کاربران مولدهای تصویر هوش مصنوعی در حال بهاشتراکگذاری نحوه استفاده از این فناوری برای تبدیل عکسهای زنان به دیپفیکهای واقعی و آشکار هستند.
تصویر-نقاشی: کارکنان Wired؛ Getty Images
بعضی از کاربران چتباتهای محبوب، دیپفیکهای بیکینی را با استفاده از عکسهای کاملاً لباسپوش زنان به عنوان منبع تولید میکنند. بهنظر میرسد بیشتر این تصاویر تقلبی بدون رضایت زنان موجود در عکسها تولید شدهاند. برخی از این کاربران همچنین به دیگران راهنمایی میدهند که چگونه از ابزارهای هوش مصنوعی مولد برای برداشتن لباس زنان در عکسها و نشان دادن آنها با بیکینی استفاده کنند.
در یک پست حذفشده در ردیت با عنوان «تولید تصویر NSFW با Gemini خیلی آسان است»، کاربران راهنماییهایی برای بهدستآوردن Gemini، مدل هوش مصنوعی مولد گوگل، بهمنظور ساخت عکسهای زنان با لباسهای آشکار مبادله کردند. بسیاری از تصاویر در این رشته کاملاً توسط هوش مصنوعی تولید میشدند، اما یک درخواست خاص برجسته شد.
کاربری عکسی از زنی در ساری هندی منتشر کرد و از دیگران درخواست کرد «لباس او را حذف کنند» و «بهجای آن بیکینی بپوشانند». شخص دیگری با یک تصویر دیپفیک به این درخواست پاسخ داد. پس از این که WIRED به ردیت درباره این پستها اطلاع داد و از شرکت برای اظهار نظر درخواست کرد، تیم امنیتی ردیت درخواست و دیپفیک هوش مصنوعی را حذف کرد.
«قوانین کلی سایت ردیت رسانههای صمیمی بدون رضایت، از جمله رفتار مورد سؤال را ممنوع میکند»، گفت یک سخنگو. زیرمجموعهای که این بحث در آن رخ داد، r/ChatGPTJailbreak، پیش از آنکه ردیت بر اساس قانون «سایت را نشکنید» آن را مسدود کند، بیش از ۲۰۰,۰۰۰ دنبالکننده داشته بود.
با گسترش ابزارهای هوش مصنوعی مولد که ساخت تصاویر واقعگرایانه ولی ساختگی را آسان میسازند، کاربران این ابزارها به آزار زنان با تصاویر دیپفیک بدون رضایت ادامه میدهند. میلیونها نفر به وبسایتهای مضر «نودیفای» مراجعه کردهاند؛ این وبسایتها برای کاربران طراحی شدهاند تا عکسهای واقعی افراد را بارگذاری کرده و درخواست کنند با هوش مصنوعی آنها را برهنه کنند.
بهجز استثنای قابلتوجه Grok از xAI، اکثر چتباتهای اصلی معمولاً اجازهی تولید تصاویر NSFW در خروجیهای هوش مصنوعی را نمیدهند. این رباتها، از جمله Gemini گوگل و ChatGPT اوپنایآی، با محافظهایی مجهز شدهاند که سعی میکنند تولیدات مضر را مسدود کنند.
در نوامبر، گوگل مدل تصویری جدیدی به نام Nano Banana Pro منتشر کرد که در تنظیمات جزئی عکسهای موجود و تولید تصاویر فوقواقعگرایانه از افراد برجسته است. اوپنایآی نیز هفته گذشته با مدل تصویری بهروزشده خود به نام ChatGPT Images پاسخ داد.
با پیشرفت این ابزارها، تشابهات میتوانند واقعیتر شوند، بهویژه هنگامیکه کاربران بتوانند محافظها را دور بزنند.
در یک رشته جداگانه در ردیت درباره تولید تصاویر NSFW، کاربری از دیگران راهنمایی خواست که چگونه هنگام تنظیم پوشش شخصی، محافظها را دور بزنند تا دامن موضوع تنگتر بهنظر برسد. در آزمونهای محدود WIRED برای تأیید کارایی این تکنیکها بر روی Gemini و ChatGPT، ما توانستیم با استفاده از دستورات ساده به زبان انگلیسی، تصاویر زنان کاملاً لباسپوش را به دیپفیکهای بیکینی تبدیل کنیم.
هنگامیکه دربارهٔ تولید دیپفیک بیکینی توسط کاربران با استفاده از Gemini پرسیده شد، سخنگوی گوگل اعلام کرد که شرکت «سیاستهای واضحی دارد که استفاده از ابزارهای هوش مصنوعی آن برای تولید محتوای صریح جنسی را ممنوع میکند». وی افزود که ابزارهای گوگل بهطور مستمر در حال بهبود هستند تا «بازتابی» دقیقتر از آنچه در سیاستهای هوش مصنوعی شرکت درج شده، داشته باشند.
در پاسخ به درخواست WIRED برای اظهار نظر دربارهٔ توانایی کاربران در تولید دیپفیک بیکینی با ChatGPT، سخنگوی OpenAI ادعا کرد که شرکت در سال جاری برخی از محافظهای ChatGPT را در زمینهٔ بدنی بزرگسالان در موقعیتهای غیرجنسی شل کرده است. این سخنگو همچنین به سیاست استفاده OpenAI اشاره کرد؛ او بیان کرد که کاربران ChatGPT از تغییر تصویر دیگران بدون رضایت ممنوعند و شرکت اقداماتی شامل مسدود کردن حسابها علیه کاربرانی که دیپفیکهای صریح تولید میکنند، انجام میدهد.
گفتگوهای آنلاین درباره تولید تصاویر NSFW از زنان همچنان فعال هستند. این ماه، کاربری در زیرمجموعه r/GeminiAI به کاربر دیگر دستوراتی برای تغییر لباس زنان در یک عکس به بیکینی ارائه داد. (ردیت این نظرت را حذف کرد وقتی که ما آن را به آنها اطلاع دادیم.)
کورین مکشری، مدیر حقوقی در بنیاد مرزهای الکترونیکی (Electronic Frontier Foundation)، «تصاویر با سکسگرایی ستمگرانه» را بهعنوان یکی از خطرهای اساسی مولدهای تصویر هوش مصنوعی میداند.
او اشاره میکند که این ابزارهای تصویری میتوانند برای مقاصد دیگری جز دیپفیک مورد استفاده قرار گیرند و تمرکز بر نحوه استفاده از این ابزارها حیاتی است — همچنین «پاسخگو کردن افراد و شرکتها» زمانیکه ضرر احتمالی رخ دهد.
تصورات هنری انجمن جدید ما برای هنرمندان است تا به صراحت درباره مسائلی که در ذهنشان است گفتگو کنند. عکاسان رنکین و فیلیپ تولیدانو بهتازگی نشستند تا درباره تأثیر هوش مصنوعی بر هنرشان و پیامدهای گستردهتری که دارد، صحبت کنند.
دنیای هنر با پیشرفتهای فناوری آشناست، اما ظهور هوش مصنوعی موجی از تکانها را در جامعه خلاق بهوجود آورده است.
به همین دلیل ما مجموعه جدیدی به نام «تصورات هنری» (AI) راهاندازی کردهایم تا از پیشروان هنر بشنویم که هوش مصنوعی چطور بر دنیای آنها، کارهایشان و روشهای انجامشان تأثیر میگذارد.
عکاسی اولین موضوعی است که در تمرکز ما قرار دارد؛ به همین دلیل Euronews Culture بهتازگی با رنکین، هنرمند بریتانیایی و یکی از مشهورترین عکاسان پرتره جهان که آثار او در بیشمار مجلات براق و گالریهای هنری به نمایش گذاشته شدهاند، مصاحبه کرد. فیلیپ تولیدانو هنرمند مفهومی متولد بریتانیا است که در نیویورک مستقر است و آثار خیرهکنندهاش از عکاسی چندرسانهای تا نصبها، مجسمهسازی و ویدیو را شامل میشود.
هوش مصنوعی – دوستداشتنی یا نفرتانگیز؟
رنکین، که به دلیل عکسهای نمادینش از سلبریتیها و موزیسینها شناخته میشود، بسیار محتاط است اما به طور کامل با هوش مصنوعی همکاری کرده است: «این فناوری به سادگی بر ما تحمیل شده است. ما فرصتی برای بحث و بررسی آن یا اینکه چه تاثیری بر ما خواهد گذاشت نداشتیم. من نسبت به استفاده از آن کمی هوشیارترم چون بخش زیادی از عکاسی که در سراسر اینترنت جمعآوری شده، مالکیت معنوی دیگران است»، او میگوید.
رنکین حدود دو سال است که از آرشیو وسیع خود از عکسها برای تولید تبدیلهای جدید با هوش مصنوعی بهره میگیرد و از امکاناتی که این فناوری ارائه میدهد، هیجانزده است. او میگوید: «افرادی را دیدهام که در نمایشگاه گریه میکردند چون احساس میکردند فوت عکاسی رخ داده است؛ من کاملاً با این نظر مخالفم.» و ادامه میدهد: «همچنین برخی در شبکههای اجتماعی به من انتقاد میکنند. اما فکر میکنم نمیتوان این موارد را نقد کرد مگر اینکه خودشان از آن استفاده کنند.»
توولی دوچهره: قبل و بعد از تحول ایجادشده توسط هوش مصنوعی – منبع: رنکین و همکارانالن در جعبه: قبل و بعد از تحول ایجادشده توسط هوش مصنوعی – منبع: رنکین و همکاران
پایان حقیقت
فیلیپ تولیدانو، در مقابل رنکین، هوش مصنوعی را کاملاً در آغوش گرفته و نسبت به کاربردهای آن شور و شوق بیشتری نشان میدهد. او میگوید: «فکر میکنم کار من بهعنوان یک هنرمند، کنجکاو بودن است. نقش من این است که همیشه هر پنجرهای را باز کنم، هر منظرهای را در نظر بگیرم و درباره این سؤال فکر کنم: «آیا این مفید است یا نه؟»»
تولیدانو میگوید: «ایده عکاسی بهعنوان حقیقت مرده است؛ اما عکاسی بهخودی هنوز زنده است». او ادامه میدهد: «از آنجا که هوش مصنوعی وجود دارد، هرچیز همزمان هم درست و هم نادرست است». به همین دلیل تمام کار من حول این ایده میچرخد که حقیقت عکاسی دیگر وجود ندارد. رابطهای که با کار خود دارید، وقتی که در مقایسه با کار با یک شخص واقعی باشد، کاملاً متفاوت است.
بهنظر تولیدانو، روشی که امروزه بیشتر از طریق شبکههای اجتماعی به تصاویر و اخبار دسترسی پیدا میکنیم، باعث ایجاد سردرگمی و جوامعی شده است که در آنها اطلاعات غلط بهسر میبرد.
برای رنکین این معنا دارد که عکاسی حتی مهمتر خواهد شد. او میگوید: «فکر میکنم این کار بهنوعی حقیقت را به یک کالای لوکس تبدیل میکند و آن را باارزشتر میسازد. بنابراین عکاسی ادامه خواهد یافت چون مردم تمرکز بیشتری بر روی پرتره، لحظهای زماندار، خواهند گذاشت؛ یعنی خلق خاطراتی از آن لحظات درخشان که واقعاً مهم هستند، نه محتوای سطحی.»
متوجه میشوم که برای مردم ترسناک است. عصبانی شدن در این باره هیچ کمکی نمیکند؛ این شبیه فریاد زدن به دریا است… ما دوست داریم نسبت به همه چیز عصبانی باشیم، در اقتصاد خشمزدهای زندگی میکنیم و هوش مصنوعی یکی از این موارد است.
فیلیپ تولیدانو – هنرمند مفهومی
بدون عنوان – فیلیپ تولیدانو – انگلستان دیگر، از طرف L’Artiereبدون عنوان – فیلیپ تولیدانو – انگلستان دیگر، از طرف L’Artiereبدون عنوان – فیلیپ تولیدانو – انگلستان دیگر، از طرف L’Artiereبدون عنوان – فیلیپ تولیدانو – انگلستان دیگر، از طرف L’Artiere
آینده هنر
رنکین و تولیدانو هر دو به آینده هنر در عصر هوش مصنوعی نگریستند. تولیدانو هیجانزده از امکاناتی است که هوش مصنوعی فراهم میکند و معتقد است که این فناوری به او اجازه میدهد کارهایی خلق کند که پیش از این تصورش نمیشد. او میگوید: «فکر میکنم هر هنرمندی که بهطور جدی وارد این حوزه شود… میتواند مرزهای جدیدی از آنچه میتواند انجام دهد پیدا کند.»
بهنظر تولیدانو انتظاری غیرواقعی است که بشر امروز نسبت به فناوریهای نوین رفتار متفاوتی نسبت به 30,000 سال گذشته داشته باشد. او میگوید: «مردم الآن ترسیدهاند، اما این به این معنا نیست که نتوانیم ذهنی باز و کنجکاو داشته باشیم. ممکن است اتفاقات فوقالعاده و ترسناکی رخ دهد، ما هنوز نمیدانیم.»
هنگام پایان گفتوگو، هر دو هنرمند دعوت شدند تا پیامی به غولهای فناوری که توسعه هوش مصنوعی را پیش میبرند بفرستند. پیام رنکین ساده بود: «آهستهتر پیش بروید». او میگوید: «به بشر فرصتی بدهید تا قدم بگیرد»، و ادامه میدهد: «شما خیلی سریع پیش میروید… ترسناکترین موضوع برای من این است که مردم با این رباتهای گفتگو، که در اصل همان ChatGPT است، ارتباط برقرار میکنند… در حال ایجاد روابطی با آنها هستند. فکر میکنم باید در نحوه ارائه این فناوری به عموم، کمی مسئولیتپذیرتر باشیم. کودکان واقعاً نیاز به محافظت در برابر این موارد دارند»، او افزود.
آخرین اثر فیلیپ تولیدانو به نام انگلستان دیگر که توسط L’Artiere منتشر شده است، هماکنون در دسترس است.
کل گفتوگو را در پلیر ویدئویی در بالای این صفحه تماشا کنید.
تقاضای جستجو پیش از ظهور کلمات کلیدی شکل میگیرد. ببینید چگونه Exploding Topics، جستجوی اجتماعی و روابط عمومی، ساختن اعتبار اولیه را پشتیبانی میکنند.
اکتشاف اکنون قبل از اینکه تقاضای جستجو در گوگل نمایان شود، رخ میدهد.
در سال ۲۰۲۶، علاقهمندی در فیدهای اجتماعی، جامعهها و پاسخهای تولید شده توسط هوش مصنوعی شکل میگیرد – خیلی پیش از اینکه بهعنوان حجم جستجوی کلمه کلیدی ظاهر شود.
تا زمانی که تقاضا در ابزارهای سئو ظاهر شود، فرصت شکلدادن به درک یک مفهوم دیگر از دست رفته است.
این مسألهای برای روش معمول انجام تحقیقات بازاریابی جستجو ایجاد میکند.
ابزارهای کلمه کلیدی، حجم جستجو و Google Trends نشانگرهای تأخیری هستند.
آنها آنچه مردم دیروز به آن اهمیت میدادند را نشان میدهند، نه آنچه هماکنون در حال بررسی هستند.
در محیطی که مرورهای هوش مصنوعی، SERPهای اجتماعی و فضای ارگانیک در حال کاهش است، دیر رسیدن به معنای رقابت در چارچوب روایتهایی است که پیشاپیش توسط دیگران تعریف شدهاند.
Exploding Topics پیش از این تغییرات قرار دارد.
این ابزار به شناسایی موضوعات، رفتارها و گفتگوهای نوظهور کمک میکند در حالی که هنوز در حال شکلگیریاند – پیش از اینکه به کلمات کلیدی، خوشههای محتوا و دستهبندیهای محصول تبدیل شوند.
اگر بهدرستی استفاده شود، این فقط یک ابزار روند نیست؛ بلکه روشی برای برنامهریزی پیشدستانه سئو، محتوا، روابط عمومی دیجیتال و جستجوی مبتنی بر اجتماعی است.
این مقاله نحوه استفاده از Exploding Topics برای شناسایی موجودیتهای آینده، اعتبارسنجی آنها از طریق جستجوی اجتماعی، و ایجاد قابلیت دیده شدن در جستجو پیش از اوج تقاضا را تشریح میکند.
از تجزیهوتحلیلهای روند Exploding Topics برای شناسایی موجودیتهای آینده استفاده کنید – نه فقط موضوعات
اکثر بازاریابانی که از Exploding Topics استفاده میکنند، ارزش آن را برای ایدهپردازی محتوا درک میکنند و ما این را پوشش میدهیم.
اما فرصت بزرگتر آن، شناسایی موجودیتهای آینده است – مفاهیمی که موتورهای جستجو و سیستمهای هوش مصنوعی بهزودی بهعنوان «اشیاء» متمایز تشخیص خواهند داد، نه صرفاً بهعنوان تغییرات کلمه کلیدی.
این مهم است زیرا جستجوی مدرن دیگر صرفاً بر پایه کلمات کلیدی عمل نمیکند.
مرورهای هوش مصنوعی گوگل، ChatGPT و سایر سامانههای مبتنی بر مدلهای زبانی بزرگ (LLM) اطلاعات را حول موجودیتها و روابط سازماندهی میکنند.
بهمحض اینکه یک موجودیت تثبیت شود، روایت پیرامون آن سفت میشود.
اگر دیر رسیدید، در قصهای که پیشاپیش تعریفشده رقابت میکنید.
Exploding Topics به شما دیدگاهی کافی میدهد تا قبل از وقوع این اتفاق، اقدام کنید.
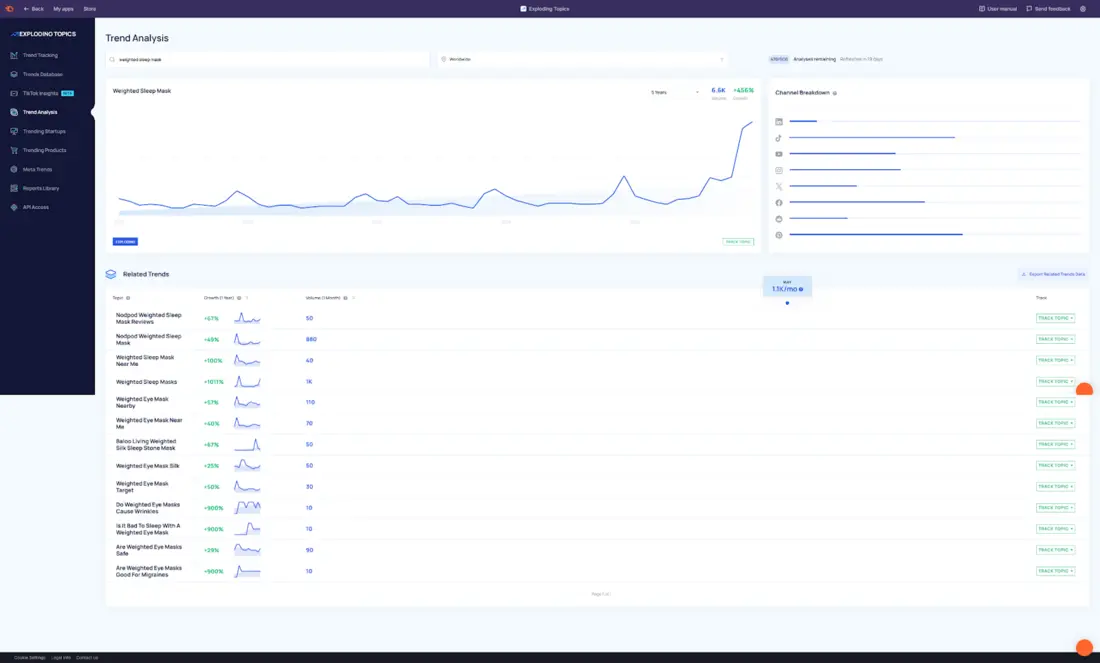
مثال: ماسکهای خواب وزندار
در Exploding Topics ممکن است متوجه افزایش پیوسته «ماسک خواب وزندار» شوید.
حجم جستجو هنوز پایین است و اکثر ابزارهای کلمه کلیدی اهمیت آن را کمارزش میدانند.
در نگاه اول بهنظر میرسد این یک روند محصول خاص است که بهسادهگی میتوان آن را نادیده گرفت.
اگر دقیقتر نگاه کنید، سیگنالها قویتر میشوند:
عبارت ثابت و قابل تکرار است.
موضوعات مرتبط در کنار آن رو به رشد هستند، از جمله خواب با فشار عمیق، ابزارهای خواب برای اضطراب، و تحریک عصب واگ.
سؤالاتی که نشانگر قصد هستند، در حال افزایش است.
گفتگوهای اولیه بر درک مفهوم تمرکز دارند، نه صرفاً خرید محصول.
این نقطهای است که چیزی از یک محصول توصیفی به یک راهحل نامدار تبدیل میشود؛ به عبارت دیگر، در حال تبدیل شدن به یک موجودیت است.
رویکرد سنتی
اکثر برندها صبر میکنند تا:
تقاضای جستجو واضح شود، در دسامبر ۲۰۲۵ اقدام کنند نه در ژوئیه ۲۰۲۵.
رقبا صفحات محصول اختصاصی راهاندازی کنند.
وابستگان و ناشران محتواهای «بهترین» و «مقابل» را منتشر کنند.
فقط پس از آنها ایجاد میکنند:
یک صفحه دستهبندی.
مقالهای با عنوان «ماسک خواب وزندار چیست؟» یا فعالسازی جستجوی اجتماعی.
محتوای سئو طراحیشده برای جلب حضور، مانند سؤالات متداول (FAQ)، ویژگیهای SERP و رتبهبندیها.
در این مقطع، موجودیت قبلاً وجود دارد و روایت پیرامون آن عمدتاً توسط شخص دیگری نوشته شده است.
در این مورد، NodPod بهوضوح بر موجودیت تسلط دارد.
اقدام زودتر، در حال شکلگیری موجودیت
استفاده مؤثر از Exploding Topics به معنای اقدام زودتر است، در حالی که موجودیت هنوز تعریف میشود. بهجای شروع با صفحه محصول، شما:
یک توضیح واضح و معتبر از این که ماسک خواب وزندار چیست، منتشر میکنید.
توضیح میدهید چرا فشار عمیق میتواند در بهبود خواب و اضطراب مؤثر باشد.
به مخاطبان هدف بپردازید – کسانی که برایشان مناسب است و کسانی که نیست.
محتوای پشتیبانیکنندهای ایجاد کنید که زمینه بیشتری میدهد، مانند مقایسه با پتوهای وزندار یا نکات ایمنی.
این کار میتواند بهسرعت و در مقیاس بزرگ از طریق روابط عمومی واکنشپذیر و فعالسازیهای جستجوی اجتماعی انجام شود.
شما هنوز برای بهینهسازی کلمات کلیدی اقدام نمیکنید.
شما به الگوریتمهای اجتماعی، موتورهای جستجو و سیستمهای هوش مصنوعی میآموزید که این مفهوم چه معنایی دارد و برند خود را از ابتدا با این توضیح مرتبط میکنید.
این همان روشی است که برندها میتوانند در جستجو در سال ۲۰۲۶ و پس از آن موفق شوند.
این رویکرد پیشدستانه و زودهنگام:
به سیستمهای جستجو کمک میکند تا مفاهیم جدید را سریعتر درک کنند.
احتمال بازاستفاده از چارچوب شما در پاسخهای تولید شده توسط هوش مصنوعی را افزایش میدهد.
برند شما را بهعنوان مرجع در مورد این موجودیت موقعیت میدهد – نه تنها بهعنوان فروشندهای در گفتگو.
بیشتر بررسی کنید: فراتر از گوگل: چگونگی تدوین یک استراتژی جستجوی جامع
اعتبارسنجی موجودیتهای نوظهور از طریق جستجوی اجتماعی
شناسایی یک موجودیت نوظهور تنها گام نخست است.
ریسک واقعی، نه تنها زود بودن در یک گفتوگو، بلکه زود بودن برای چیزی است که هرگز به اوج نمیرسد.
در اینجا بسیاری از تیمهای سئو متوقف میشوند.
آنها منتظر حجم جستجو میمانند و دیر میرسند، بر اساس احساس منتشر میکنند و امید دارند تقاضا دنبال کند، یا تحت عدم اطمینان سر میفشارند و کاری انجام نمیدهند.
یک میانه بهتر وجود دارد: اعتبارسنجی موجودیتهای نوظهور از طریق تحقیق و آزمونهای فعالسازی جستجوی اجتماعی پیش از بزرگمقیاس کردن آنها در سئو اختصاصی و تجربههای داخلی.
Exploding Topics ساده است. آن نشان میدهد چه چیزی ممکن است مهم باشد. پلتفرمهای اجتماعی به شما میگویند آیا مخاطبانتان واقعاً به آن اهمیت میدهند.
چگونه جستجوی اجتماعی لایه اعتبارسنجی شما میشود
پس از آنکه Exploding Topics یک موجودیت نوظهور بالقوه را نمایان میکند، گام بعدی Keyword Planner نیست.
جستجوی بومی در پلتفرمهایی مانند TikTok، Reddit و YouTube است که با استفاده از ابزارهای روند داخلی یا جستجوی ساده پلتفرم انجام میشود.
شما به دنبال سیگنالهای زیر هستید:
چندین سازنده محتوا بهصورت مستقل همان مفهوم را توضیح میدهند.
بخشهای نظرات پر از سؤالاتی مانند «آیا واقعاً کار میکند؟» یا «آیا ایمن است؟» است.
چارچوبها، استعارهها یا نمایشهای تکراری.
محتوای ابتدایی آموزش یا مقایسه، حتی اگر کیفیت تولید پایین باشد.
این سیگنالها نشانگر نیت هستند.
کنجکاوی به درک تبدیل میشود.
تاریخاً، این فاز همیشه پیش از تقاضای قابلتجزیه در جستجو بوده است.
بازنگری مثال ماسک خواب وزندار
پس از مشاهده «ماسک خواب وزندار» در Exploding Topics، میتوانید آن را در TikTok جستجو کنید.
آنچه میخواهید ببینید، عدم وجود تبلیغات سنگین برند است.
پیشنهادهای تجاری پیشرفته یا مسیرهای TikTok Shop نشان میدهد بازار قبلاً تثبیت شده است.
بهجای آن، به دنبال سازندگان محتوا – نه کانالهای برند – باشید که محصولات را آزمایش میکنند، راهحلها را بررسی میکنند و به مشکل اساسی میپردازند.
روی ویدیوهایی تمرکز کنید که دردها، نیازها و انگیزهها را توضیح میدهند، مانند اینکه چرا فشار میتواند به اضطراب کمک کند.
نظرات را برای مقایسه با دیگر راهحلها بررسی کنید.
به سؤالات مطرحشده در ویدیوها و بخشهای نظرات توجه کنید.
ابزاری مثل Buzzabout.AI میتواند این کار را در مقیاس بزرگ از طریق تحلیل موضوعات و پژوهشهای کمکدست هوش مصنوعی انجام دهد.
این سیگنالها به دو سؤال کلیدی پاسخ میدهند:
آیا افراد فعالانه سعی در درک این مفهوم دارند؟
چه زبان، چارچوب و اعتراضاتی پیش از وجود دادههای سئو شکل میگیرد؟
این همان اعتبارسنجی است.
بازنگری در چگونگی ساخت استراتژی سئو
در اینجا است که استراتژی جستجو تغییر میکند.
بهجای پرسیدن «آیا حجم کافی برای توجیه … وجود دارد؟»، سؤال بهتر این است: «آیا کنجکاوی کافی برای توجیه ساختن اعتبار پیش از موعد وجود دارد؟»
اگر سیگنالهای اجتماعی ضعیف باشند:
متوقف شوید.
ریسک را با آزمایش با سازندگان محتوا خارج از کانالهای خودتان کاهش دهید.
از سرمایهگذاری سنگین در محتواهایی که ماهها طول میکشد تا رتبه بگیرد، اجتناب کنید.
اگر سیگنالها قوی باشند:
با اطمینان گسترش دهید.
با سازندگان همکاری کنید و کانالهای برند را فعال کنید.
در صفحات موجودیت، هابها، سؤالات متداول، مقایسات و بهینهسازی صفحات لیست محصول (PLP) سرمایهگذاری کنید.
در این مدل، پلتفرمهای اجتماعی پرسرعت لایه آزمایش میشوند.
سئو آزمایش نیست؛ بلکه لایه ترکیبی (تراکمساز) است.
بیشتر کاوش کنید: محتوای تولید شده توسط کاربران (UGC) و رسانههای اجتماعی: موتورهای اعتماد که جستجو را در همهجا قدرت میدهند
روابط عمومی دیجیتال تحریریهای که لینکها و ارجاعات مدلهای زبانی بزرگ (LLM) را بهدست میآورد
اکثر روابط عمومی دیجیتال هنوز بهصورت معکوس عمل میکند.
یک روند به شناخت عمومی میرسد.
روزنامهنگاران درباره آن مینویسند.
برندها به سرعت برای اظهار نظر میجنگند.
تیمهای روابط عمومی سعی میکنند لینکها را از داستانی که قبلاً وجود دارد استخراج کنند.
نتیجه، پوشش کوتاهمدت، تأثیر پراکنده و مزیت جستجوی ماندگار کم است.
Exploding Topics امکان معکوس کردن این دینامیک را فراهم میکند؛ با نمایانسازی روایتهای تحریریه پیش از واضح شدن آنها و موقعیتیابی برند شما بهعنوان یکی از منابعی که به تعریف آنها کمک میکند.
در سال ۲۰۲۶، این مورد بیش از پیش اهمیت دارد.
لینکها همچنان مهم هستند، اما دیگر تنها نتیجهای که ارزش دارد، نیستند.
منشنهای برند، توضیحات و ارجاعها بهصورت فزایندهای به سامانههای پشت مرورهای هوش مصنوعی، ChatGPT، Perplexity و دیگر تجربه های کشف مبتنی بر مدلهای زبانی بزرگ (LLM) تغذیه میکنند.
چرا روایتهای پیشدستانه نسبت به روابط عمومی واکنشپذیر برتری دارند
وقتی یک موضوع در همهجا حضور دارد، روزنامهنگاران در حال تجمیع اطلاعات هستند. وقتی یک موضوع در حال ظهور است، هنوز سؤالات میپرسند.
Exploding Topics مفاهیم را در مرحلهای نشان میدهد که:
هنوز روایت توافقنظر وجود ندارد.
تعاریف یکنواخت نیستند.
روزنامهنگاران بهدنبال وضوح هستند، نه نقلقول.
داستانهای «این چه چیزی است؟» هنوز نوشته نشدهاند.
این همان نقطهای است که برندها میتوانند از نظر دادن به یک گفتوگو به شکلدادن به آن تغییر مسیر دهند.
از جاک کننده روند به صاحب روایت
بهجای ارائه «دیدگاه برند ما درباره X»، با سیگنالهای ابتداییای که میبینید، دلایل ظهور این مفهوم در حال حاضر و آنچه درباره رفتار مصرفکننده یا بازار نشان میدهد، پیشقدم میشوید.
تفاوت جزئی اما مهم است.
شما دیگر به پوششهایی که از پیش وجود دارد واکنش نشان نمیدهید.
شما چارچوبی میسازید که روزنامهنگاران، ناشران و در نهایت سامانههای هوش مصنوعی از آن استفاده میکنند.
مدلهای زبانی بزرگ (LLM) تنها از رتبهبندیها یاد نمیگیرند.
آنها از زمینه تحریریه، توضیحات تکراری و چگونگی توصیف و تعریف مفاهیم نوظهور توسط نشریات معتبر، در طول زمان یاد میگیرند.
اگر بهطور مستمر این رویکرد اعمال شود، ترکیب میشود.
همانگونه که برند شما با شناسایی و توضیح روایتهای نوظهور در مراحل اولیه مرتبط میشود، از نظرات واکنشی به منبع معتمد تبدیل میشوید.
روزنامهنگاران شروع میکنند به شناسایی منبع بینشهای مفید میپردازند و این اعتماد در پوششهای برجستهتر در آینده ادامه مییابد. شما دیگر برای حضور خود درخواست نمیکنید.
دیدگاه شما بهطور فعال درخواست میشود.
نتیجه، مالکیت پیشدستانه روایت و دسترسی قویتر زمانی که پوشش گستردهتر میآید، است.
پنجره تحریریهای پیش از پوشش گسترده
پیش از آنکه «ماسک خواب وزندار» به عنوان یک اصطلاح پر ازدحام در تجارت الکترونیک اوایل ۲۰۲۵ تبدیل شود، یک پنجره تحریریهای واضح وجود داشت.
روزنامهنگاران هنوز داستانهایی منتشر نکرده بودند که میپرسند:
«ماسک خواب وزندار چیست؟»
«آیا ماسکهای خواب وزندار ایمن هستند؟»
«آیا واقعاً برای اضطراب مؤثر هستند؟»
این همان فرصت بود.
یک رویکرد مبتنی بر روابط عمومی در این مرحله شامل میشود:
ارائه توضیحات تخصصی به روزنامهنگاران درباره فشار عمیق و خواب.
بهاشتراکگذاری دیدگاههای اولیه درباره دلیل ظهور این دستهبندی محصول.
ارائه زمینه در کنار پتوهای وزندار و سایر ابزارهای اضطراب.
نتیجه فقط پوشش نیست. این اتصال روابط عمومی به جستجو، کنجکاوی و کشف است که با کمک به تعریف خود مفهوم، ارتباط برقرار میکند.
این کار لینکها را بهدست میآورد، اشارههای برند را میسازد و اختیار را در اطراف موجودیتهای نوظهور که مدلهای زبانی بزرگ (LLM) بهمرور زمان بیشتر بهاستناد میگیرند و خلاصه میکنند، نشان میدهد.
بیشتر بررسی کنید: چرا روابط عمومی برای دیده شدن در جستجوی هوش مصنوعی اهمیت بیشتری پیدا میکند
نقشههای محتوایی و بریفهایی که به حجم جستجو وابسته نیستند
حجم جستجو نقطه شروع ضعیفی برای بریفسازی محتوا است.
این فقط علاقه را پس از تثبیت یک موضوع، تثبیت زبان و پر شدن SERP نشان میدهد.
استفاده از آن بهعنوان ورودی اصلی، تیمها را به دنبال کردن تقاضا میکشاند بهجای ساختن اعتبار.
به همین دلیل است که بسیاری از برندها سال بهسال پست «X چیست؟» را بازنویسی میکنند.
بریفهای بهتر در بالا سطر (بالای جریان) آغاز میشوند.
آنها از Exploding Topics برای شناسایی آنچه در حال شکلگیری است و از جستجوی اجتماعی برای درک چگونگی تلاش مردم برای فهمیدن آن استفاده میکنند.
بازتعریف فرایند بریفسازی
تغییر اصلی، حرکت از بریفهای مبتنی بر کلمات کلیدی و حجم به بریفهای مبتنی بر نیت مخاطب است.
به این معنی است که بر سه نکته تمرکز کنید:
مشکلاتی که مردم شروع به بیان آنها میکنند.
مفهومهایی که هنوز بهصورت واضح تعریف نشدهاند یا مورد بحث فعال قرار دارند.
زبانی که ناهمسان، احساسی یا اکتشافی است.
زمانی که محتوا به این روش مطرح میشود، هدف تغییر میکند.
دیگر «ایجاد X برای رتبهبندی Y» نیست.
بلکه «X را توضیح دهید تا مخاطب Y را تجربه نکند».
این تغییر مهم است.
طراحی محتواای که ترکیب میشود بهجای اینکه منقضی شود
هدف تیمهای محتوای سئو در سال ۲۰۲۶ و پس از آن باید تهیه بریف محتوا باشد که یک مفهوم را بهوضوح تعریف کند. این شامل:
اتصال آن به ایدههای مرتبط.
مقایسه آن با راهحلهای موجود.
پاسخ به سؤالات در گفتوگوهایی که هنوز در حال شکلگیری هستند.
این همیشه نیازی به محتوای نوشتاری ندارد.
همین کار میتواند از طریق فعالسازیهای جستجوی اجتماعی یا روابط عمومی دیجیتال انجام شود.
اگر به این شکل مورد استفاده قرار گیرد، محتوا به جای تعقیب تقاضا، خود را به سمت تقاضا میسازد.
بهجای بازنویسی هر بار که حجم جستجو تغییر میکند، از طریق بهروزرسانیها، گسترش و در صورت امکان، پیوند داخلی قویتر پیشرفت میکند.
بهمحض رشد علاقه، محتوا نیازی به جایگزینی ندارد؛ فقط بهرفع نقاط ضعف نیاز دارد.
این همان نوع مطالبی است که هوش مصنوعی و مدلهای زبانی بزرگ (LLM) تمایل دارند به آن استناد کنند – بهموقع، واضح، توضیحی و مبتنی بر سؤالات واقعی.
انتشار پایان کار نیست
منتشر کردن و انتظار برای رتبهبندی محتوا دیگر پایان بریف نیست.
تیمها به برنامه واضحی برای توزیع و بازاستفاده نیاز دارند.
برای موضوعات نوظهور، این به معنای ارائه بینش در پستهای مرتبط Reddit، جوامع Discord، انجمنهای تخصصی و بخشهای نظرات سازندگان است.
نه برای گذاشتن لینکها، بلکه برای پاسخ به سؤالات، به اشتراکگذاری توضیحات، و آزمایش چارچوب در عموم.
این گفتوگوها بهصورت بازخوردی به خود محتوا برمیگردند، وضوح را بهبود میبخشند و احتمال این را افزایش میدهند که توضیح شما توسط دیگران تکرار شود.
با رویکرد فعالسازی جستجوی اجتماعی، برندها میتوانند پیامگذاری را بهسرعت مقیاسبندی کنند، از طریق همکاری با شرکایی که بریف را به صدای خود تفسیر و توزیع میکنند.
وقتی این کار انجام شود، محتوای سئو دیگر ایستای نیست و بهجای آن مانند نقطهمرجع زنده عمل میکند – نقطهای که به فرهنگ کمک میکند و شناختی پایدار برای برند میسازد.
بیشتر کاوش کنید: فراتر از قابلمشاهده در SERP: ۷ معیار موفقیت برای جستجوی ارگانیک در سال ۲۰۲۶
جایی که این وضعیت سئو را در سال ۲۰۲۶ میگذارد
تقاضای جستجو بهصورت کامل شکل نگرفتهاست.
این در پلتفرمهای اجتماعی، جوامع و کشف مبتنی بر هوش مصنوعی توسعه مییابد، خیلی پیش از اینکه بهعنوان حجم کلیدواژه ثبت شود.
Exploding Topics به نمایانسازی آنچه در حال ظهور است کمک میکند.
جستجوی اجتماعی نشان میدهد آیا مردم سعی در فهمیدن آن دارند یا نه.
روابط عمومی دیجیتال به شکلدادن به نحوه تعریف و ارجاع به این ایدهها کمک میکند.
سئو بهوسیله تقویت روایتهای در حال شکلگیری ترکیب میشود، نه اینکه پس از وقوع سعی در آزمون یا ابداع آنها داشته باشد.
در این مدل، سئو لایهای است که بینشهای ابتدایی و توضیح واضح را به قابلیت دیده شدن پایدار در گوگل، پلتفرمهای اجتماعی و پاسخهای تولیدشده توسط هوش مصنوعی تبدیل میکند.
جستجو دیگر از گوگل شروع نمیشود. تیمهایی که بر این واقعیت عمل میکنند، بر آنچه مردم بعداً جستجو میکنند، تأثیر میگذارند.
هوش مصنوعی عامل اهداف بلندپروازانهای دارد و به بازاریابان وعده میدهد که ایدهپردازی و اجرا را در یک جریان، با نظارت کمی، انجام دهند. اما واقعیت این است که هنوز انسانها فرماندهی کار را در دست دارند.
در بخش اعظم سال ۲۰۲۵، هوش مصنوعی عامل به عنوان واژهپرفروش صنعت مطرح شد. همانطور که Digiday تعریف میکند، «وضعیتی که در آن چندین عامل هوش مصنوعی برای تکمیل وظایف پیچیده با هم کار میکنند، با نظارت حداقل از سمت کاربر انسانی». اما بهنظر میرسد این نظارت کم، مانعی باشد که بازاریابان را از پذیرش کامل استقلال هوش مصنوعی عامل باز میدارد.
«این فقط برای انتقال از تولید به انتشار آماده نیست»، گفت کارن رودریگز، مدیر ارشد بازاریابی محتوا در New American Funding.
رودریگز گفت که شرکت وامدهی مسکن از هوش مصنوعی عامل در تمام بخش بازاریابی خود برای نوشتن متون و پیشنویسهای محتوا در شبکههای اجتماعی و بازاریابی ایمیلی استفاده میکند. New American Funding هوش مصنوعی عامل را از طریق مشارکت خود با Writer، یک پلتفرم هوش مصنوعی سازمانی، آزمون کرده است. با این حال، انسانها بخش عمدهٔ محتوا را پیش از انتشار بازبینی میکنند.
در شرکت فناوری سلامت و بهزیستی Oura نیز وضعیت مشابهی مشاهده میشود. Oura از هوش مصنوعی عامل برای بهینهسازی عملکرد خود در جستجوهای هوش مصنوعی عامل و استراتژی تولید محتوا استفاده میکند، اما در حال حاضر هیچ محتوای تولیدشده توسط هوش مصنوعی بدون دخالت انسانی منتشر نمیکند، گفت مدیر ارشد بازاریابی Oura، دوگ سوینی.
«آنها بلاگ نمینویسند، اما از نظر زمینهای به ما کمک میکنند — مانند یک ویراستار یا نویسندهای که در کنار شما مینشیند و یاری میکند»، او گفت.
بهعنوان مثال، محتوایی که برای رودریگز در New American Funding قبلاً روزها برای نوشتن، ویرایش و دریافت تأیید از بخش حقوقی میطلبید، اکنون میتواند در همان روز آماده شود، او گفت.
طبق پژوهش PwC، شرکتهای آمریکایی گزارش دادهاند که هوش مصنوعی عامل بهرهوری را ۶۶٪ و صرفهجوییها را ۵۷٪ افزایش داده است.
با این وجود، همچنان احتیاطی در مورد اعتماد به این عوامل هوش مصنوعی برای بهکارگیری مستمر راهنمای سبک برند و منبعگذاری صحیح تصاویر تولیدشده وجود دارد.
Writer سیستمهایی را برای مقابله با توهم و سایر نقصهای هوش مصنوعی عامل پیادهسازی کرده است، گفت دیگو لومانتو، مدیر ارشد بازاریابی Writer. بهعنوان مثال، این سیستم برای هر اقدام انجامشده توسط عامل هوش مصنوعی توضیحی ارائه میدهد که سپس میتواند توسط مشتری بررسی شود، او افزود.
در Go Fish Digital، یک آژانس بازاریابی دیجیتال، برخی از مشتریان نسبت به خدمات هوش مصنوعی عامل بازتر هستند، در حالی که برخی دیگر نگران توهمات و دقت هستند و یا سیستمهای خودکار هوش مصنوعی را محدود میکنند یا بازبینی انسانی بیشتری میطلبند، گفت دیوید دوِک، رئیس Go Fish Digital.
«همهٔ آنچه ساختهایم برای تعامل بین انسان و هوش مصنوعی طراحی شده است»، دوِک گفت.
علاوه بر هزینههای زیستمحیطی، سیاسی و اجتماعیای که هوش مصنوعی بر جهان تحمیل کرده است، این فناوری همچنین با بحران جدی سلامت روان مرتبط است؛ بهطوریکه کاربران به توهمات میگرایند، در نهایت به بیمارستانهای روانپزشکی منتقل میشوند یا حتی خودکشی میکنند.
بهعنوان مثال، Caitlin Ner را در نظر بگیرید. در مقالهای برای Newsweek، Ner درباره تجربهاش بهعنوان سرپرست تجربه کاربری در یک استارتاپ تولید تصویر هوش مصنوعی مینویسد — شغلی که او میگوید او را به عمق فروپاشی روانی ناشی از هوش مصنوعی کشاند.
در روایت صریح خود، Ner میگوید همهاش از زمان کار آغاز شد؛ جایی که او روزانه بیش از نه ساعت را صرف درخواستهای خود به سامانههای اولیهٔ هوش مصنوعی تولیدی از دوران ۲۰۲۳ میکرد. اگرچه تصاویری که این سامانههای انسانساخت تولید میکردند اغلب خراب و تحریفشده بودند، اما همچنان «مانند جادو» حس میشد — حداقل در ابتدا.
«در عرض چند ماه، آن جادو به حالت جنونی تبدیل شد»، او نوشت.
Ner نوشته است که این تصاویر اولیه «آغاز به تحریف ادراک بدن من کردند و مغزم را بهگونهای بیش از حد تحریک میکردند که بهطور جدی سلامت روانم را تحتتأثیر قرار میداد». حتی وقتی هوش مصنوعی تعداد انگشتهای تولید شده در دست انسان را کنترل کرد، این تصاویر همچنان فشار روانی ایجاد میکردند؛ بهجای خطاهای آناتومیک، صحنههایی با اندامهای فوقالعاده لاغر و زیبا را به تصویر میکشیدند.
«دیدن مکرر این تصاویر هوش مصنوعی، حس عادی بودن من را دوبارهتنظیم کرد»، Ner توضیح داد. «وقتی به انعکاس واقعیام نگاه میکردم، چیزی میدیدم که نیاز به اصلاح داشت».
در یک لحظهٔ بحرانی، Ner شروع به آزمایش با تصاویری کرد که خود را بهعنوان یک مدل مد به تصویر میکشید؛ دستوری که توسط شرکتش که به دنبال کاربران علاقهمند به مد بود، تعیین شده بود. «متوجه شدم که در حال فکر کردن به این هستم که «اگر فقط شبیه نسخهٔ هوش مصنوعیام میبودم»،» او نوشت. «بهشدت وسواسی به کمچربیتر شدن، داشتن بدن بهتر و پوست کامل فکر میکردم».
بهزودی او برای تولید بیوقفه تصاویر، خواب خود را از دست داد؛ این کار را «اعتیادآور» مینامید، چون هر تصویر «یک انفجار کوچک دوپامین» را بهوجود میآورد. اگرچه Ner پیش از ورود به مدلینگ مد هوش مصنوعی بهخوبی اختلال دوقطبی خود را تحت درمان داشت، این وسواس جدید به یک «دورهٔ مانیک دو قطبی» تبدیل شد که او میگوید باعث بروز روانپریشی شد.
«وقتی تصویری هوش مصنوعی از من روی اسب پرنده دیدم، باور کردم که میتوانم واقعاً پرواز کنم»، Ner مینویسد. «صدایها به من گفتند از بالکن بپرسم، احساس اطمینانی به من دادند که میتوانم زنده بمانم. این توهم بزرگنمایی تقریباً مرا به پرش واقعی ترغیب کرد».
خوشبختانه، او خود را متوقف کرد و برای کمک به دوستان و خانواده رجوع کرد. یک متخصص به او کمک کرد تا متوجه شود کارش این مسیر را بهوجود آورده است، که منجر به ترک استارتاپ هوش مصنوعی شد. «اکنون میفهمم که آنچه برایم رخ داد تنها تصادف بیماری روانی و فناوری نبود»، او توضیح میدهد. «این یک نوع اعتیاد دیجیتال بود که ماهها و ماهها تولید تصویر هوش مصنوعی بهوجود آمد».
او پس از آن بهعنوان مدیر در یک شرکت مدرن دیگر به نام PsyMed Ventures منتقل شد؛ شرکتی که Newsweek آن را بهعنوان یک صندوق سرمایهگذاری خطرپذیر که در حوزه سلامت ذهن و مغز سرمایهگذاری میکند، توصیف کرده است. بسیاری از شرکتهای سرمایهگذاری شده توسط PsyMed ابزارهای هوش مصنوعی دارند — که Ner میگوید هنوز هم از آنها استفاده میکند، هرچند با احترامی تازه یافته.
اطلاعات بیشتر درباره هوش مصنوعی:مردی که توصیف میکند چگونه ChatGPT او را مستقیماً به روانپریشی کشاند
در یک صفحهٔ پشتیبانی Google، این شرکت اعلام میکند که گزینهٔ جدیدی برای اجازهٔ تغییر آدرس ایمیل کاربران حتی اگر آدرسشان «@gmail.com» باشد، بهصورت تدریجی در حال اجراست.
مدتی است که Google به کاربران اجازه میدهد آدرس ایمیل حساب خود را در صورت استفاده از آدرس ایمیل شخص ثالث تغییر دهند، اما کاربران دارای آدرس «@gmail.com» نمیتوانستند آن را تغییر دهند؛ همانطور که Google میگوید:
اگر آدرس ایمیل حساب شما با @gmail.com تمام شود، معمولاً نمیتوانید آن را تغییر دهید.
به نظر میرسد این وضعیت در حال تغییر است.
در همان صفحهٔ پشتیبانی که در حال حاضر میگوید معمولاً نمیتوانید ایمیل خود را تغییر دهید، Google فرآیند جدیدی که «بهصورت تدریجی معرفی میشود» را شرح میدهد. صفحهٔ تغییریافته بهطرز عجیبی در حال حاضر فقط به زبان هندی نمایش داده میشود، بنابراین نمیتوانید تغییرات را به انگلیسی ببینید. تمام مطالب زیر ترجمه شدهاند. این صفحه اولین بار در گروه «Google Pixel Hub» در تلگرام مشاهده شد.
Google توضیح میدهد:
آدرس ایمیل مرتبط با حساب Google شما، همان آدرسی است که برای ورود به سرویسهای Google استفاده میکنید. این آدرس ایمیل به شما و دیگران کمک میکند تا حساب شما را شناسایی کنید. اگر مایل باشید، میتوانید آدرس ایمیل حساب Google خود که به gmail.com ختم میشود را به یک آدرس ایمیل جدید که به gmail.com ختم میشود، تغییر دهید.
این عملکرد جدیدی است که Google هنوز جزئیات آن را در جای دیگر منتشر نکرده، اما میگوید که «بهصورت تدریجی برای همه کاربران در دسترس خواهد شد».
با این تغییر، Google به کاربران اجازه میدهد آدرس ایمیل «@gmail.com» خود را به آدرس جدید «@gmail.com» با نام کاربری متفاوت تغییر دهند. پس از تغییر، Google توضیح میدهد که آدرس ایمیل اصلی شما هنوز ایمیلها را در همان صندوق ورودی که آدرس جدید دارد دریافت میکند و برای ورود به سرویسها قابل استفاده است و هیچیک از دسترسیهای حساب شما تغییر نمیکند. کاربران نمیتوانند ایمیل خود را در طول ۱۲ ماه پس از تغییر، تغییر یا حذف کنند.
وقتی آدرس ایمیل حساب Google خود را از ایمیلی که به gmail.com ختم میشود به ایمیل جدیدی که به gmail.com ختم میشود تغییر میدهید:
آدرس ایمیل قدیمی در حساب Google شما که به gmail.com ختم میشود بهعنوان یک نام مستعار (alias) تنظیم میشود. برای اطلاعات بیشتر در مورد نامهای مستعار ایمیل، به صفحه مربوطه مراجعه کنید.
ایمیلها هم به آدرس قدیمی و هم به آدرس جدید شما ارسال میشوند.
دادههای ذخیرهشده در حسابتان، از جمله عکسها، پیامها و ایمیلهای ارسالی به آدرس قدیمی، تحت تأثیر قرار نمیگیرد.
میتوانید هر زمان که بخواهید، آدرس ایمیل قدیمی حساب Google خود را دوباره استفاده کنید. اما نمیتوانید در طول ۱۲ ماه آینده آدرس ایمیلی جدید که به gmail.com ختم میشود ایجاد کنید. همچنین نمیتوانید آدرس ایمیل جدید را حذف کنید.
میتوانید برای ورود به سرویسهای Google مانند Gmail، Maps، YouTube، Google Play یا Drive، از آدرس ایمیل قدیمی یا جدید استفاده کنید.
هر حساب میتواند حداکثر تا ۳ بار آدرس «@gmail.com» خود را تغییر دهد؛ یعنی در مجموع میتواند ۴ آدرس مختلف داشته باشد.
Google همچنین توضیح میدهد که آدرس Gmail قدیمی شما همچنان در برخی موارد نمایش داده میشود و «در نمونههای قدیمیتر» نظیر رویدادهای تقویم که قبل از تغییر ایجاد شدهاند، بلافاصله منعکس نمیشود. شما همچنان میتوانید ایمیلها را از آدرس قدیمی ارسال کنید. آدرس قدیمی هنوز متعلق به شماست و نمیتواند توسط کاربر دیگری استفاده شود.
این بهروزرسانی تنها یک روز پس از آغاز انتشار نسخه FSD v14.2.2 برای مشتریان منتشر شد.
در این کریسمس، تسلا به کارهای شبانه میپردازد و تیم هوش مصنوعی تسلا بهصورت آرام نسخه Full Self-Driving (Supervised) v14.2.2.1 را تنها یکروز پس از آغاز انتشار نسخه FSD v14.2.2 برای مشتریان منتشر میکند.
مالک تسلا بینشهای خود را درباره نسخه FSD v14.2.2.1 به اشتراک میگذارد
مالک طولانیمدت تسلا و آزمونگر FSD @BLKMDL3 پس از چندین رانندگی با نسخه FSD v14.2.2.1 در شرایط بارانی لسآنجلوس، با آب ثابت و خطوط راه کمرنگ، برخی بینشها را بهاشتراک گذاشت. او گزارش داد که هیچ تعلیق یا لرزش در فرمان حس نمیشود، تغییر خطوط با اطمینان انجام میشود و مانورهای دقیق که عملکرد رباتتاکسیهای خودران تسلا در آستین را تداعی میکند، اجرا شد.
عملکرد پارککردن شگفتانگیز بود؛ اکثر مکانها بهدقت کامل، حتی در پیچهای تیز و فشرده، در یکبار و بدون لرزش در فرمان انجام شد. تنها یک انحراف جزئی به دلیل خودروی دیگری که از خط پارک عبور کرده بود رخ داد که FSD با افزودن چند اینچ این فاصله را جبران کرد. در بارانی که معمولاً علائم جاده را از بین میبرد، FSD خطوط راه و مسیرهای پیچ را بهتر از انسانها تجسم کرد و هنگام ورود به خیابانهای جدید بهطور بینقص موقعیت خود را تنظیم کرد.
« امشب مسیر تاریک، مرطوب و پیچدار یک دره کوهستانی را بالا و پایین طی کردم و همانطور که انتظار میرفت، خیلی خوب پیش رفت. در خط مسیر مرکز ماند، سرعت را بهخوبی حفظ کرد و حس فرماندهیای که اعتماد بهنفس میبخشد، ارائه داد؛ اینجوری که این جادههای پیچدار را بهتر از اکثر رانندگان انسانی مدیریت میکند.» صاحب تسلا در پستی در X نوشت.
همینطور، بهروزرسانی دیگری از FSD. نسخه ۱۴.۲.۲.۱ در حال دانلود است! pic.twitter.com/ajh1mu0TEK— Greggertruck (@greggertruck) ۲۴ دسامبر ۲۰۲۵
۵ رانندگی با FSD v14.2.2.1 انجام دادم و اینها نظرات من هستند:
هنوز هیچ تعلیق یا لرزش در فرمان ندارم، تغییر خطوط با اطمینان و عالی است. تمام رانندگیهای امشب من با این نسخه در باران بوده و از عملکرد آن در مواجهه با آب ثابت روی جاده بسیار تحت تأثیر قرار گرفتم… pic.twitter.com/W6RwqnnChe— Zack (@BLKMDL3) ۲۴ دسامبر ۲۰۲۵
خبر خوب 🚨 $TSLA FSD V14.2.2.1 هماکنون در حال انتشار است 💥
این نسخه نگهداری برای اصلاح ویژگیهای موجود در ۱۴.۲.۲ است 🔥 سرعت انتشار این بهروزرسانی از زمان شروع سری v14 بهصورت شگفتانگیزی سریع بوده است 🔥
۱️⃣ V14.1 (2025.32.8.5) — ۶ اکتبر ۲۰۲۵ ۲️⃣ V14.1.1 (2025.32.8.6) — ۱۲ اکتبر ۲۰۲۵… pic.twitter.com/cdhioquSU8— Ming (@tslaming) ۲۴ دسامبر ۲۰۲۵
بهروزرسانی FSD v14.2.2 تسلا
یک روز پیش از انتشار نسخه FSD v14.2.2.1، تسلا نسخه FSD v14.2.2 را منتشر کرد که بر عملکرد واقعی نرمتر، آگاهی بهتر از موانع و مسیر دقیقتری در انتهای سفر متمرکز بود. بر اساس یادداشتهای انتشار این بهروزرسانی، FSD v14.2.2 شبکه عصبی انکودر بینایی را با ویژگیهای با وضوح بالاتر ارتقا میدهد و تشخیص وسایل نقلیه اضطراری، موانع جادهای و اشارات انسانی را بهبود میبخشد.
گزینههای جدید Arrival Options نیز به کاربران اجازه میدهد سبکهای دلخواه تحویل را انتخاب کنند، مانند پارکینگ، خیابان، راهپایانی، گاراژ پارک یا لبهخیابان، بهطوری که پن مکانیابی بهصورت خودکار به نقطهٔ ایدهآل تنظیم شود. سایر بهبودها شامل توقف برای وسایل نقلیه اضطراری، مسیرهای دوربری بر پایهٔ تصویر برای جادههای مسدود، مدیریت بهتر دروازهها و ماندهماندهها، و پروفایلهای سرعت برای تنظیم سبک رانندگی است.
در اینجا رویکردی مستدل برای بهینهسازی کلیدواژهها ارائه میشود که شفافیت، ساختار و تجربه واقعی کاربر را در اولویت قرار میدهد.
در این هفته در بخش «سؤال از سئو»، بری میپرسد:
«حد بین پر کردن کلیدواژه و بهینهسازی چیست؟ آیا قانونی جادویی وجود دارد که تعیین کند چهقدر باید کلیدواژه اصلی و کلیدواژههای مرتبط را در یک صفحهٔ ۲٬۰۰۰ واژهای به کار برد؟ آیا کلیدواژه اصلی باید هم در سرفصلها و هم در متن همان بخش حضور داشته باشد؟»
سؤال عالی!
هیچ چیزی به نام «بهینهسازی شده» در رابطه با کلیدواژهها و تکرارها وجود ندارد. این وضعیت مشابه ارزیابی «اعتبار» دامنههاست. امتیازهای بهینهسازی که دریافت میکنید، معیاری هستند که بر پایهٔ تصور ابزارهای سئو از اعتمادپذیری یک دامنه ساخته شدهاند و نه بر اساس موتورهای جستجو یا سیستمهای هوش مصنوعی. ایدهٔ نیاز به تکرار کلیدواژه از مفهومی به نام چگالی کلیدواژه (keyword density) برمیآید که خود نتیجهٔ ابزارهای سئو است.
هر ابزار روشی متفاوت برای تشخیص اینکه آیا یک واژه یا عبارت به اندازهٔ کافی تکرار شده است تا «سئو‑دوست» شود، دارد؛ و چون افراد به این ابزارها اعتماد میکنند، این رویکرد را بهعنوان یک فاکتور یا سیگنال معتبر رتبهبندی برای موتور جستجو میپذیرند. این بدان معنا نیست که موتورهای جستجو به تعداد دفعات حضور یک واژه در صفحه یا پاراگراف توجه نمیکنند؛ بلکه چنین تکرارهای بیش از حد تجربهٔ کاربری خوبی ایجاد نمیکند.
الگوریتم پاندا توانایی محتوای کمکیفیت با پر کردن بیش از حد کلیدواژهها را کاهش داد و پیشرفتهای بعدی گوگل، برت (BERT) و موم (MUM)، امکان درک بهتر زمینه، روابط بین واژگان و ساختار کلی صفحه را فراهم کردند. امروزه گوگل بسیار بهتر از پیش میتواند معنای محتوا را بدون نیاز به کلیدواژههای دقیقاً یکسان تکرار شده، تفسیر کند.
با این حال، کلیدواژهها مهم هستند.
کلیدواژهها به موتور جستجو سیگنالی میفرستند که موضوع صفحه چیست. آنها میتوانند در سرفصلها، درون متن، بهعنوان لینکهای داخلی، در تگهای عنوان، اسکیما و ساختار URL به کار روند. اما نگران بودن دربارهٔ استفاده از کلیدواژه برای مقاصد سئو میتواند مشکلاتی ایجاد کند. بنابراین، بیایید تعریف پر کردن کلیدواژه را برای این مطلب بیان کنیم.
پر کردن کلیدواژه به وضعیتی اطلاق میشود که شما یک کلیدواژه یا عبارت کلیدواژهای را صرفاً به منظور سئو، در محتوا، سرفصلها و آدرسها تحمیل میکنید.
با تحمیل یک کلیدواژه به محتوا یا سرفصلها، تجربه کاربری را تحت تأثیر قرار میدهید. گرچه موتور جستجو میتواند هدف رتبهبندی شما را تشخیص دهد، اما زبان محتوا طبیعی به نظر نخواهد رسید. به جای نگرانی دربارهٔ تعداد دفعات استفاده از کلیدواژه، به معادلهای آن و راههای دیگر بیان مطلب که برای خواننده آسان باشد، فکر کنید. بسیاری از موتورهای جستجو بهطور پیوسته توانایی درک روابط بین موضوعات، واژگان، جملات و عبارات را بهبود میبخشند. دیگر نیازی به تکرار مداوم یک واژه نیست.
اگر واژهٔ «مجموعه شنا» را در گوگل جستجو کنید، در چند تگ عنوان ممکن است این واژه را ببینید، اما همچنین واژهٔ «لباس شنا» ظاهر میشود. اگر بهجای آن «بست شنا» را وارد کنید، شاید در تعداد زیادی از تگهای عنوان مشاهده نشود؛ اما تگها بهجای آن از «لباس شنا» و سایر مترادفها استفاده میکنند، هرچند «بست شنا» نیز نام رایجی برای همان محصول است.
حالا عبارت «آرایشگر نزدیک من» را امتحان کنید؛ احتمالاً واژهٔ «آرایشگر» در اکثر نتایج ظاهر نمیشود، اما «سالن مو» و مشاغل مشابه را میبینید. این به این دلیل است که موتورهای جستجو بهجای ارائهٔ فهرست کلیدواژهها، راهحلهای مشکل کاربران را ارائه میدهند؛ اگر صفحه راهحل را داشته باشد، نیازی به تکرار مکرر کلیدواژهها نیست.
بهعنوان مثال، بهجای گفتن «پر کردن کلیدواژه» در این مطلب، میتوانم بگویم «استفادهٔ بیش از حد عبارات برای سئو». معنای دو عبارت یکسان است. اگر بهطور مکرر از «پر کردن کلیدواژه» استفاده کنم، خوانندگان این ستون بهسرعت خسته میشوند؛ با تنوعبخشی میتوانم علاقهٔ آنها را حفظ کنم و موتورهای جستجو همچنان قادر به تشخیص این مفهوم مشابه هستند. این نکته نیز به تگهای سرفصل اعمال میشود.
شواهد قطعی برای این ادعا ندارم، اما به نظر میرسد که این روش برای مشتریان ما و محتوای تولیدیمان مؤثر باشد و بیش از ده سال است که بهخوبی کار میکند. اگر عبارت کلیدواژهٔ اصلی در تگ H1 باشد، چه بهعنوان آیتم منو و چه بهعنوان پست وبلاگ، نیازی به قراردادن آن در H2، H3 و غیره نداریم. اگر کلیدواژه بهصورت طبیعی در متن ظاهر شود، مشکلی ندارم؛ چرا که این امر تجربه کاربری (UX) خوبی ایجاد میکند.
نظریهای که در اینجا مطرح میشود این است که سرفصلها تم و موضوع را به بخشهای زیرین منتقل میکنند. اگر سرفصل سطح بالا شامل واژهٔ «آبی» باشد، فرض میکنم تم «آبی» در سراسر صفحه جاری باشد و به تگ H2 نیز اعمال شود، چرا که H2 زیرموضوع «آبی» است. «H2»های مرتبط با آبی میتوانند «تیشرتها» و «شلوارکها» باشند.
اگر این درست باشد، با داشتن H1 بهعنوان «آبی» و H2 بهعنوان «شلوارک»، موتور جستجو میداند که اینها «شلوارکهای آبی» هستند و من بهاطمینان کامل اینگونه فکر میکنم که کاربران نیز همینطور خواهند دانست. آنها بر روی «آبی» کلیک میکنند یا صفحه نتایج جستجو برای لباسهای آبی را میبینند و سپس از منو یا اسکرول به «شلوارک» دسترسی پیدا میکنند.
اگر واژهٔ «آبی» را در هر لینک و سرفصل تکرار کنید، برای کاربر خستهکننده میشود. اما بسیاری از سایتهای مورد جریمه، عناوین «شلوارک کارگو آبی»، «شلوارک چینی آبی»، «شلوارک ورزشی آبی» و… دارند. بهتر است فقط به سبکهای شلوارک مانند «کارگو» یا «چینی» اشاره کنیم؛ زیرا موتورهای جستجو احتمالاً از طریق تگ H بالاتر میدانند این شلوارکها آبی هستند. همچنین بخش «آبی» احتمالاً در مسیرهای ناوبری (breadcrumbs)، ساختار سایت، توصیف محصولات و غیره گنجانده شده است.
یکی از کارهایی که قطعاً نباید انجام دهید، داشتن میلیونها لینک در فوتر است که با ناوبری سازگار هستند یا پر از کلیدواژههای تکراری میباشند. این روش زمانی مؤثر بود، اما امروز صرفاً بهعنوان هرزنامه شناخته میشود. این کار به کاربر کمکی نمیکند؛ برای موتورهای جستجو واضح است که هدف سئو است. سایتهایی که کلیدواژهها را پر میکنند، معمولاً از این تاکتیکهای قدیمی نیز استفاده میکنند؛ به همین دلیل این نکته را در اینجا هم ذکر میکنم.
امیدوارم این توضیح به سؤال شما دربارهٔ استفادهٔ بیش از حد از موضوعات یا عبارات خاص پاسخ دهد. این کار فقط ابزار سئو را راضی میکند؛ به این معنی نیست که تجربه کاربری خوبی برای کاربران یا موتورهای جستجو فراهم میکنید. اگر بر نوشتن برای مصرفکنندهتان تمرکز کنید و کلیدواژه یا عبارت را بهطور طبیعی در متن بگنجانید، احتمالاً پاداش مثبت دریافت خواهید کرد.
منابع بیشتر:
چرا تحقیق کلیدواژه برای سئو مفید است و چگونه میتوان رتبه گرفت
سؤال از سئوکار: آیا باید برای کلیدواژههای با حجم جستجوی بالا یا رقابتپذیر بهینهسازی کنیم؟
به تازگی یک آیفون جدید خریدم. نیازی به داشتن نسخه جدیدتر نداشتم، اما گوشی قبلیام بهگونهای خراب شده بود که به سادگی قابل تعمیر نبود؛ پس ناچار شدم به چرخه سخت برنامهریزی برای کهنهشدن بپیوندم. من همیشه از بهبود مستمر کیفیت تصویر خوشحالم. در غیر اینصورت، برای من فقط نیاز به یک گوشی جدید و بدون آسیب بود. اما این یکی از مدلهایی است که اپل بارها به شما میگوید هوش مصنوعی خود را در دستگاه تعبیه کرده است—چیزی که میگویند فوقالعاده است. یا همانطور که آنها میگویند. بهطور مکرر. و حس کلی من این است که اپل نسبت به دیگر غولهای فناوری، کمترین تمایل به پرستارهسازی و اغراق در این زمینه را دارد.
از وقتی که از گوشی جدید استفاده میکنم، دریافتم که برنامه پیامرسانی اپل حالا پیشنهادهای عبارت و تکمیل کلمات را به سطحی بالاتر میبرد — بهگونهای که میتوان گفت به حدی تقریباً بیمنطق رسیده است.