نوشته رامیشا ماروف
نیویورک —

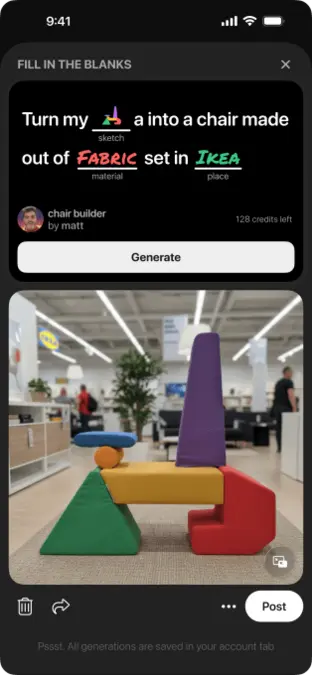
آبیگل وندلینگ، ۲۳ ساله، از پینترست برای جمعآوری همه چیزهای زندگیاش استفاده میکند؛ از دستورهای آشپزی تا تصویرهای زمینه. این تا زمانی که برای یافتن تصویر زمینه، یک گربهٔ یکچشمی را دید. در مثال دیگر، جستجوی دستورات سالم تصویری معماگونه نشان داد که برشیکتکهٔ مرغ پخته با ادویههای پاشیده داخل آن را به نمایش میآورد.
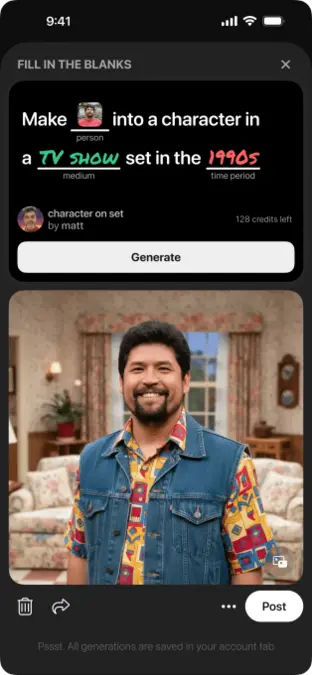
این پستها توسط هوش مصنوعی مولد ساخته شدهاند که بهسرعت در حال تسلط بر این پلتفرم متمرکز بر تصاویر است. پینترست، همانند سایر شبکههای اجتماعی، از زمان عرضهٔ ابزار تولید ویدئو Sora از ChatGPT در سال ۲۰۲۴ با سیل محتوای ضعیف هوش مصنوعی مواجه شده است. این شرکت اقدامات پیشگیرانهای برای محدود کردن این محتوا برای کاربرانی که نمیخواهند، انجام داده است.
اما حضور هوش مصنوعی مولد، در جامعهٔ خلاق پینترست جرقهای روشن کرده است؛ کاربران به سیانن گفتند که احساس میکنند صدا شنیده نمیشود، در حالی که مدیران ارشد شرکت بهطور کامل بر این فناوری نوظهور تمرکز کردهاند.
«این باعث میشود که بخواهم گوشیام را بگذارم و کاری دیگر انجام دهم»، گفت وندلینگ که علاوه بر اینستاگرام و تیکتوک نیز از پینترست استفاده میکند. «من میگویم پینترست بیشترین عکسها و ویدیوهای تولیدشده توسط هوش مصنوعی را نسبت به سایر برنامههای رسانههای اجتماعی که در حال حاضر استفاده میکنم، دارد… حالا مجبورم همه چیز را با میکروسکوپ دقیق بررسی کنم.»
پذیرش سرسختانه هوش مصنوعی از اولویتهای اصلی برای بیل ردی، مدیرعامل پینترست که در سال ۲۰۲۲ شرکت را بر عهده گرفت، بوده است. این رهبر پیشین ویندمو و برینتری، پینترست را در آخرین تماس گزارش درآمد این ماه از «پلتفرمی برای نگاهداری» به «دستیار خرید بصری مبتنی بر هوش مصنوعی» تبدیل کرده است. و تنها نیست: پینترست بههمراه گوگل، اوپنایآی و آمازون، در تلاش برای بازسازی تجربهٔ خرید آنلاین با هوش مصنوعی میپیوندد.

پینترست ۶۰۰ میلیون کاربر فعال ماهانهٔ جهانی داشته است که نیمی از آنها نسل Z هستند و بسیاری از آنها برای الهامگیری خرید از این پلتفرم استفاده میکنند. درآمد سهماههٔ اخیر این شرکت ۱ میلیارد دلار بوده که نسبت به سال گذشته ۱۷٪ رشد داشته است.
هوش مصنوعی، فناوریای که درهٔ سیلیکون بهسرعت برای انطباق و کسب درآمد از آن میجنگد، در «قلب تجربهٔ پینترست» قرار دارد، او گفت.
این به معنای استرس برای کاربران پینترست است که در تلاش برای عبور از محتوای ضعیف هوش مصنوعی، مواجه با تبلیغات بیشتر و دسترسی به محتوای کمتر مورد نظر خود در این پلتفرم هستند، کاربران به سیانن گفتند.
«من میخواهم هنرهایی را ببینم که یک انسان زمان و تلاش خود را صرف خلقشان کرده است، نه تصاویری که توسط کسی که چند کلمه را در یک مولد تصویر وارد کرده، به شکل زبالهای بیرون ریخته میشود»، آمبر تورمن، کاربر ۴۱ سالهٔ پینترست از ایلینویس، به سیانن گفت.
پینترست به یک برنامه خرید هوش مصنوعی تبدیل میشود
پینترست زمانی بهعنوان پناهگاهی برای فرار از نظرات پرسرعت در تیکتوک، بهروزرسانیهای زندگی همکلاسیهای پیشین در اینستاگرام و مشاجرهٔ خویشاوندان دربارهٔ سیاست در فیسبوک عمل میکرد.
بنیانگذار بن سیلبرمن در سال ۲۰۱۹ به سیانن گفت که هدف اصلی این پلتفرم الهامبخشی به کاربران است. کاربران تختههای حسی (Mood Boards) را جمعآوری میکردند و دستورهای کوکی را سنجاق میکردند. خالقان و هنرمندان به این برنامه میآمدند تا الهام واقعی برای طراحی پیدا کنند.

اما در سال ۲۰۲۵، غولهای فناوری در حال مسابقه برای بهرهبرداری از فناوریای هستند که برخی آن را بهقدر تأثیرات تلفن هوشمند یا اینترنت میدانند. این شامل یافتن روشهای نوین برای کسب درآمد نیز میشود. بهعنوان مثال، Meta که از هوش مصنوعی استفاده میکند، بهزودی شروع به استفاده از گفتگوهای کاربران با دستیار هوش مصنوعی خود برای هدفگذاری تبلیغات خواهد کرد.
برای پینترست، آیندهاش به خرید مبتنی بر هوش مصنوعی وابسته است. الگوریتم این برنامه محصولات را بر پایهٔ جستجوهای کاربران در اپ شناسایی میکند.
در سهماههٔ اخیر، تعداد افرادی که روی لینکهای تبلیغدهندگان کلیک میکردند، نسبت به سال قبل ۴۰٪ رشد داشته و در سه سال گذشته بیش از پنج برابر افزایش یافته است، طبق گزارشهای مالی. این شرکت با معرفی ویژگیهای هوش مصنوعی بیشتر، از جمله یک دستیار خرید که کاربران میتوانند با آن گفتگو کنند و نقش «دوست صمیمی» را ایفا میکند، این سرعت را دوچندان میکند.
ناراحتی کاربران
با این وجود، برخی از کاربران قدیمی، پینترست را بهعنوان یک تبلیغ خرید نپذیرفتهاند.
هیلی کول، کارگردان خلاق ۳۱ سالهای از کالیفرنیا، بهتازگی برای الهامگیری طراحی از رقیب پینترست، Cosmos، استفاده میکند. او گفت که هرگز از این پلتفرم خریدی انجام نداده و نگران است که محتوای هوش مصنوعی پینترست ممکن است مالکیت فکری را سرقت کند، همانطور که برای خود او اتفاق افتاده است. طبق سیاست پینترست، حسابهای کاربری که بهطور مکرر حقوق کپیرایت یا مالکیت فکری را نقض میکنند، حذف خواهد شد.
محتوای ضعیف هوش مصنوعی همچنان ادامه دارد
کاربران مجبورند «همزمان با محتوای ضعیف هوش مصنوعی و فناوریهای جدید زندگی کنند» که شرکتها در تلاش برای کسب درآمد از این فناوری هستند، خوزه ماریچال، استاد علوم سیاسی در دانشگاه کالج لوتری کالیفرنیا، به سیانن گفت.
مدیران پینترست قطعاً همانطور هستند.
بهتدریج، هوش مصنوعی مسیر مشابهی به فتوشاپ خواهد پیمود، بیل ردی گفت. او افزود: «تقریباً هر محتوایی که میبینید، حداقل بهصورت یا بهنحوئی توسط هوش مصنوعی ویرایش شده است.»
اما این رویکرد میتواند حس اصیل که در ابتدا کاربران را به این پلتفرم جذب میکرد، به خطر بیندازد.
پستهای تولیدشده توسط هوش مصنوعی اغلب به وبسایتهای خارجی منجر میشوند که از بازاریابی وابسته سود میبرند، کیسی فیزلر، استادیار علوم اطلاعات در دانشگاه کلرادو بولدر، به سیانن گفت.
بهعنوان مثال، یکی از اولین نتایج جستجو برای «دستور کوکی چیپس شکلاتی» در پینترست، به عکسی از دسر منجر شد. این پست به سایتی دیگر که مملو از تبلیغات بود و تصویر یک سرآشپز تولیدشده توسط هوش مصنوعی داشت، لینک میداد. خود دستور غذا تقریباً بهطور کامل با پرسوجوی ChatGPT برای «بهترین دستور کوکی چیپس شکلاتی دنیا» مطابقت داشت.
در یک سایت رسانهٔ اجتماعی مبتنی بر الگوریتم، تنها چیزی که کاربران میتوانند کنترل کنند، تعامل خودشان با محتوای هوش مصنوعی است. حتی گذاشتن یک نظر نفرتآمیز یا ارسال آن بهعنوان شوخی به یک دوست میتواند به الگوریتم بگوید که میخواهید محتوای بیشتری از این نوع ببینید، فیزلر افزود.