هوش مصنوعی چگونه روش کاری ما را تغییر میدهد؟ پژوهش قبلی ما دربارهٔ تأثیرات اقتصادی هوش مصنوعی بهصورت کلی بهسر بازار کار پرداخت و طیف وسیعی از مشاغل را در بر میگرفت. اما اگر برخی از اولین پذیرندگان فناوری هوش مصنوعی را بهجزییات بیشتری بررسی کنیم — یعنی خودمان — چه میشود؟
با نگاه به درون، در آگوست ۲۰۲۵ ما از ۱۳۲ مهندس و پژوهشگر Anthropic نظرسنجی کردیم، ۵۳ مصاحبهٔ کیفی عمیق انجام دادیم و دادههای استفادهٔ داخلی Claude Code را بررسی کردیم تا بفهمیم استفادهٔ هوش مصنوعی چگونه در Anthropic تغییر میآورد. دریافت کردیم که استفاده از هوش مصنوعی بهطور اساسی ماهیت کار برنامهنویسان نرمافزار را تغییر میدهد و هم امید و هم نگرانی ایجاد میکند.
تحقیق ما محیط کاری را که تحت تحولهای چشمگیر قرار دارد، نشان میدهد: مهندسان کارهای بسیار بیشتری انجام میدهند، بهصورت «فول‑استاک» (قادر به موفقیت در وظایفی فراتر از تخصص معمول خود) میشوند، سرعت یادگیری و تکرار خود را سرعت میبخشند و به وظایفی که پیشتر نادیده گرفته میشدند میپردازند. این گسترش دامنه باعث میشود افراد دربارهٔ تعادلات فکر کنند — برخی نگران این هستند که ممکن است بهدلیل این پیشرفت، توانایی فنی عمیقتری را از دست بدهند، یا توانایی نظارت مؤثر بر خروجیهای Claude را کم کنند، در حالی که دیگران این فرصت را برای تفکر گستردهتر و در سطوح بالاتر میپذیرند. برخی دریافتند که همکاری بیشتر با هوش مصنوعی بهمعنی همکاری کمتر با همکاران است؛ برخی دیگر تعجب میکنند که آیا ممکن است در نهایت خودشان را از شغل حذف کنند.
ما میپذیریم که مطالعهٔ تأثیر هوش مصنوعی در شرکتی که خود هوش مصنوعی میسازد، نشانگر موقعیتی متمایز است — مهندسان ما دسترسی زودهنگام به ابزارهای پیشرفته دارند، در حوزهای نسبتاً پایدار کار میکنند، و خودشان در تحول هوش مصنوعی ای که سایر صنایع را تحت تأثیر قرار میدهد، مشارکت میکنند. با وجود این، احساس کردیم که بهطور کلی مفید است این نتایج را پژوهش و منتشر کنیم، زیرا آنچه داخل Anthropic برای مهندسان رخ میدهد ممکن است پیشنمایندهای آموزنده برای تحول گستردهتری در جامعه باشد. نتایج ما چالشها و ملاحظاتی را نشان میدهد که ممکن است نیاز به توجه زودهنگام در بخشهای مختلف داشته باشد (اگرچه برای نکات محدودیتها بخش «محدودیتها» در پیوست را ببینید). در زمان جمعآوری این دادهها، Claude Sonnet 4 و Claude Opus 4 قدرتمندترین مدلهای موجود بودند و تواناییها همچنان پیشرفت میکنند.
هوش مصنوعی پیشرفتهتر مزایای بهرهوری را به همراه دارد، اما در عین حال سؤالاتی دربارهٔ حفظ تخصص فنی، حفظ همکاری معنادار و آمادگی برای آیندهای نامطمئن که شاید بهرویکردهای جدیدی برای یادگیری، راهنمایی و توسعهٔ شغلی در محیط کاری تقویتشده با هوش مصنوعی نیاز داشته باشد، برمیانگیزد. ما برخی گامهای اولیهای را که برای بررسی این سؤالات بهصورت داخلی اتخاذ میکنیم در بخش «نگاهی به آینده» زیر بحث میکنیم. همچنین در پست اخیر وبلاگمان به ایدههای سیاستگذاری اقتصادی مرتبط با هوش مصنوعی، بهبررسی واکنشهای سیاسی ممکن پرداختهایم.
نتایج کلیدی
در این بخش، بهطور خلاصه نتایج نظرسنجی، مصاحبهها و دادههای Claude Code را مرور میکنیم. جزئیات، روشها و نکات محدودیتها در بخشهای بعدی ارائه میشود.
دادههای نظرسنجی
- مهندسان و پژوهشگران Anthropic بیشترین استفاده را از Claude برای رفع خطاهای کد و یادگیری دربارهٔ پایگاه کد دارند. اشکالزدایی و درک کد، رایجترین کاربردها هستند (شکل ۱).
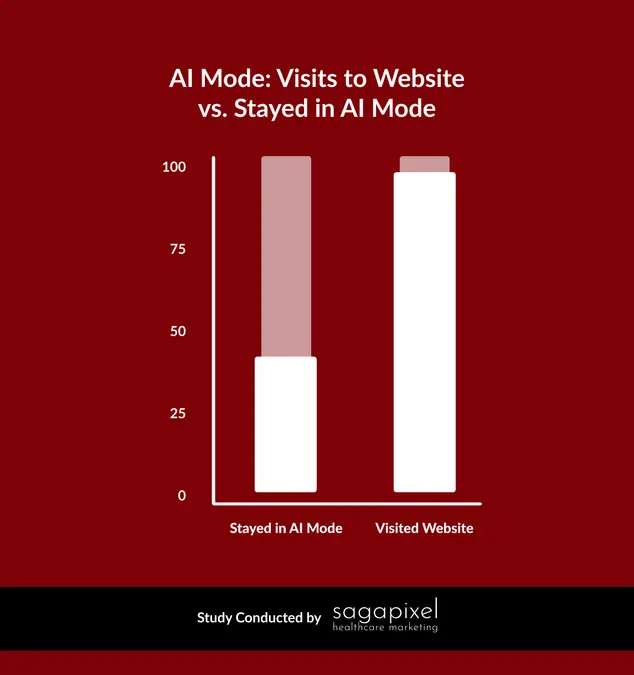
- افراد گزارش میدهند که استفاده از Claude و بهرهوری خود را افزایش دادهاند. کارکنان خود گزارش میکنند که در ۶۰٪ کارهای خود از Claude استفاده میکنند و بهرهوری را بهمقدار ۵۰٪ ارتقا میدهند؛ یعنی نسبت به سال گذشته ۲‑۳ برابر افزایش دارد. این بهرهوری نشان میدهد زمان صرفشده در هر دستهٔ کار کمی کمتر است، اما حجم خروجی بهمراتب بیشتر میشود (شکل ۲).
- ۲۷٪ از کارهای همراه با Claude شامل وظایفی هستند که در غیر این صورت انجام نمیشدند، مانند گسترش پروژهها، ساخت ابزارهای «nice‑to‑have» (مثلاً داشبوردهای دادهٔ تعاملی) و کارهای اکتشافی که اگر بهصورت دستی انجام شوند، هزینهکارآمدی ندارند.
- بیشتر کارکنان بهطور مکرر از Claude استفاده میکنند و گزارش میدهند که میتوانند «بهطور کامل» تنها ۰‑۲۰٪ کار خود را به آن واگذار کنند. Claude یک همکار ثابت است، اما استفاده از آن معمولاً شامل نظارت فعال و اعتبارسنجی است، بهویژه در کارهای حساس — در مقابل واگذاری وظایفی که نیازی به تأیید ندارند.
مصاحبههای کیفی
- کارمندان در حال توسعهٔ حس درک برای واگذاری هوش مصنوعی هستند. مهندسان تمایل دارند وظایفی را واگذار کنند که بهراحتی قابل تأیید هستند، جایی که میتوانند «بهطور نسبتاً آسان صحت آن را سنجش کنند»، با ریسک کم (مثلاً «کدهای آزمایشی یا پژوهشی فوری») یا خستهکننده («هرچه بیشتر مشتاق انجام وظیفه باشد، کمتر احتمال دارد از Claude استفاده کند»). بسیاری توالی اعتمادی را توصیف میکنند؛ ابتدا با وظایف ساده شروع میکنند و بهتدریج کارهای پیچیدهتر را واگذار مینمایند — در حالی که هنوز بیشتر وظایف طراحی یا «سلیقه» را خودشان حفظ میکنند، این مرز در حال بازنگری است با بهبود مدلها.
- مجموعه مهارتها به حوزههای بیشتری گسترش مییابد، اما برخی کمتر تمرین میکنند. Claude به افراد اجازه میدهد مهارتهای خود را به حوزههای بیشتری در مهندسی نرمافزار گسترش دهند (مثلاً «من میتوانم بهخوبی در فرانتاند یا پایگاه دادههای تراکنشی کار کنم… در حالی که پیش از این از دست زدن به این موارد میترسیدم»)، اما برخی کارمندان بهطور متناقض نگران انقباض مهارتهای عمیقتری هستند که برای نوشتن و نقد کد لازم است — «وقتی تولید خروجی اینچند آسان و سریع است، سختتر میشود که واقعاً زمان بگذاریم تا چیزی یاد بگیریم.»
- تغییر رابطه با هنر کدنویسی. برخی مهندسان کمک هوش مصنوعی را میپذیرند و بر نتایج تمرکز میکنند («فکر میکردم واقعاً از نوشتن کد لذت میبرم، اما بهجای آن فقط از خروجیهای تولیدی نوشتن کد لذت میبرم»)؛ دیگران میگویند «قطعاً برخی بخشهای نوشتن کد را از دست میدهم.»
- دینامیکهای اجتماعی در محل کار ممکن است در حال تغییر باشند. Claude اکنون اولین نقطهٔ مراجعه برای پرسشهایی است که پیشتر به همکاران میرفت — برخی گزارش میدهند فرصتهای راهنمایی و همکاری کمتر شده است؛ («من دوست دارم با افراد کار کنم و غمانگیز است که الآن کمتر به آنها نیاز دارم… افراد جوانتر کمتر برای من سؤال میآورند.»)
- تحول شغلی و عدم قطعیت. مهندسان گزارش میدهند که به سمت کارهای سطح بالاتر مدیریت سیستمهای هوش مصنوعی حرکت میکنند و بهرهوری قابلتوجهی را تجربه میکنند. اما این تغییرات سؤالاتی دربارهٔ مسیر طولانیمدت مهندسی نرمافزار بهعنوان یک حرفه ایجاد میکند. برخی احساسات متضادی دربارهٔ آینده بیان میکنند: «در کوتاهمدت خوشبین هستم، اما در بلندمدت فکر میکنم هوش مصنوعی همهچیز را انجام خواهد داد و من و بسیاری دیگر را بیارزش میکند.» دیگران بر عدم قطعیت واقعی تأکید میکنند و میگویند فقط «سخت است بگویم» نقشهایشان در آینده چگونه خواهد بود.
روندهای استفاده از Claude Code
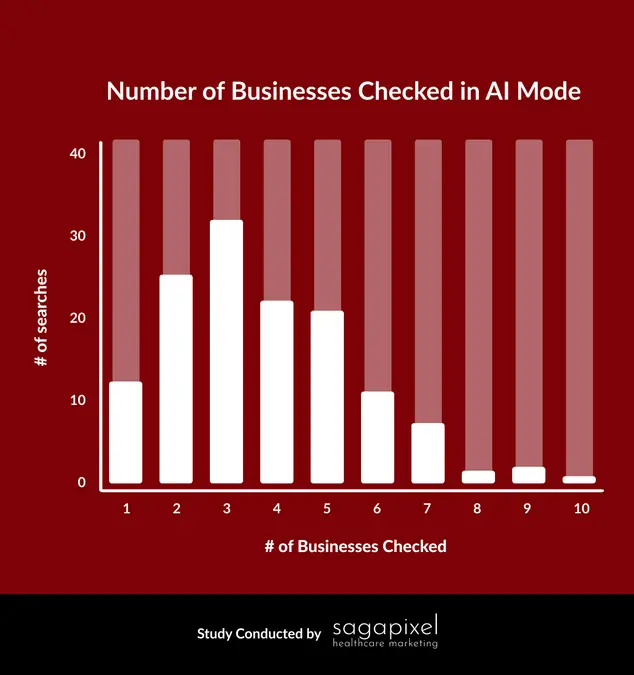
- Claude بهصورت خودکار بهتدریج وظایف پیچیدهتری را بر عهده میگیرد. شش ماه پیش، Claude Code حدود ۱۰ عمل را بهتنهایی انجام میداد پیش از آن که به ورودی انسانی نیاز داشته باشد. اکنون عموماً حدود ۲۰ عمل را بهصورت خودکار انجام میدهد و برای تکمیل جریانهای کاری پیچیدهتر نیاز به هدایت انسانی کمتر دارد (شکل ۳). مهندسان بهطور فزایندهای از Claude برای وظایف پیچیدهای مثل طراحی/برنامهریزی کد (از ۱٪ به ۱۰٪ استفاده) و پیادهسازی ویژگیهای جدید (از ۱۴٪ به ۳۷٪) (شکل ۴) استفاده میکنند.
- Claude بسیاری از «نقاط دردسود» را برطرف میکند. ۸.۶٪ از وظایف Claude Code شامل اصلاح مشکلات جزئی است که کیفیت زندگی کاری را بهبود میبخشد، مانند بازنگری کد برای قابلیت نگهداری (یعنی «برطرف کردن نقاط دردسود») که معمولاً بهطور پیشفرض عقبنشینی میشود. این اصلاحات کوچک میتوانند بهصورت تجمیعی منجر به مزایای بزرگتری در بهرهوری و کارایی شوند.
- همه در حال تبدیل به «فول‑استاک» بیشتر هستند. تیمهای مختلف از Claude بهروشهای متفاوتی استفاده میکنند، معمولاً برای تقویت تخصص اصلی خود — تیم امنیت از آن برای تجزیه و تحلیل کدهای ناآشنا استفاده میکند، تیم همسویی و ایمنی از آن برای ساخت تجسمهای فرانت‑اند دادههای خود بهره میبرد، و غیره (شکل ۵).
دادههای نظرسنجی
ما ۱۳۲ مهندس و پژوهشگر Anthropic را از سراسر سازمان دربارهٔ استفادهٔ آنها از Claude نظرسنجی کردیم تا بهتر بفهمیم دقیقاً چگونه روزانه از آن استفاده میکنند. نظرسنجی را از طریق کانالهای ارتباط داخلی و تماس مستقیم با کارمندان در تیمهای متنوع که نمایندهٔ عملکردهای پژوهش و محصول بودند، توزیع کردیم. بخشی از محدودیتها را در پیوست با جزئیات روششناسی بیشتر گنجاندهایم و سؤالات نظرسنجی را به اشتراک میگذاریم تا دیگران بتوانند رویکرد ما را ارزیابی کرده و برای پژوهش خود سفارشی سازند.
کدام وظایف کدنویسی افراد از Claude استفاده میکنند؟
از مهندسان و پژوهشگرانی که نظرسنجی کردیم خواستیم تا میزان استفادهٔ خود از Claude برای انواع مختلف وظایف کدنویسی را ارزیابی کنند، مانند «اشکالزدایی» (استفاده از Claude برای کمک به رفع خطاهای کد)، «درک کد» (درخواست از Claude برای توضیح کد موجود بهمنظور کمک به کاربر انسانی در درک پایگاه کد)، «بازنگری» (استفاده از Claude برای کمک به بازآرایی کد موجود) و «دادهکاوی» (مثلاً درخواست از Claude برای تجزیه و تحلیل مجموعه دادهها و رسم نمودارهای میلهای).
در ادامه رایجترین وظایف روزانه آورده شده است. بیشترین کارمندان (۵۵٪) Claude را روزانه برای اشکالزدایی استفاده میکردند. ۴۲٪ Claude را هر روز برای درک کد بهکار میبردند و ۳۷٪ Claude را هر روز برای پیادهسازی ویژگیهای جدید بهکار میبستند. وظایف کمتر مکرر شامل طراحی/برنامهریزی سطح بالا (احتمالاً چون اینها وظایفی هستند که مردم تمایل دارند در دست انسان بمانند) و همچنین دادهکاوی و توسعه فرانت‑اند (احتمالاً چون اینها بهطور کلی وظایف کمتر رایجی هستند). این تقریباً با توزیع دادههای استفاده از Claude Code که در بخش «روندهای استفاده از Claude Code» گزارش شده همراستا است.

استفاده و بهرهوری
کارمندان خود گزارش میدهند که ۱۲ ماه پیش در ۲۸٪ کارهای روزانه خود از Claude استفاده میکردند و بهرهوری خود را بهمقدار +۲۰٪ ارتقا میدادند، در حالی که اکنون در ۵۹٪ کارهای خود از Claude بهره میبرند و بهطور متوسط +۵۰٪ افزایش بهرهوری کسب میکنند. (این تقریباً با افزایش ۶۷٪ در درخواستهای ادغام شده (pull‑request) که نشاندهندهی تغییرات موفقیتآمیز به کد است — بهازای هر مهندس در روز — وقتی Claude Code را در کل سازمان مهندسی خود اجرا کردیم، مطابقت دارد.) مقایسهٔ سال‑به‑سال بسیار چشمگیر است — این نشان میدهد که هر دو شاخص بیش از ۲ برابر در یک سال افزایش یافتهاند. استفاده و بهرهوری نیز بهشدت همبستگی دارند و در انتهای توزیع، ۱۴٪ از پاسخدهندگان گزارش میکنند که با استفاده از Claude بهرهوری خود را بیش از ۱۰۰٪ افزایش دادهاند — اینها «کاربران پیشرفته» داخلی ما هستند.
برای هشدار به این یافته (و سایر یافتههای خودگزارش بهرهوری در ادامه)، دقیقاً اندازهگیری بهرهوری دشوار است (برای جزئیات بیشتر به پیوست مراجعه کنید). پژوهش اخیر METR، یک مؤسسه تحقیقاتی غیرانتفاعی در حوزهٔ هوش مصنوعی، نشان داد که توسعهدهندگان باتجربه که با هوش مصنوعی بر روی کدهای آشنای زیاد کار میکنند، بهرهوری خود را بیش از حد برآورد میکنند. با این حال، عواملی که METR بهعنوان عوامل منجر به بهرهوری کمتر از انتظار شناسایی کرده است (مانند عملکرد ضعیف هوش مصنوعی در محیطهای بزرگ و پیچیده، یا جایی که دانش ضمنی/زمینهٔ زیادی لازم است) دقیقاً با وظایفی که کارمندان ما گزارش میدهند «به Claude واگذار نمیکنند» (نگاه به رویکردهای واگذاری هوش مصنوعی، زیر) همراستا است. بهرهوری ما، که بهصورت خودگزارششده در کل کارها است، ممکن است نشاندهندهٔ توسعهٔ مهارتهای استراتژیک واگذاری هوش مصنوعی باشد — چیزی که در مطالعهٔ METR در نظر گرفته نشده است.
الگوی جالب بهرهوری زمانی ظاهر میشود که از کارمندان پرسیده میشود، برای دستههای کاری که در حال حاضر از Claude استفاده میکنند، این ابزار چه تأثیری بر زمان کلی صرفشده و حجم خروجی کار در آن دسته دارد. در تقریباً تمام دستههای کاری، ما کاهش خالص زمان صرفشده را میبینیم و افزایش خالص بزرگتری در حجم خروجی مشاهده میشود:

اما وقتی دادههای خام را عمیقتر بررسی میکنیم، میبینیم که پاسخهای صرفوقت در دو سر مخالف متمرکز میشوند — برخی افراد زمان بیشتری را برای وظایفی که با Claude همراهاند صرف میکنند.
چرا اینگونه است؟ افراد عموماً توضیح میدهند که برای اشکالزدایی و پاکسازی کدهای Claude (مثلاً «وقتی خودم کد را بهیک گوشه میبرم») زمان بیشتری نیاز دارند و بار شناختی بیشتری برای درک کد Claude میپذیرند چون خودشان آن را ننوشتهاند. برخی گفتند زمان بیشتری را برای وظایفی صرف میکنند که بهنوعی توانمندساز هستند — یکی گفت استفاده از Claude به او کمک میکند «بر روی وظایفی که قبلاً فوراً رها میکردم، پافشاری کنم»؛ دیگری گفت این ابزار به او کمک میکند تستهای دقیقتری انجام دهد و همچنین در پایگاههای کد جدید بیشتر یاد بگیرد و کاوش کند. بهنظر میرسد مهندسانی که صرفوقت را تجربه میکنند، وظایفی را انتخاب میکنند که بهسرعت قابلتایید برای Claude باشند، در حالی که کسانی که زمان بیشتری صرف میکنند، ممکن است در حال اشکالزدایی کدهای تولیدشده توسط هوش مصنوعی یا کار در حوزههایی باشند که Claude به راهنمایی بیشتری نیاز دارد.
همچنین واضح نیست که صرفوقت گزارششده به کجا سرمایهگذاری میشود — آیا به وظایف مهندسی اضافه، وظایف غیرمهندسی، تعامل با Claude یا بازبینی خروجیهای آن، یا فعالیتهای خارج از کار اختصاص مییابد. چارچوب طبقهبندی کار ما تمام راههای تخصیص زمان مهندسان را در بر نمیگیرد. علاوه بر این، صرفوقت ممکن است از تعصبات ادراکی در خودگزارشها ناشی شود. پژوهش بیشتر برای تفکیک این اثرها لازم است.
افزایش حجم خروجی واضحتر و چشمگیرتر است؛ افزایش خالص بزرگتری در تمام دستههای کاری مشاهده میشود. این الگو منطقی است وقتی در نظر میگیریم افراد دربارهٔ دستههای کاری (مانند «اشکالزدایی» بهصورت کلی) گزارش میدهند، نه دربارهٔ وظایف منفرد — یعنی افراد میتوانند زمان کمی کمتر را در دستهٔ اشکالزدایی صرف کنند در حالی که خروجی کلی اشکالزدایی را بهمراتب بیشتر تولید میکنند. اندازهگیری مستقیم بهرهوری بسیار دشوار است، اما این دادههای خودگزارش نشان میدهد که هوش مصنوعی در Anthropic عمدتاً از طریق افزایش حجم خروجی بهرهوری را ارتقا میدهد.
Claude، کارهای جدید را امکانپذیر میکند
یکی از سؤالهایی که کنجکاو شدیم: آیا Claude کارهای جدیدی را بهصورت کیفی امکانپذیر میکند، یا کارهای مبتنی بر Claude در نهایت توسط کارمندان انجام میشد (اگرچه شاید با سرعت کمتری)؟
مردم تمایل دارند مدلهای فوققابلیتدار را شبیه یک نمونهٔ واحد ببینند، همانند دریافت یک ماشین سریعتر. اما داشتن یک میلیون اسب … به شما امکان میدهد ایدههای متعددی را آزمایش کنید … این هیجانانگیز و خلاقتر است که دامنهٔ بیشتری برای کشف داشته باشید.
همانطور که در بخشهای بعدی خواهیم دید، این کار جدید اغلب شامل مهندسانی است که بهسراغ وظایفی خارج از تخصص اصلی خود میروند.
چقدر کار میتواند بهطور کامل به Claude واگذار شود؟
اگرچه مهندسان بهطور مکرر از Claude استفاده میکنند، بیش از نیمی گفتند که میتوانند «بهطور کامل» تنها ۰‑۲۰٪ از کارهای خود را به Claude واگذار کنند. (شایان ذکر است که تفسیر «بهطور کامل واگذار» میتواند از وظایفی که بدون هیچگونه تأیید هستند تا وظایفی که فقط به نظارت سبک نیاز دارند، متفاوت باشد.) در توضیح دلایل، مهندسان کار فعال و تکراری با Claude را توصیف کردند و خروجیهای آن را تأیید میکردند — بهویژه برای وظایف پیچیده یا حوزههای حساس که استانداردهای کیفیت کد مهم هستند — در مقابل واگذاری وظایفی که نیازی به تأیید ندارند.
مصاحبههای کیفی
در حالی که این نتایج نظرسنجی نشاندهندهٔ بهرهوری قابلتوجه و تغییر الگوهای کاری است، سؤالاتی دربارهٔ تجربهٔ مهندسان از این تغییرات روزانه بهوجود میآید. برای درک بعد انسانی این معیارها، ما مصاحبههای عمیق را با ۵۳ مهندس و پژوهشگر Anthropic که به نظرسنجی پاسخ دادند، انجام دادیم تا بینش بیشتری دربارهٔ نحوهٔ تفکر و احساس آنها نسبت به این تغییرات در محل کار بهدست آوریم.
رویکردهای واگذاری هوش مصنوعی
مهندسان و پژوهشگران در حال توسعهٔ استراتژیهای مختلفی برای بهرهبرداری مؤثر از Claude در جریان کاری خود هستند. افراد عموماً وظایفی را واگذار میکنند که:
| خارج از زمینهٔ کاربر و پیچیدگی کم: «من Claude را برای چیزهایی استفاده میکنم که زمینهٔ کم دارم، اما فکر میکنم پیچیدگی کلی هم کم است.»
«اکثریت مشکلات زیرساختی که دارم، دشوار نیستند و میتوانند توسط Claude حل شوند… من در Git یا Linux مهارت کافی ندارم… Claude کاری عالی برای جبران کمبود تجربهٔ من در این حوزهها انجام میدهد.» |
| قابل تأیید آسان: «این بهطور مطلق شگفتانگیز است برای همه چیزهایی که تلاش اعتبارسنجی نسبت به ایجاد کمتر است.» |
| بهوضوح تعریفشده یا خودمحدود: «اگر یک زیرمجموعه از پروژه بهطور کافی از بقیه جدا باشد، من Claude را برای امتحان کردن میسپارم.» |
| کیفیت کد اهمیت چندانی ندارد: «اگر کد آزمایشی یا پژوهشی باشد، مستقیم به Claude میسپارم. اگر… |