تیم کارمندان سابق گوگل که پیش از این اپلیکیشن طراحی سهبعدی Rooms را در شرکت Things, Inc. ساخته بودند، اکنون جدیدترین پروژهی خود را عرضه کردهاند: یک ویرایشگر عکس سرگرمکننده و مبتنی بر هوش مصنوعی به نام Mixup. این اپلیکیشن که فقط برای iOS در دسترس است، به کاربران اجازه میدهد با استفاده از «دستورالعملها» (recipes)، تصاویر جدیدی با هوش مصنوعی بسازند. این دستورالعملها در واقع قالبهایی شبیه بازی کاملکردن جملات هستند که میتوانید جاهای خالی آنها را با عکس، متن یا نقاشیهای سادهی خود پر کنید.
برای مثال، میتوانید از Mixup بخواهید یک طرح ساده و خطخطی شما را به یک نقاشی باشکوه رنسانسی تبدیل کند یا حیوان خانگیتان را در یک لباس بامزهی هالووین تصور کند. همچنین میتوانید با استفاده از یک سلفی ببینید که با مدل موی متفاوت چه شکلی میشوید، یا حتی کارهای عجیبوغریبتری انجام دهید؛ مثلاً تصور کنید دوستتان به یک شخصیت بامزه و عجیب تبدیل شده است.

این اپلیکیشن بر پایهی مدل هوش مصنوعی Nano Banana گوگل ساخته شده، اما فرمت «دستورالعمل» آن روشی جدید برای تعامل با این مدل ارائه میدهد و یک ابزار تولیدی را به یک بازی گروهی آنلاین تبدیل میکند.
جیسون تاف، بنیانگذار و مدیرعامل شرکت Things, Inc.، که سابقهی کار روی اپلیکیشنهای آزمایشی در شرکتهای بزرگ فناوری مانند گوگل و متا و همچنین مدیریت محصول در توییتر را در کارنامه دارد، میگوید: «ویژگی منحصربهفرد Nano Banana که هیچ مدل دیگری پیش از آن نداشت، این بود که میتوانست تصویر شما را به شیوهای باورپذیر و بدون ایجاد حسی ناخوشایند حفظ کند.»
اما چیزی که Mixup را بهطور ویژه سرگرمکننده میکند، قابلیت اشتراکگذاری «دستورالعملها» یا همان دستورهای هوش مصنوعی است که توسط کاربران ساخته میشوند.

تاف با اشاره به نقاط ضعف موجود در فضای هوش مصنوعی فعلی میگوید: «هوش مصنوعی مولد بسیار قدرتمند است، اما اغلب وقتی به سراغ این ابزارها میروید، با یک کادر متنی خالی مواجه میشوید که از شما میخواهد چیزی خلاقانه بنویسید. واقعاً چه چیزی باید نوشت؟»
او ادامه میدهد: «بنابراین، به جای اینکه مجبور باشید خلاقیت به خرج دهید و فکر کنید چه چیزی بسازید، میتوانید چیزی را ببینید که قبلاً نتیجهبخش بوده و فقط جاهای خالی آن را پر کنید.»
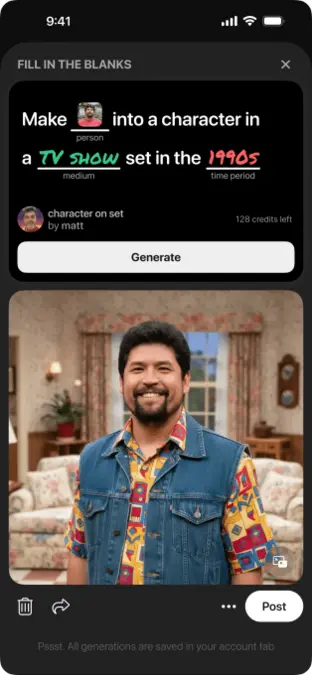
پس از اینکه کاربران یک دستور جدید در Mixup ایجاد کردند، میتوانند انتخاب کنند که آن را به همراه تصویر حاصل در یک فید عمومی منتشر کرده یا فقط برای استفادهی شخصی دانلود کنند. سایر کاربران میتوانند از طریق فید، تصویر را مشاهده کرده و با زدن دکمهی کنار آن، «این دستورالعمل را امتحان کن»، از همان دستور برای تولید تصویر با استفاده از عکس، متن یا طراحیهای خودشان استفاده کنند. (طراحیها را میتوان از طریق یک ابزار سادهی نقاشی در خود اپلیکیشن انجام داد.)
تیم سازنده معتقد است که دیدن همزمان یک تصویر و دستورالعملی که آن را ساخته، میتواند به رفع ماهیت غیرقابلپیشبینی تصاویر هوش مصنوعی مولد کمک کند.
تاف توضیح میدهد: «مشکل دیگر [هوش مصنوعی مولد] چیزی است که ما در داخل شرکت به آن «مشکل ماشین اسلات» میگفتیم؛ یعنی شما دکمه را فشار میدهید، یک خروجی میگیرید، دوباره آن را فشار میدهید و خروجی متفاوتی دریافت میکنید و احساس میکنید که هیچ کنترلی روی نتیجه ندارید.»

اما در Mixup، کاربران میتوانند هم تصویر و هم دستوری که آن را ایجاد کرده در یک جا ببینند و این به آنها ایدهای از نتیجهی نهایی میدهد. همچنین اگر سازندهی اصلی این گزینه را فعال گذاشته باشد، کاربران میتوانند با یک دکمه تصویر قبل و بعد را مشاهده کنند.
علاوه بر این، مشابه اپلیکیشن ویدیویی هوش مصنوعی Sora از شرکت OpenAI، کاربران میتوانند عکسهای خود را برای استفاده در تصاویر هوش مصنوعی در Mixup آپلود کنند. اگر این کار را انجام دهید، هر کسی که شما را در اپلیکیشن دنبال میکند نیز میتواند با استفاده از تصویر شما، تصاویر هوش مصنوعی بسازد؛ این ویژگی «میکساِبِلها» (mixables) نام دارد.
شرکت سازنده تصور میکند که گروههای دوستانه برای استفاده از این ویژگی یکدیگر را دنبال خواهند کرد، اما این امکان نیز وجود دارد که گروهی از تولیدکنندگان محتوا در این پلتفرم ظهور کنند؛ البته اگر با دیدن تصاویر عجیب و غریب از خودشان مشکلی نداشته باشند. (طبیعتاً اگر نمیخواهید تصویرتان در دسترس دیگران باشد، یا آن را آپلود نکنید یا کسی را دنبال نکنید.)

این اپلیکیشن همچنین از فناوری OpenAI برای مدیریت برخی نگرانیهای رایج مربوط به نظارت بر محتوای تصاویر هوش مصنوعی استفاده میکند، اما تاف اعتراف میکند که Mixup بهشدت به کنترلهای داخلی مدل تصویر گوگل برای محدود کردن مواردی مانند محتوای جنسی یا خشونتآمیز متکی است.
در زمان عرضه، Mixup برای iOS 26 بهینهسازی شده است اما از iOS 18 و بالاتر نیز پشتیبانی میکند. اگر این اپلیکیشن با استقبال مواجه شود، ممکن است در آینده نسخهی وب یا اپلیکیشن اندروید آن نیز اضافه شود.
کاربران رایگان ۱۰۰ اعتبار دریافت میکنند که معادل ۴ دلار است. در همین حال، تولید هر تصویر حدود ۴ سنت هزینه دارد. پس از اتمام اعتبار، کاربران میتوانند در طرحهای مختلف با ۱۰۰، ۲۵۰ یا ۵۰۰ اعتبار ماهانه مشترک شوند.
این اپلیکیشن در تاریخ ۲۱ نوامبر در اپ استور به صورت جهانی عرضه میشود، اما برای ورود به آن به دعوتنامه نیاز است. خوانندگان تککرانچ میتوانند از کد TCHCRH (تا زمانی که ظرفیت آن تمام نشده) برای ورود استفاده کنند. Mixup پیش از عرضه برای پیشخرید در دسترس است.
این مطلب پس از انتشار بهروزرسانی شد تا مشخص شود که اپلیکیشن در تاریخ ۲۱ نوامبر عرضه میشود، نه ۲۰ نوامبر که قبلاً اعلام شده بود.