بهشدت به سیگنالهای پاک و سازگار وابستهاند؛ بنابراین، محیط فنی قوی، پشتیبان تمام محتوا، GEO و ابتکارات سنجش بعدی است.
محتوای غنی از نهادها و مبتنی بر سؤال
کاربران اکنون سؤالات گستردهتر و چند لایهتری مطرح میکنند و موتورهای AI محتوایی را که مفاهیم را بهروشنی تعریف میکند، بهصورت جزئی به سؤالات رایج پاسخ میدهد و عمق موضوعی معناداری ایجاد میکند، پاداش میدهند. در برنامههای محتوای ساختاریافته سرمایهگذاری کنید که با مشکلات واقعی مشتریان و مسیرهای آنها همراستا هستند؛ بهجای دنبالکردن حجم برای خود، بر وضوح، کارایی و معتبر بودن تمرکز کنید.
آزمایش اولیه GEO
همپوشانی قابلتوجهی بین سئو و حضور در LLM وجود دارد، زیرا هر دو به پایههای فنی قوی، سیگنالهای نهاد پیوسته و محتوای مفید که برای سیستمها بهراحتی قابل تفسیر باشد، وابستهاند. کشف LLM باید بهعنوان بخشی از سئو دیده شود نه بهعنوان یک رشتهٔ مستقل؛ زیرا بیشتر کارهایی که سئو را تقویت میکنند، حضور در LLM را نیز با بهبود وضوح، همخوانی و مرتبط بودن، تقویت مینمایند.
بخشهای خاصی شروع به تجربهٔ جزئیات جدید کردهاند. یک مثال، پروتکل تجارت هوشمند (Agentic Commerce Protocol یا ACP) است که بر چگونگی درک محصولات توسط سیستمهای AI، ارزیابی آنها و در برخی موارد انجام تراکنش با آنها تأثیر میگذارد.
چه این حوزه را بهعنوان GEO، AEO یا LLMO نام بگذاریم، اصل همان است – برندها اکنون برای چندین پلتفرم و مجموعهٔ در حال گسترش موتورهای کشف بهینهسازی میشوند، بهطوری که هر کدام تفسیر خاصی از سیگنالها دارند.
سهماهه اول زمان مناسبی برای ارزیابی نحوهٔ نمایش برند شما در این سیستمها است. مراکز پاسخ (answer hubs) را مرور کنید، روابط نهادهای خود را ارزیابی کنید و ببینید سیگنالهای ساختاریافته چگونه تفسیر میشوند. این آزمایش اولیه مسیرهایی را که بودجه در نیمسال اول باید گسترش یابد، مشخص میکند.
نگاه کلی به H1: مقیاسبندی موارد مؤثر
نیمسال اول زمانی است که بینشهای اولیهٔ Q1 به برنامههای مقیاسپذیر تبدیل میشوند.
تبدیل آزمایشهای موفق به عملیات روزمره (BAU)
زمانی که کشف اولیهٔ LLM یا ابتکارات محتواهای ساختاریافته نشانههای واضحی از جذب نشان میدهند، باید در سئو بهصورت عادی (BAU) ادغام شوند. رسمیسازی این روشها امکان رشد پیوسته را فراهم میآورد بدون آنکه هر فصل بهمنظور بودجهگذاری جدید نیاز باشد.
کاهش ابزارهای با بازدهی پایین و سرمایهگذاری مجدد در افراد و فرآیندها
سازمانهای بسیاری بیش از حد بر ابزارهایی هزینه میکنند که ارزش معناداری ارائه نمیدهند.
نیمسال اول فرصتی است برای بازبینی استفاده از ابزارها، شناسایی تکرارها و خاتمه دادن به پلتفرمهای کماستفاده. اختصاص این هزینه به افراد، کیفیت محتوا و بهبودهای عملیاتی عموماً نتایج بسیار بهتری بهدست میدهد. مسابقهٔ هوش مصنوعی که تقریباً تمام ارائهدهندگان ابزار در آن شرکت کردهاند، بهتدریج کاهش مییابد و آنهایی که ارزشی واضح ارائه میدهند، از شلوغی بیرون میآیند.
تنظیم ترکیب بودجه با ظهور دادهها
تا اواخر نیمسال اول، کسبوکار باید شواهد واضحتری از جایی که دیدهشدن تغییر میکند و چه فعالیتهایی بهطور واقعی بر کشف و تعامل تأثیر میگذارند، داشته باشد. سپس بودجهها باید برای پشتیبانی از موارد مؤثر، حفظ فعالیتهای هستهای سئو، گسترش حوزههای محتوای موفق و کاهش سرمایهگذاری در آزمایشهای بینتیجه، تنظیم شوند.
سؤالات مدیران ارشد بازاریابی (CMO) پیش از نهاییسازی
همانگونه که مدیران ارشد بازاریابی بودجههای سئو برای سال ۲۰۲۶ را بررسی میکنند، مرحلهٔ نهایی تأیید باید بر پایهٔ دیدی متعادل از تاکتیکهای هجومی و دفاعی شکل گیرد تا اطمینان حاصل شود سازمان هم در حرکت (متحرک) و هم در شتاب سرمایهگذاری میکند.
تاکتیکهای دفاعی از آنچه برند تا بهحال کسب کرده است محافظت میکنند: ثبات در رتبهبندیها، استمرار عملکرد فنی، ساختارهای محتوای قابلاعتماد و حفظ دیدارپذیری موجود در هر دو جستجو و تجربههای مبتنی بر هوش مصنوعی.
در مقابل، تاکتیکهای هجومی برای ایجاد نقاط جدید دیدارپذیری، آزادسازی دستههای جدید تقاضا و تقویت حضور برند در موتورهای کشف نوظهور طراحی میشوند.
یک بودجه متعادل باید هر دو را تأمین کند؛ زیرا بدون دفاع برند شکننده میشود و بدون هجمه نامرئی میماند.
مفهوم «حرکت» به فعالیتهایی اشاره دارد که به برند کمک میکند با محیطهای کشف در حال تحول سازگار شود؛ این شامل آزمایشهای اولیه کشف LLM، گسترش نهادها و مدرنسازی قالبهای محتوا است.
«شتاب» نمایانگر اثر ترکیبی سرمایهگذاری مستمر بر سئو هستهای و بهینهسازی منظم در مسیرهای کلیدی است.
مدیران ارشد بازاریابی باید بودجهها را بر پایهٔ توانایی تولید هر دو ارزیابی کنند: حرکتی که برند را برای آینده موقعیت میدهد و شتابی که رشد را حفظ میکند.
با این نگرش، مدیران ارشد بازاریابی ممکن است پیش از تصویب هر بودجهای پرسشهای زیر را مطرح کنند:
تا چه حد این بودجه تعادل بین فعالیتهای دفاعی مانند ثبات فنی و نگهداری محتوا و ابتکارات هجومی که دیدارپذیری آینده را گسترش میدهند، برقرار میکند؟
در طرح چهطور واضح نشان داده میشود که حرکت در اوایل ۲۰۲۶ از چه منابعی خواهد آمد و شتاب در خلال نیمسال اول چگونه محافظت و تقویت میشود؟
کدام عناصر برنامه بهطور مستقیم حضور برند را در سطوح هوش مصنوعی، GEO و سایر موتورهای کشف نوظهور تقویت میکند؟
استراتژی محتوا چهقدر بهصورت مؤثری نیازهای فوری کاربران و رشد بلندمدت دستهبندیها را پوشش میدهد؟
چگونه تغییرات دیدارپذیری برند در پلتفرمهای متعدد، از جمله جستجوی سنتی، پاسخهای مبتنی بر هوش مصنوعی و سیستمهای کشف خاص صنایع ردیابی میشود؟
نقش تیمها، فرآیندها و دادههای داخلی در حفظ حرکت و شتاب چهاست و آیا بهطور مناسب مورد تامین مالی قرار گرفتهاند؟
بهبودهای گزارشدهی چهطور به تیم رهبری اجازه میدهد تا موفقیت سرمایهگذاریهای دفاعی و هجومی را تا پایان نیمسال اول ارزیابی کند؟
منابع بیشتر:
چگونه توجیه کنیم و مورد تجاری برای بودجههای سئو بسازیم
چگونه در دورههای کم بار، با بودجه سئو بهصورت کارآمد عمل کنیم
لارِی فینک، رئیس هیئتمدیره و مدیرعامل بلکراک، بر روی صحنه در اجلاس Dealbook نیویورک تایمز 2025 که در مرکز جاز لینکلن برگزار شد، در تاریخ ۳ دسامبر ۲۰۲۵ در شهر نیویورک سخنرانی میکند. Michael M. Santiago/Getty Images
در گزارش امروز CEO Daily: داین بری دربارهٔ آنچه مدیران عامل در اجلاس DealBook میگفتند گزارش میکند.
خبر بزرگ: ترامپ استانداردهای کارایی خودرو را لغو میکند.
بازارها: عمدتاً صعودی.
به علاوه: تمام اخبار و گفتوگوهای اطراف آبسردکننده از Fortune.
صبح بخیر. دیروز را به گوشدادن به دهها رهبر کسبوکار در صحنه و خارج از صحنهٔ اجلاس New York Times DealBook، که بهدقت توسط اندرو راس ساکین مدیریت میشد، اختصاص دادم. من دعوت شدم تا گفتوگوی صبحانهایی اندیشهبرانگیز دربارهٔ مأموریت بهعنوان عامل رشد را با حضور گریگ دیویس، رئیس و مدیر سرمایهگذاری وندگار، مایکل گوندا، مسئول ارشد ارتباطات نایکی، و سیمون سِنِیک میزبانی کنم. نکتهای که برایم برجسته شد این بود: اگر رهبران مأموریت یک شرکت را درونیسازی و ساختاری نکنند، این صرفاً یک سخنچاری است.
با در نظر گرفتن این نکات، چند تم برای من شکل گرفت:
پذیرش وضعیت جدید. نظرات میتوانند بهسرعت تغییر کنند. اسکات بسنت، وزیر خزانهداری، نگرانیهای قبلیاش دربارهٔ رویکرد «حداکثری» ترامپ به جنگهای تجاری و تورم در ایالتهای دموکراتیک را رد کرد و گفت تفکرات او دربارهٔ تعرفهها «تکامل یافته» است. اما وقتی که برین آرمسترانگ، مدیرعامل Coinbase، دربارهٔ «عصر طلایی» در یکی از بدترین هفتههای رمزارزها سخن گفت یا ماری بارا، مدیرعامل جنرال موتورز، بهسادهگی تحولات ۱۸۰ درجهای در سیاستها را نادیده گرفت، درمییابید که ما به این وضعیت عادت کردهایم.
بهاستثنای واضحی که از جانب فرماندار کالیفرنیا، گاوین نیوسام وجود دارد، هیچکس کلمهٔ منفیای دربارهٔ ترامپ، تعرفهها یا بیشتر اتفاقات در عرصهٔ سیاستهای فدرال نداشت. یک رهبر تجاری خارجی به من گفت: «شگفتانگیز است که چه چیزی بهظاهر عادی بهنظر میرسد.»
نیاز رهبران به ایجاد اعتماد. کارشناس روابط عمومی ریچارد ادلمان به من گفت که باید منتظر دادههای نگرانکنندهٔ مربوط به تقسیمطبقهای جمعیتی در گزارش جدید «باداراعتمادی ادلمان» باشم. یک مدیرعامل مالی به ردیفی از محافظان سمتدار اشاره کرد و یادآور شد که تاریخ ۴ دسامبر سالگرد شلیک و کشته شدن بریان تامپسون، مدیرعامل UnitedHealthcare، چند بلوک دورتر است، در حالی که متهم فرضیاش در دادگستری مرکز شهر حضور داشت.
در صحنه، الکس کارپ از Palantir گفت که رهبران بهدلیل عدم ارائهٔ نظرات واقعی یا فرار از عواقب «تصمیمهای کاملاً احمقانه» اعتبار خود را از دست میدهند. او افزود که دیسلکسی او را وادار کرد تا آزادانه فکر کند؛ با «انفجار چیزها» اصطکاک ایجاد میکند و بر این باور است که شفافیت اصیل تا حد بیادبی، برای کارمندانی که میدانند او صادقانه دربارهٔ محصولات و دیگر جنبههای کسبوکار صحبت میکند، سودآور بوده است. او گفت: «کمارزیکردن مخاطبان خود» به معنای عدم ارایهٔ نظر است و این میتواند باعث از دست دادن دسترسی به افراد باهوش شود که در جاهای دیگر کار میکنند.
از حرف زدن درباره حبابهای هوش مصنوعی دست بکشید. قیمتداراییها ممکن است بالا باشد و برخی سرمایهگذاریها ممکن است احمقانه بهنظر برسند، اما مورد تجاری هوش مصنوعی بسیار قانعکننده است. لاری فینک، مدیرعامل بلکراک، دربارهٔ رشد درآمدی که خیلی سریعتر از افزایش نیروی کار است، سخن گفت. در گفتگوی میزی که توسط استیو کیس، همبنیانگذار AOL و سرمایهگذار استارتاپها رهبری میشد، دربارهٔ فرصتهای مقیاسپذیری نوآوری و حتی ایجاد یونیکورنیهای تکنفره صحبت کردیم.
داریو آمودی، مدیرعامل Anthropic، دلایل متقاعدکنندهای ارائه داد که سیاستگذاران و رهبران باید با کاهش شغلها و تغییرات اجتماعی مواجه شوند. اما مزایا واضح هستند. همانطور که یکی از شرکتکنندگان و مربی شناختهشدهٔ مدیران عامل، مارک فیگن، به من گفت: «تنها حباب ممکن است تمام این گفتوگوها درباره حبابهای هوش مصنوعی باشد.»
تماس با CEO Daily از طریق داین بری به نشانی diane.brady@fortune.com
اخبار برتر
ترامپ استانداردهای کارایی خودرو را لغو میکند
دونالد ترامپ، رئیسجمهور ایالات متحده، روز چهارشنبه استانداردهای بهرهوری سوختی دوره بایدن برای خودروها و کامیونهای سبک جدید را که برای مقابله با تغییرات آب و هوا و تشویق آمریکاییها به خرید خودروهای الکتریکی طراحی شده بود، تضعیف کرد. در کنار مدیران صنعت خودرو، ترامپ این استانداردها را «کلاهبرداری» نامید که برای آمریکاییها هزینههای زیادی دارد. پیشبینی میشود تعرفههای ترامپ هزینه خودروهای ساختدولتی را افزایش دهند.
سهمها پس از خبرهای شغلی صعود کردند
خبرهای بد برای کارگران، خبرهای خوب برای سهام بود. پردازشگر فهرست حقوقها ADP گزارش داد که حقوقهای بخش خصوصی در نوامبر ۳۲٬۰۰۰ کاهش پیدا کرد؛ در حالی که اقتصاددانان پیشبینی ۴۰٬۰۰۰ افزایشی داشتند. سرمایهگذاران این کاهش شگفتانگیز را بهعنوان نشانهای برای اینکه فدرال رزرو ماه آینده نرخ بهره را کاهش خواهد داد، تفسیر کردند و شاخصهای اصلی روز را صعودی به پایان رساندند.
بیشترین میلیاردرها تا بهحال
بر اساس یک مطالعهٔ جدید از UBS، جهان اکنون ۲٬۹۰۰ میلیاردر دارد؛ که نسبت به سال گذشته که ۲٬۷۰۰ میلیاردر بود، افزایش یافته است؛ این افراد مجموعاً ۱۵٫۸ تریلیون دلار کنترل میکنند. ارزیابیهای پرسر و بازار سهام پویا، در حال بهوجود آوردن میلیاردرها با سرعتی نزدیک به رکورد است.
افزایش مرگومیر کودکان
بر اساس گزارش بنیاد گیتس، تعداد مرگومیرهای کودکان در سال ۲۰۲۵ برای اولین بار پس از دههها افزایش خواهد یافت. بسیاری از این مرگهای اضافی که برآورداً ۲۴۳٬۰۰۰ نفر هستند، در کشورهایی مانند جمهوریدموکراتیک کنگو، سومالی و اوگاندا که با درگیری و سیستمهای بهداشتی ناپایدار مواجهاند، رخ داده یا خواهد شد. بیل گیتس این افزایش مرگومیرها را به کاهش ۲۷٪ در کمکهای بهداشتی جهانی از سوی کشورهای ثروتمند، از جمله ایالات متحده، نسبت میدهد.
شکهای مدیرعامل IBM درباره هوش مصنوعی
آرویند کرشنا، مدیرعامل IBM، درباره اینکه آیا شرکتهای بزرگ مقیاسپذیر مانند گوگل و آمازون میتوانند با نرخ هزینههای مراکز داده هوش مصنوعی خود، سودآور باشند، شک دارد. او گفت: «بهنظر من هیچ راهی برای بازدهی از این هزینهها وجود ندارد، چون ۸ تریلیون دلار سرمایهگذاری معنوی به این معنی است که برای پرداخت بهره حدود ۸۰۰ میلیارد دلار سود نیاز است.»
میلیاردر مایکل سایلور با خطر سقوط ۸ میلیارد دلاری روبروست
مایکل سایلور، میلیاردر، در شرایط دشواری قرار دارد؛ در حالی که بازار رمزارز بهطور مستمر نزولی است و شرکت او، Strategy، بهنظر میرسد که از مجموعهای از شاخصهای محبوب حذف شود. اگر Strategy بخواهد بخشی از ۶۵۰٬۰۰۰ بیتکوین خود را بفروشد، که سایلور و مدیرعامل Strategy اعلام کردهاند که شرکت مایل به این کار است، احتمال دارد که Strategy اولین دامینوی رمزارزی باشد که سقوط میکند.
بانک آمریکا پیشبینی میکند «کیسه هوایی» نه حباب در هوش مصنوعی
ساویتا سوبرامانیان، رئیس بخش سهام ایالات متحده و استراتژی کمیساز بانک آمریکا، این هفته نوشت که حباب هوش مصنوعی غیرممکن است. او پیشبینی کرد که بهجای آن «کیسه هوایی» در حال شکلگیری است، چرا که شرکتها بهصورت پرشتاب هزینهبر روی مراکز داده میکنند و اغلب به بدهی تکیه دارند.
شرکتها برای جذب استعدادهای هوش مصنوعی به «جنگ سوپ» میپردازند
در گفتگویی با پادکستساز فناوری اشلی ونس، افسر تحقیقات ارشد OpenAI، مارک چن، توضیح داد که جنگ این شرکت برای جذب استعدادها با متا اکنون شامل ارائه سوپ به متقاضیان است. پیشنهادات متا «دستپخت» توسط مدیرعامل مارک زاکربرگ است، در حالی که OpenAI سوپ را از یک رستوران پرآبزری کرهای سفارش میدهد.
بازارها
S&P 500 futures این صبح ثابت هستند. نشست قبلی ۰٫۳٪ صعودی بسته شد. STOXX Europe 600 در معاملات اولیه ۰٫۳٪ صعود داشت. FTSE 100 در معاملات اولیه ۰٫۱۴٪ صعود کرد. Nikkei 225 ۲٫۳۳٪ صعود کرد. CSI 300 ۰٫۳۴٪ صعود داشت. KOSPI ۰٫۱۹٪ نزول داشت. NIFTY 50 ۰٫۱۸٪ صعود کرد. Bitcoin در سطح ۹۳ هزار دلار ثابت بود.
در اطراف آبسردکننده
یک درصد ثروتمند به نمادهای جدیدی از مقام میپردازند که نمیتوان آنها را خرید؛ و این برای دیور، ورساچه و بوربری مشکلساز است. (توسط اِما برلی)
الکس کارپ به دیسلوکسی خود بهعنوان عامل موفقیت ۴۱۵ میلیارد دلاری Palantir اعتبار میدهد: «هیچ کتاب راهنمایی وجود ندارد که یک دیسلکسیست بتواند آن را مسلط شود… بنابراین ما یاد میگیریم آزادانه فکر کنیم.» (توسط Lily Mae Lazarus)
اسکات بسنت، تعهد اهدای «Giving Pledge» را نیتدار اما «بسیار نامعین» مینامد، که از «وحشت در میان طبقه میلیاردرها» رخ داده است. (توسط Nick Lichtenberg)
اسکات گالووی در دبیرستان عمدتاً نمرات B و C دریافت کرد، هرگز برای آزمون SAT مطالعه نکرد و برای پذیرش در UCLA دو بار تلاش کرد. اکنون دارایی او ۱۵۰ میلیون دلار است. (توسط Sydney Lake)
CEO Daily توسط جویی آبرامز، کلیر زیلفن و لی کلیفورد گردآوری و ویرایش میشود.
انیماتور میگوید هنرمندان نمیخواهند بهصورت دستی نقاشی کنند.
بخش زیادی از دفاع از هوش مصنوعی توسط مدیران صنعت بر این تمرکز کرده بود که هوش مصنوعی میتواند کارهایی را که خلاقان دوست ندارند انجام دهد. یک تهیهکننده پیشین نتفلیکس اکنون این موضوع را با بیانیهای نسبتاً جسورانهتر بهدست گرفته است.
تایکی ساکورای، که بهعنوان تهیهکننده اجرایی در پروژههای Pokémon Concierge و Cyberpunk: Edgerunners فعالیت داشته و اکنون سرپرست استودیوی انیمیشن Salamander Inc است، ادعا کرده است که خود انیماتورها هوش مصنوعی را میپسندند. او میگوید آنها نمیخواهند بهصورت دستی نقاشی کنند (اگرچه همچنان باید کارهای هوش مصنوعی را در بهترین نرمافزارهای انیمیشن به ویدیو تبدیل کنند).
طبق گزارش سایت ژاپنی Internet Watch و پوشش دادهشده توسط CBR، ساکورای در پنلی تحت عنوان «انقلاب صنعتی عامل هوش مصنوعی و پتانسیل ژاپن» در نمایشگاه تجاری CEATEC در اکتبر سخنرانی کرد.
او درباره تجربهاش در استفاده از هوش مصنوعی برای تولید، از جمله در پروژه «سگ و پسر» (پیشنمایش آن را در بالا ببینید) صحبت کرد. این فیلم کوتاه انیمه که بیش از دو سال پیش منتشر شد، بهدلیل استفاده از پسزمینههایی که بهطور کامل توسط هوش مصنوعی تولید شده بودند، یکی از اولین جنجالهای بزرگ هوش مصنوعی نتفلیکس به حساب میآید.
اما ساکورای بهنظر میرسد بر این باور است که تنها طرفداران است که با هوش مصنوعی مشکل دارند، در حالی که خود انیماتورها همه از آن حمایت میکنند.
او میگوید: «صداهای منفی نسبت به هوش مصنوعی از طرف طرفداران انیمه وجود دارد که میگویند ‘غیرانسانی است که انسانها جایگزین ماشینها شوند’. اما از دیدگاه کسانی که انیمه میسازند، کشیدن ۱۰۰٬۰۰۰ تصویر بهصورت کامل دستی نیز غیرانسانی به نظر میرسد.»
این نگاه احتمالاً بسیاری از انیماتورها و سایر هنرمندان را شگفتزده خواهد کرد. ما بارها دربارهٔ مخالفت خالقین با هوش مصنوعی گزارش کردهایم، هم بهدلیل ترس از از دست دادن شغل و هم بهدلیل نگرانی درباره اینکه بسیاری از مدلهای هوش مصنوعی بدون احترام به حقوق صاحبان حق تکثیر آموزش دیدهاند.
اما ساکورای همچنین اشاره کرد که چشمانداز از دست دادن مشاغل مشکلی نیست، حداقل در ژاپن، زیرا صنعت انیمه در واقع بهکمبود نیروی کار میرسد.
او افزود: «با کاهش نرخ تولد که به معنای ورود افراد کمتر به صنعت انیمه است، شوخیهای تاریکی در مورد این که در عصری که همهچیز توسط هوش مصنوعی جایگزین شده، هیچکس در استودیوی تولید باقی نخواهد ماند، بهوجود میآید.»
ساکورای تصدیق کرد که نظرات متفاوتی میان خالقین در بخشهای مختلف وجود دارد؛ هنرمندان مانگا بیشتر نسبت به هوش مصنوعی مخالفاند چون هوش مصنوعی توانایی تولید تصویرهای ثابت را بیش از ویدئو دارد، در حالی که ویدئوی هوش مصنوعی هنوز با مشکلات فنی مواجه است.
او میگوید: «بهمحض چاپ یک مانگا یا تصویر، احتمال واقعی وجود دارد که بلافاصله توسط هوش مصنوعی جایگزین شود. در مورد انیمه، حتی اگر فقط تصاویر باشند، نیاز است به ویدئو تبدیل شوند و در حال حاضر، این تبدیل هنوز یک مانع بزرگ است برای رسیدن به ویدئو.»
حتی اگر ساکورای درست باشد و انیماتورها استفاده از هوش مصنوعی را بپذیرند، باز هم اگر طرفداران آن را رد کنند، این یک مشکل جدی برای استودیوها خواهد بود.
بحث درباره هوش مصنوعی در انیمیشن و در تمام بخشهای خلاق، همچنان بهدلیل گستردگی بیش از حد موضوع، پیچیده است. ابزارهای انیمیشنی وجود دارند که از هوش مصنوعی برای تسریع فرایندها استفاده میکنند بدون اینکه اثر نهایی را تولید کنند، اما ساکورای به گزینه دوم تمایل نشان داده است.
در مورد واکنش منفی به «سگ و پسر» او گفت: «مردم نوشتند که نتفلیکس نهایتاً انسانها را حذف کرده و سعی دارد تمام ویدئوهای خود را با هوش مصنوعی بسازد». اما نظرات اخیر او بهنظر نمیرسد که مردم را قانع کند که این هدف نهایی نیست.
او فاش کرد که استودیوی جدیدش «سالمندر» در حال کار بر روی یک آزمایش است که یک مدل هوش مصنوعی را بر پایهٔ سبک هنری هنرمند مفهومی کنیچیرو تومیاسو آموزش میدهد تا او بتواند یک طرح ساده بکشید و هوش مصنوعی آن را به یک اثر نهایی تبدیل کند — بهنوعی شبیه Microsoft Paint Co‑Creator. ساکورای ادعا میکند که استودیوی او موافقت کرده است پس از پایان پروژه، مدل هوش مصنوعی را از بین ببرد.
بسیاری امیدوارند که نتفلیکس پس از این نظریه ساکورای مسیر خود را ادامه ندهد، بهویژه پس از احیای اخیرش در حوزه انیمیشن (کتاب هنری جدید «دنبالکنندگان شیاطین K‑Pop» را ببینید).
مطالعات صنعتی نگاههای متناقضی درباره جستجوی هوش مصنوعی ارائه میدهند. ببینید چرا دادهها متفاوت هستند و چگونه میتوانید تأثیر آن را بر سایت و بخش خود ارزیابی کنید.
پلتفرمهای بزرگ سئو مانند Ahrefs و Semrush، بههمراه آژانسهایی مثل Seer Interactive و سایر شرکتهای پیشرو، مطالعات قابلتوجهی منتشر کردهاند که بهنظر میرسد پاسخهای قطعی ارائه میدهند.
اما نگاهی دقیقتر چیزی کاملاً متفاوت نشان میدهد: تقریباً هر روایت ممکن دربارهٔ تأثیر جستجوی هوش مصنوعی، «مطالعهای» برای حمایت از خود دارد.
هر چه بیشتر به دادهها پرداختم، حقیقت ناخوشایندتری روشن شد – هیچکس پاسخ قطعی ندارد و میتوان ارقام را بهگونهای برش داد که تقریباً هر داستانی را تأیید کنند.
اجماع اصلی که واقعاً اجماع نیست
در نگاه اول، مطالعات بزرگ در اصول اساسی توافق دارند.
Ahrefs گزارش میدهد که نتایج ارگانیک برتر تقریباً ۳۴‑۳۴.۵٪ کلیک خود را از دست میدهند وقتی نمایشهای هوش مصنوعی ظاهر میشوند. تحلیل آنها بر پایه ۳۰۰,۰۰۰ کلمه کلیدی، این تأثیر را بهصورت واضح و قابلسنجش نشان میدهد.
آنها به پژوهشی اشاره میکنند که نرخ کلیکصفر تقریباً ۱۰۰٪ در حالت AI گوگل را نشان میدهد و اینگونه جستجوی هوش مصنوعی را تهدیدی اساسی برای ترافیک وبسایت میداند.
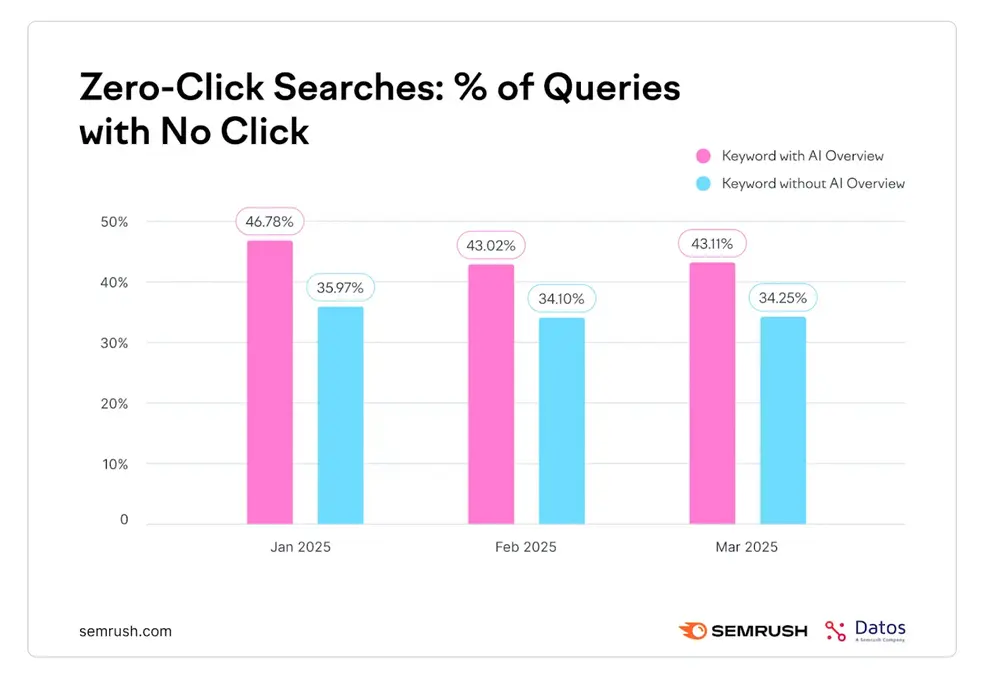
با این حال، Semrush که بیش از ۱۰ میلیون کلمه کلیدی را تجزیه و تحلیل کرده است، چیزی متفاوت یافت: کاهش کمی در جستجوهای بدون کلیک پس از معرفی نمایشهای هوش مصنوعی.
این مستقیماً با روایت اینکه ویژگیهای هوش مصنوعی بهطور اجتنابناپذیر رفتار کلیکصفر را افزایش میدهند، در تضاد است.
بهجای بحران، Semrush بر فرصت تأکید میکند و میگوید بازدیدکنندگان جستجوی هوش مصنوعی ۴.۴ برابر بازدیدکنندگان ارگانیک سنتی ارزشمندترند.
هیچیک از آنها میتواند کاملاً درست باشد، اما هر دو با استناد آماری ارائه میشوند.
بحث نرخ تبدیل: ۵ مطالعه، ۵ پاسخ متفاوت
سربار سردرگمی زمانی بیشتر میشود که به بررسی نحوه تبدیل ترافیک جستجوی هوش مصنوعی نسبت به ترافیک ارگانیک سنتی گوگل میپردازیم.
در اینجا، پژوهش تقریباً به دلیل تناقضهایش خندهدار میشود.
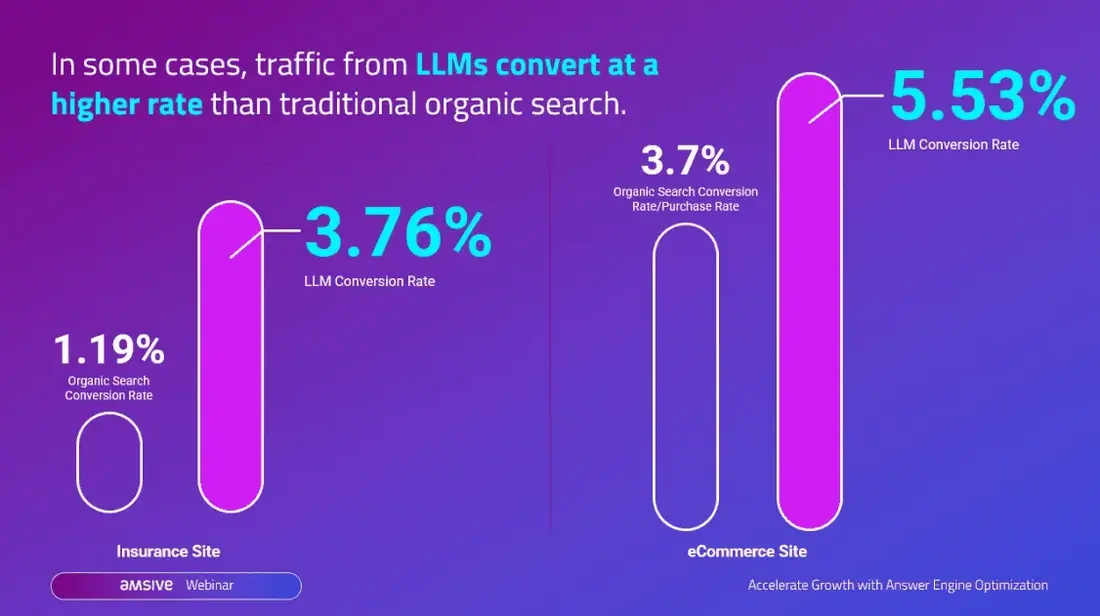
پژوهش Amsive که صدها وبسایت مشتری را تحلیل کرده، نتیجه گرفت که ChatGPT نرخ تبدیل بالاتری نسبت به گوگل دارد. این یافتهٔ «تفاوت» نشان میدهد که جستجوی هوش مصنوعی کاربران را با محتوای بالای قیف قبل از تبدیل آموزش میدهد و ارزش تجاری بالاتری دارد.
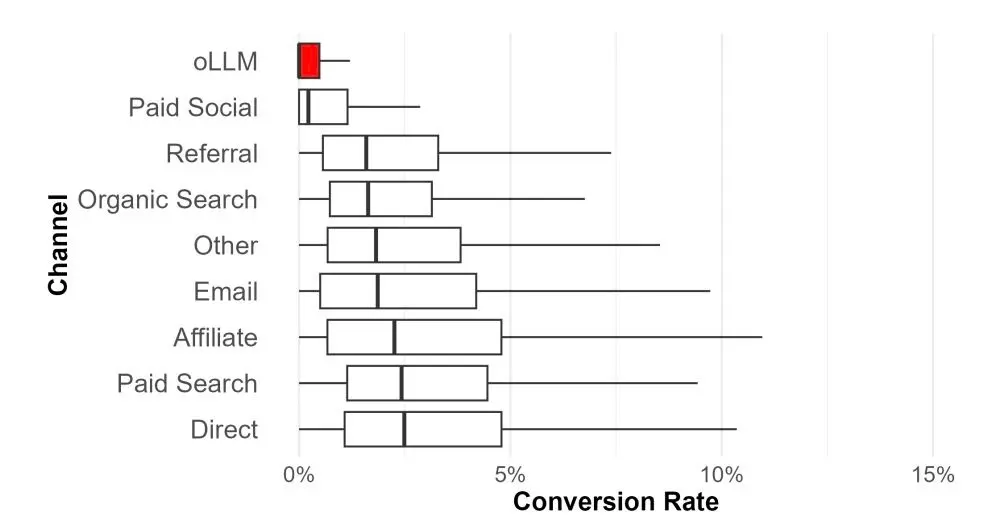
مطالعهای توسط Kaise و Schulze که بیش از ۹۷۳ وبسایت تجارت الکترونیک – گزارش شده توسط Search Engine Land – را بررسی کردند، به نتیجهٔ معکوس رسیدند: ChatGPT نرخ تبدیل کمتری نسبت به گوگل دارد. برای کسبوکارهای تجارت الکترونیک، این پژوهش نشان میدهد ترافیک جستجوی هوش مصنوعی کیفیت پایینتری دارد و احتمال کمتری برای تولید درآمد دارد.
Ahrefs دادههای تبدیل خود را بررسی کرد و دریافت که ChatGPT نرخ تبدیل بهتری نسبت به گوگل دارد. این با روایت کلی آنها که جستجوی هوش مصنوعی ممکن است حجم ترافیک را کاهش دهد، اما کیفیت ترافیک را افزایش میدهد، همراستا است.
Seer Interactive دادههای چندین وبسایت مشتری را تحلیل کرد و نیز به این نتیجه رسید که ChatGPT نرخ تبدیل بهتری نسبت به گوگل دارد، که تفسیر «کیفیت بر کمیت» را تأیید میکند.
Peep Laja، بنیانگذار Wynter، دادههای تبدیل شرکت خود را مرور کرد و به یک نتیجهٔ دیگر رسید: مدلهای زبانی بزرگ «ترافیک تنبل و نامعتبر» میفرستند که بهخوبی تبدیل نمیشود. تجربهٔ واقعی او از کسبوکار، تفاسیر خوشبینانه Ahrefs و Seer را به چالش میکشد.
پس کدام درست است؟
آیا ترافیک جستجوی هوش مصنوعی همانند گوگل، بهتر از گوگل یا بدتر از گوگل تبدیل میشود؟
بهنظر میرسد پاسخ این است: همه موارد، بسته به اینکه چه دادهای را بررسی میکنید.
چرا هر روایت شواهد حمایتی دارد
وجود مطالعات معتبر که به نتایج متناقض میرسند، نشانگر پیچیدگی و تغییرپذیری تأثیر جستجوی هوش مصنوعی است.
چندین عامل توضیح میدهند که چرا نتایج پژوهشها بهاینچنین اختلاف دارند.
صنعت و مدل کسبوکار نقش بسیار مهمی دارند
یافتهٔ Seer Interactive که نشان میدهد نمایشهای هوش مصنوعی تأثیر نامتناسبی بر ترافیک غیربرندیک دارند، این نکته را روشن میکند.
یک سایت تجارت الکترونیک که کالاهای عمومی میفروشد، احتمالاً تجربهٔ جستجوی هوش مصنوعی متفاوتی نسبت به یک شرکت نرمافزاری B2B یا ارائهدهنده خدمات محلی دارد.
مطالعهٔ Kaise و Schulze که بر وبسایتهای تجارت الکترونیک متمرکز بود، ممکن است واقعیتی کاملاً متفاوت نسبت به تحلیل Ahrefs از کسبوکار SaaS خود یا سبد مشتریان Seer به دست آورد.
قصد جستجو تنوع گستردهای ایجاد میکند
کاربری که از ChatGPT میپرسد «بهترین کفشهای دویدن برای پاهای صاف چیست؟»، ذهنیت بسیار متفاوتی نسبت به کسی دارد که همان سؤال را در گوگل مینویسد.
دومین ممکن است در مرحلهٔ پیشرفتهتری از تحقیقات خرید باشد، که توضیح میدهد چرا برخی مطالعات نشان میدهند ترافیک هوش مصنوعی نرخ تبدیل کمتری دارد.
یا ممکن است کاربران با دقت بیشتری پرسش کنند که توضیح میدهد چرا برخی دیگر نتیجه میگیرند تبدیل بهتر است. هر دو میتواند برای انواع مختلف پرسش درست باشد.
دورهٔ زمانی و تغییرات هوش مصنوعی نتایج را منحرف میکند
این مطالعات در ماههای مختلف سال ۲۰۲۵ انجام شدند، در حالی که ویژگیهای جستجوی هوش مصنوعی بهسرعت در حال تحول بودند.
پذیرندگان اولیه ابزارهای جستجوی هوش مصنوعی ممکن است جمعیتشناسی متفاوتی نسبت به کاربران عمده داشته باشند.
یک مطالعهٔ ماه آوریل پایه کاربری و مجموعه ویژگیهای متفاوتی نسبت به مطالعهٔ ماه نوامبر دارد.
اندازهنمونه و سوگیری انتخابی نتایج را تحریف میکند
صدها وبسایت مشتری Amsive، در مقایسه با بیش از ۹۰۰ سایت تجارت الکترونیک مورد بررسی در مطالعهٔ Kaise و Schulze، نمایانگر مقیاس دادهای و ترکیب صنعتی متفاوتی هستند.
Ahrefs که دادههای تبدیل خود را تحلیل میکند، ممکن است اثرات انتخابی پتانسیلی ایجاد کند.
مخاطبان آن بیشتر سئوکاران هستند که ممکن است رفتار متفاوتی نسبت به مصرفکنندگان عمومی داشته باشند.
تجربهٔ تکشرکتی Laja با Wynter ممکن است نکتهای خاص برای کسبوکار او باشد و نه یک الگوی جهانی.
تعاریف سنجش استاندارد نشدهاند
چی بهعنوان «تبدیل» محسوب میشود، در میان مطالعات متفاوت است.
آیا ما ثبتنام ایمیل، خرید، سرنخهای شایسته یا چیز دیگری را میسنجیم؟
چگونه ترافیک را وقتی کاربر از چندین کانال استفاده میکند، انتساب میدهیم؟
این تفاوتهای تعاریفی به تنهایی میتوانند یافتههای متناقض را توجیه کنند.
جدایی بزرگ در مقابل فرصت بزرگ
Ahrefs نتایج خود را تحت عنوان «جدایی بزرگ» (The Great Decoupling) چارچوببندی میکند.
نمایشها از طریق دوگانگی در نتایج ارگانیک و ارجاعهای AI Overview افزایش مییابند، اما کلیکهای کل کاهش مییابند.
این روایت بر از دست رفتن و آشفتگی تأکید میکند و جستجوی هوش مصنوعی را بهعنوان بازی صفر‑جمع میداند، به طوریکه گوگل ارزشی را که پیش از این بین وبسایتها توزیع میشد، به خود اختصاص میدهد.
(بهنظر میرسد جدایی بزرگ ناشی از ابزارهای هوش مصنوعی است که حجم عظیمی از نمایشها را ارسال میکردند؛ همانطور که Brodie Clark در Search Console مشاهده کرد.)
Semrush این پدیده را از طریق چشمانداز فرصت مطرح میکند. بله، حجم کلیکها تغییر میکند، اما بازدیدکنندگانی که کلیک میکنند، ارزش بیشتری دارند.
پیشبینی آنها مبنی بر اینکه جستجوی هوش مصنوعی تا سال ۲۰۲۸ میتواند ارگانیک سنتی را پیشی بگیرد، این تحول را بهعنوان تکامل ناگزیر میبیند که بازاریابان پیشرو باید آن را بپذیرند، نه که علیه آن مقاومت کنند.
هر دو سازمان به الگوهای دادهای مشابه نگاه میکنند اما روایتهای کاملاً متفاوتی میسازند.
Ahrefs بر کاهش ۳۴٪ کلیک تأکید میکند.
Semrush بر افزایش ۴.۴ برابر ارزش بازدیدکنندگان تأکید میکند.
هیچیک دروغ نمیگویند، اما داستانهای بسیار متفاوتی تعریف میکنند.
مسئلهٔ ارجاع: انقلابی یا تدریجی؟
هر سه مطالعهٔ بزرگ تحقیق نشان میدهند که از رتبهبندی به ارجاع تغییر رخ داده است؛ ذکر شدن در پاسخهای تولیدشده توسط هوش مصنوعی به همان اندازه یا حتی بیشتر از موقعیت سنتی اهمیت دارد.
اما حتی در اینجا نیز تفسیرها متفاوتاند.
دادههای Ahrefs که نشان میدهند ۷۶٪ ارجاعهای AI Overview از ۱۰ نتیجه برتر ارگانیک گوگل میآید، نشان میدهد این تغییر عمدتاً یک پیشرفت تدریجی است. اگر قبلاً بهخوبی از طریق سئوی سنتی رتبهبندی شدهاید، احتمالاً بیشتر ارجاع میشوید. سیستم موجود در بیشتر موارد دستنخورده باقی میماند.
با این حال، Semrush یادآور میشود که ابزارهای جستجوی هوش مصنوعی اغلب صفحات با رتبه پایینتر را ارجاع میدهند که نشان دهنده یک شکست انقلابی از سلسلهمراتب رتبهبندی سنتی است.
یافتهٔ Seer Interactive که نشان میدهد جستجوهای برندیک نسبت به غیربرندیک تأثیرات متفاوتی دارند، لایهای دیگر به این معادله میافزاید. اقتصاد ارجاع ممکن است بسته به نوع پرسش بهطور بنیادی متفاوت عمل کند.
آیا پدیدهٔ ارجاع تنظیم جزئی در روشهای سئو موجود است یا تحول کلی؟
دوباره، یک مطالعه وجود دارد که هر روایت دلخواه شما را پشتیبانی میکند.
متغیر پنهان: آنچه هر پژوهشگر میخواهد درست باشد
قابلتوجه است که هر سازمانی که این پژوهش را انجام میدهد، منافع تجاری دارد که ممکن است بر چارچوببندی (framing) اثر بگذارد، حتی اگر روششناسی را تغییر ندهد.
Ahrefs ابزارهای سئوی خود را میفروشد که عمدتاً بر بهینهسازی جستجوی سنتی تمرکز دارند.
روایت که بر مختلکردن و پیچیدگی تأکید دارد، نیاز به ابزارهای پیشرفته و تخصص را تقویت میکند.
پژوهش آنها که کاهش کلیکها و چالش سازگاری با جستجوی هوش مصنوعی را برجسته میکند، به مدل کسبوکارشان خدمت میکند.
Semrush یک پلتفرم جامع بازاریابی دیجیتال ارائه میدهد که شامل ابزارهای مبتنی بر هوش مصنوعی است.
روایتی که بر فرصت و تکامل تأکید دارد تا بحران، آنها را بهعنوان راهنمایان پیشرو برای آینده معرفی میکند. چارچوب خوشبینانهٔ آنها دربارهٔ کیفیت بازدیدکنندگان هوش مصنوعی، موقعیت استراتژیکشان را تقویت میکند.
Seer Interactive بهعنوان یک آژانس، از پیچیدگیای که نیاز به راهنمایی متخصص دارد، بهرهمند میشود.
یافتههای دقیق آنها دربارهٔ تأثیر برنبرندیک در مقابل برندیک – و تفاوتها در میان انواع مشتریان – ارزش مشاورهٔ استراتژیک سفارشی را نسبت به رویکردهای «یکچندحالت» تقویت میکند.
پژوهشگران بهطور طبیعی تمایل دارند به تفسیری که با نگرش و مدل کسبوکار خود همراستاست، گرایش داشته باشند.
واقعیت ویژه بهازای هر بخش
صادقانهترین نتیجهگیری از بررسی تمام این پژوهشهای متناقض این است که تأثیر جستجوی هوش مصنوعی بهطور رادیکال به هر بخش خاص بستگی دارد.
پاسخ صحیح به سؤال «جستجوی هوش مصنوعی روی ترافیک و تبدیلها چه تأثیری دارد» این است: «بهشرایط بستگی دارد».
این به موارد زیر بستگی دارد:
صنعت شما.
مدل کسبوکار شما.
آیا ترافیک شما برندیک است یا غیربرندیک.
موقعیت مشتریان شما در مسیر خرید.
نوع محتوای شما.
جمعیتشناسی خاص و الگوهای رفتار مخاطبان شما.
یک سایت تجارت الکترونیک که کالاهای عمومی را از طریق محتوای اطلاعاتی میفروشد، ممکن است واقعاً سناریوی کابوس Ahrefs را تجربه کند: کاهش ۳۴٪ کلیک بدون افزایش کیفیت جبرانکننده.
یک شرکت نرمافزاری B2B با شناخت برند قوی ممکن است همانطور که Semrush توصیف میکند، از فرصت بهرهمند شود: بازدیدکنندگان کمتر اما با کیفیت بالاتر.
یک کسبوکار خدمات محلی ممکن است تأثیر جستجوی هوش مصنوعی را بهطور کل تقریباً احساس نکند، بهشرطی که مشتریان عمدتاً از جستجوهای برندیک استفاده کنند.
تجربهٔ Laja با Wynter که میگوید مدلهای زبانی بزرگ «ترافیک تنبل و نامعتبر» میفرستند که بهخرابی تبدیل میشود، ممکن است برای کسبوکار او که با مطالعات موردی دقیق، مشتریان B2B را تبدیل میکند، کاملاً دقیق باشد.
این به این معنا نیست که یافتهٔ Ahrefs مبنی بر اینکه ترافیک هوش مصنوعی آنها بهخوبی تبدیل میشود، نادرست است؛ چرا که آنها در بخشهای مختلف با مخاطبان متفاوت و محتوای گوناگون فعالیت میکنند.
توهم روششناسی در مورد قطعیت
نمونههای بزرگ میتوانند حس قطعیت نادرستی ایجاد کنند که شاید توجیهپذیر نباشد.
مطالعهٔ Kaise و Schulze که بیش از ۹۰۰ سایت تجارت الکترونیک را بررسی کرد، شبیه بهنظر میرسد جامع و قطعی باشد.
اما ۹۰۰ سایت تجارت الکترونیک، هرچند تعداد زیادی هستند، باز هم نمایانگر یک بخش خاص با ویژگیهای مشترک هستند.
یافتهها ممکن است برای تجارت الکترونیک کاملاً دقیق باشند اما برای خدمات B2B، نشر یا کسبوکارهای محلی بهطور کامل نادرست باشند.
بهصورت مشابه، تحلیل Ahrefs از ۳۰۰,۰۰۰ کلمه کلیدی و بررسی Semrush از ۱۰ میلیون کلمه کلیدی مقیاس چشمگیری ارائه میدهند، اما امکان وجود سوگیریهای سیستماتیک را در موارد زیر حذف نمیکنند:
چگونه کلمات کلیدی مورد مطالعه قرار گرفتند.
چگونه اثرات سنجش شدند.
متغیرهای مخدوشکنندهای که کنترل نشدهاند.
اطمینانی که این مطالعات با درصدهای مشخص و نتایج قطعی ارائه میدهند، ممکن است بیش از آنچه دادهها نشان میدهند باشد.
چارچوب صادقانهتر باید عدم قطعیت و تغییرپذیری را بپذیرد، اما این امر داستانی جذاب برای بازاریابی یا رهبری فکری صنعت نیست.
چه معنایی برای سئوکاران و بازاریابان دارد
برای متخصصان سئو، بازاریابان و صاحبان وبسایتی که میخواهند بفهمند چه اتفاقی میافتد، پژوهشهای متناقض یک چالش به حساب میآیند.
نمیتوانید صرفاً به «دادهها» اعتماد کنید؛ زیرا دادهها بسته به اینکه چه کسی آنها را تحلیل میکند و چه چیزی را میسنجد، داستانهای متفاوتی میگویند.
دالان عملی این است که باید تحلیل خود را برای وضعیت خاص خود انجام دهید، نه اینکه به مطالعات صنعتی برای گفتن آنچه رخ میدهد تکیه کنید.
منابع ترافیک خود را بهدقت پیگیری کنید. نرخ تبدیل را بر مبنای کانال اندازهگیری کنید. هم حجم و هم معیارهای کیفیت را زیرنظارت داشته باشید.
بهویژه رفتار ترافیک جستجوی هوش مصنوعی را برای کسبوکار خود بررسی کنید، نه اینکه به میانگین صنعتی تجمیعی بسنده کنید.
مطالعات فرضیاتی برای آزمون فراهم میکنند، نه نتایج قطعی که باید پذیرفت.
پاسخ بهصورت خاص برای بخش شما خواهد بود و تنها راه برای شناخت آن، اندازهگیری دقیق دادههای خودتان است.
مشکل انتخاب روایت
بهمحض ظهور مطالعات بیشتر در حوزه جستجوی هوش مصنوعی، یک الگوی واضح قابلمشاهده است: همین پدیده میتواند بهطرزهای متفاوتی تفسیر شود.
بسته به نحوهٔ برش دادهها – بخش مورد مطالعه، دورهٔ زمانی تحلیلشده یا معیارهای مورد تأکید – پژوهش میتواند طیفی گسترده از نتایج درباره ترافیک، کیفیت و تأثیر کلی را پشتیبانی کند.
هر تفسیر میتواند بهنظر دادهمحور و دقیق باشد، اما برداشتهای استراتژیک اغلب در تضاد هستند.
این محیط باعث میشود سوگیری تأییدی بهراحتی بروز کند.
تیمها بهطور طبیعی مطالعاتی را که با پیشفرضها یا اهداف استراتژیک خود همراستاست، ترجیح میدهند و به پژوهشهایی که جهت متفاوتی نشان میدهند، وزن کمتری میدهند.
نتیجه این است که گفتوگوی صنعتی بهگونهای است که بسیاری باور دارند «دادهها را دنبال میکنند»، اما دادههای موجود میتوانند روایتهای متعددی را پشتیبانی کنند – و روایت انتخابی معمولاً بازتابدهندهٔ اولویتها و زمینههاست نه حقیقتی مطلق و یکپارچه.
حقیقت دربارهٔ عدم قطعیت
صنایع سئو و بازاریابی دیجیتال بر وعدهٔ تصمیمگیری دادهمحور بنا شدهاند.
ما اندازهگیری میکنیم، آزمون میگذاریم، بهینهسازی میکنیم و بازده سرمایهگذاری (ROI) را ثابت میکنیم.
وجود مطالعات بزرگ و بهخوبی انجامشده که به نتایج متناقض میرسند، این چارچوب را به چالش میکشد.
این نشان میدهد که حتی با مجموعههای داده بزرگ و تحلیلهای پیشرفته، درک پدیدههای پیچیده و چندمتغیره مانند تأثیر جستجوی هوش مصنوعی ممکن است فراتر از تواناییهای کنونی ما باشد.
سیستمها بیش از حد پیچیدهاند، متغیرها بیش از حد فراوان، بخشها بیش از حد متمایز، و چشمانداز بهسرعت در حال تحول است تا هر مطالعهٔ واحد بتواند حقیقت قطعی را بهدست آورد.
این به این معنا نیست که پژوهش بیفایده است؛ برعکس.
مطالعاتی که Ahrefs، Semrush، Seer Interactive و دیگران ارائه میدهند، نقاط دادهای ارزشمند و چارچوبهایی برای تفکر دربارهٔ تأثیر جستجوی هوش مصنوعی فراهم میکنند.
اما آنها نمیتوانند اطمینان و پاسخهای کلی و جهانی که بازاریابان نیاز دارند و بهدنبال آنها هستند، فراهم کنند.
گامهای پیشرو بدون همخوانی نظرات
راه پیشرو نیاز به سطح سالمی از شکگرایی روششناختی دارد.
وقتی یک مطالعه نتیجه میگیرد که جستجوی هوش مصنوعی کلیکها را کاهش میدهد، تبدیل را بهبود میبخشد یا تأثیر قابلسنجشی کمی دارد، مفیدترین واکنش بهسادهگی این است:
«پژوهش جالبی است. فکر میکنم چه عواملی این نتیجه را شکل دادهاند و آیا این نتایج برای وضعیت من نیز صادقند.»
بهجای جستجوی یک مطالعهٔ حقیقی که تأثیر قطعی جستجوی هوش مصنوعی را نشان میدهد، کارشناسان باید:
پذیرش خاصیت بخشبندی: تجربهٔ شما بسته به صنعت، مدل کسبوکار، نوع محتوا، مخاطب و متغیرهای دیگر متفاوت خواهد بود. نتایج کلی عمومی ارزش محدودی دارند.
انجام اندازهگیری دقیق خود: منابع ترافیک جستجوی هوش مصنوعی را پیگیری کنید، نرخ تبدیل را بر مبنای کانال اندازهگیری کنید، هم حجم و هم معیارهای کیفیت را زیرنظارت داشته باشید و دادههای خاص خود را برای هدایت استراتژی به کار ببرید.
آزمون چندین فرضیه: بهجای فرض اینکه Ahrefs یا Semrush درستاند، هر دو امکان را آزمایش کنید. بهینهسازی برای ارجاعهای AI را انجام دهید، در حالی که نظارت میکنید آیا کیفیت ترافیک به اندازهٔ کافی بهبود مییابد تا کاهش حجم را جبران کند. پاسخ ممکن است برای انواع محتواهای مختلف در سایت شما متفاوت باشد.
سؤال پرسیدن از روایتها: وقتی پژوهش بهطور کامل با منافع تجاری سازمانی که انجام میدهد همراستاست، با شکگرایی سالم برخورد کنید. این به این معنا نیست که دادهها نادرستند، اما نحوهٔ چارچوببندی و تأکید بر جنبههای خاص، اهمیت زیادی دارد.
با ابهام راحت باشید
حقیقت ناخوشایند است: حتی با وجود مطالعات چندگانهٔ مقیاس بزرگ از شرکتهای معتبر و پیشرو در صنعت، هنوز پاسخ واضحی دربارهٔ تأثیر جستجوی هوش مصنوعی نداریم.
ما نقاط دادهای، فرضیات، یافتههای خاص بهازای هر بخش و روایتهای تجاری داریم – نه نتایج قطعی.
مطالعهای که «همه چیز را حل کند» وجود ندارد، زیرا مسئله بیش از حد پیچیده و متغیر است.
پژوهشگران میتوانند شواهدی برای تقریباً هر ادعایی پیدا کنند، بسته به اینکه چه چیزی را اندازهگیری میکنند و چگونه آن را چارچوببندی میکنند.
این به این معنا نیست که پژوهش بیفایده است یا همهٔ نتایج وزن یکسانی دارند.
به این معناست که زمینه اهمیت دارد، تنوع میان بخشها طبیعی است و تواضع فکری بر قطعیت نادرست ساختهشده بر پایهٔ پژوهشهای منتخب برتر میغلبند.
صرفنظر از روایت – بحران یا فرصت، اختلال یا تحول – همیشه میتوان پژوهشی یافت که از آن پشتیبانی کند.
مسیر هوشمندانه این است که نتایج را بهخفیف بپذیریم، آزمایشهای خودمان را انجام دهیم و در برابر تغییرات مستمر صنعت انعطافپذیر بمانیم.
کاش آنها فقط روباتیک بودند! اما در عوض، چتباتها صدایی متمایز — و خراشان — به دست آوردهاند.
در زمزمهی آرام عصر دیجیتالمان، صدای جدیدی ادبی به گوش میرسد. میتوانید این سبک خاص را در همهجا ببینید — از صفحات رمانهای پرفروش تا ستونهای روزنامههای محلی، حتی در متن منوهای سفارش غذا. با این حال، نویسنده انسان نیست، بلکه شبحی است — نجواای که از الگوریتم بافته شده و ساختاری از کد. متون تولیدشده توسط هوش مصنوعی، که روزی پژواکی دور از رویاهای علمی‑تخیلی بود، اکنون در همهجا است — بهصورت بستهبندی منظم، موقتاً مورد ستایش قرار میگیرد و بهصورت بیپایان بازیافت میشود. این فقط یک سیلاب نیست — بلکه یک جریان فراگیر است. اما صدای این نویسنده چیزی ناآرامکننده دارد. هر جمله میخواند، بله، اما صادقانه بگویم؟ کمی خستهکننده است. این متن نه بافت تجربه انسانی را میگشاید — بلکه طوری خوانده میشود که گویی توسط فردی منزوی با وای‑فای و یک فرهنگ لغت نغنچهنویس نوشته شده است. نه حسی، نه واقعی، فقط … وجود دارد. و همانطور که نوشتن توسط هوش مصنوعی فراگیرتر میشود، سؤال مهمتری برانگیخته میشود — خلاقیت، اصالت یا صرفاً انسان بودن چه معنایی میگیرند وقتی که بسیاری ترجیح میدهند به نوشتار عجیب و غریب ماشین غوطهور شوند؟
اگر از من شبیه باشید، از خواندن آن پاراگراف لذت نخواهید برد. تمام جزئیات آن حس هشداری را در من بیدار میکند: اینجا چیزی اشتباه است؛ این متن آنچه ادعا میکند نیست. این یکی از آنها است. کلمات کاملاً عادی، مانند «تَپِستری»، که بیش از ۵۰۰ سال بهسادگی نوعی فرش عمودی را توصیف میکرد، ناگهان مرا تحت فشار میگذارند. هر جملهای که از الگوی «نه X، بلکه Y» پیروی کند، من را به نقطهای میرساند که به عصبانیترین حد میرساند، حتی اگر این ساختار کاملاً معمولی در آثار ادبی بسیار محترمی همچون کتاب مقدس و شکسپیر هم ظاهر شود. اما این نکات کوچک زبانی که قبلاً معنای خاصی داشتند، اکنون دیگر همان معنا را ندارند. همه اینها الآن نشانههای واضحی هستند که نشان میدهند آنچه میخوانید توسط هوش مصنوعی تولید شده است.
زمانی که نویسندگان فراوان و سبکهای متفاوتی وجود داشتند. اکنون، بهتدریج، یک نویسنده ناشناس تقریباً تمام چیزها را مینویسد. گمان میشود که این نویسنده تقریباً تمام مقالات دانشجویان مقطع کارشناسی در تمام دانشگاههای جهان را مینویسد و دلیلی وجود ندارد که بگویم شاخههای معتبرتر نوشتار از این پدیده مصونند. سال گذشته، یک نظرسنجی توسط جامعهی نویسندگان بریتانیا نشان داد که ۲۰ درصد از نویسندگان داستانی و ۲۵ درصد از نویسندگان علمی‑غیر‑داستانی اجازه میدادند هوش مصنوعی تولیدی بخشی از کارشان را انجام دهد. مقالههای پر از مطالب عجیب و نادرست که بهنظر میرسید توسط هوش مصنوعی تولید شدهاند، در Business Insider، Wired و The Chicago Sun‑Times کشف شدهاند، اما احتمالاً صدها، اگر نه هزاران مقاله دیگر نیز بهطور ناشناخته باقی ماندهاند.
بهزودی، تقریباً تمام نوشتار ممکن است نوشتار هوش مصنوعی باشد. در شبکههای اجتماعی، این امر قبلاً رخ داده است. اینستاگرام یک هوش مصنوعی یکپارچه در سیستم نظرات خود پیادهسازی کرده است: بهجای گذاشتن یادداشت عجیبخودتان بر روی سلفی یک غریبه، به هوش مصنوعی متا اجازه میدهید افکار شما را به زبان خود ترجمه کند. این میتواند «خندهدار»، «حمایتی»، «غیررسمی»، «غیرمعقول» یا «اموجی» باشد. در حالت «غیرمعقول»، بهجای گفتن «خوب بهنظر میرسی»، میتوانم بگویم «آنقدر تیز هستی که من خودم را بر روی طراوت تو خراشیدم». تقریباً تمام سرویسهای ایمیل بزرگ اکنون خدمات مشابهی ارائه میدهند. پیام پراکندهتان میتواند بهسرعت به زبان روان هوش مصنوعی ترجمه شود.
اعتبار… تصویرگری توسط جیاکومو گامبینری
اگر تصمیم بگیریم تمام ارتباطات را به نويسندهی همهجانبه (Omniwriter) بسپاریم، نوع نویسنده مهم میشود. به طرز عجیبی، هوش مصنوعی به نظر نمیرسد این را بداند. اگر از چتجیپیتی بپرسید سبک نوشتاری خودش چگونه است، بهظاهر با تواضع کاذب میگوید نوشتارش زیبا و دقیق است اما بهگونهای خالی است: بیش از حد تمیز، بیش از حد کارآمد، بیش از حد خنثی، بیش از حد کامل، بدون هیچیک از نقصهای ظریف که نوشتار انسانی را جالب میکند. در واقع، این اصلاً درست نیست. نوشتار هوش مصنوعی با مجموعهای از ویژگیهای بلاغی بهطرزی عجیب و غریب مشخص میشود که آن را بلافاصله برای هر کسی که تا به حال با آن مواجه شده، متمایز میسازد. این اصلاً صاف یا خنثی نیست — بلکه عجیب است.

 آیا این بار متفاوت خواهد بود؟
آیا این بار متفاوت خواهد بود؟